Stack Overflow купили за $1,8 млрд, а потом трафик упал почти до нуля
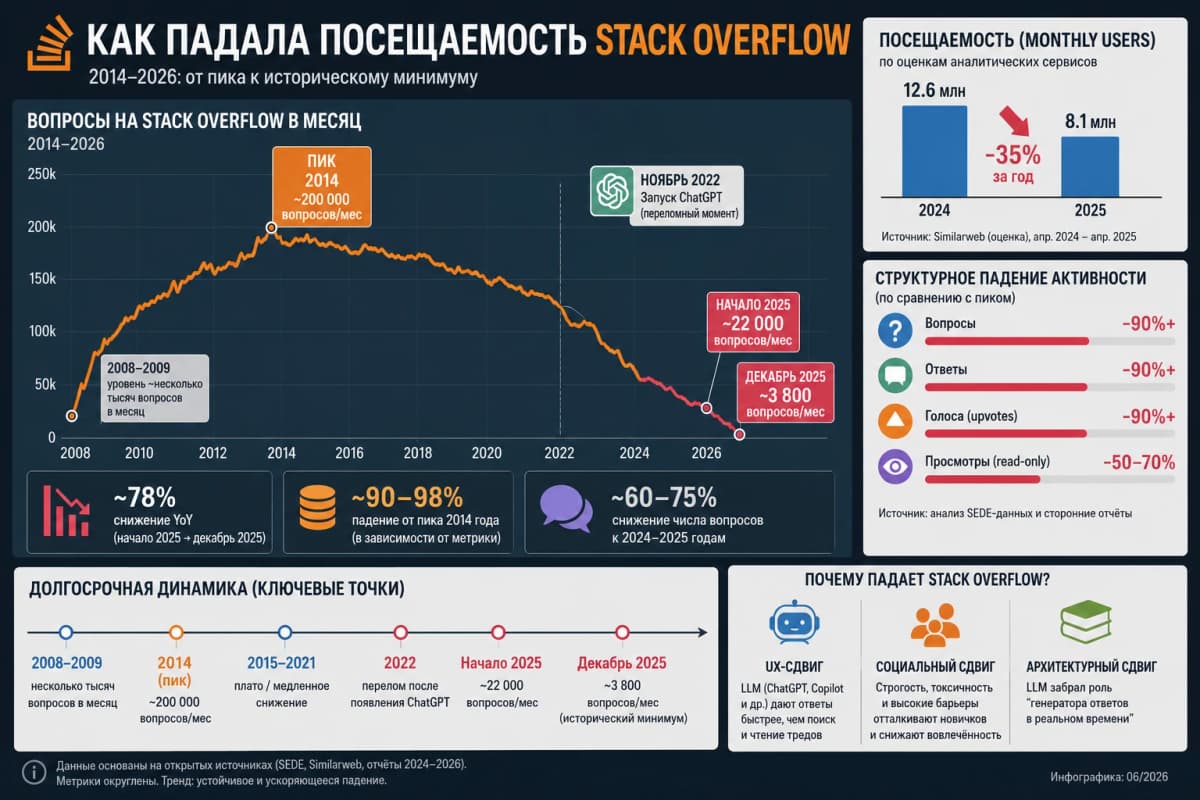
Stack Overflow когда-то был главным местом, где разработчик мог получить работающий ответ на конкретный вопрос по коду, и этот ресурс терял аудиторию ещё до появления ChatGPT, а теперь его посещаемость, по словам автора исходного материала, «упала практически до нуля».
Stack Overflow показал, что целая категория сайтов «вопрос и ответ» уступила место диалогу с LLM (большой языковой моделью, то есть нейросетью, которая генерирует текст). Для тех, кто работает с контентом или кодом в РФ, это не абстрактная история, а готовый сценарий: если ваш продукт строится на базе знаний, которую ИИ может заменить диалогом, пора менять модель.
Ресурс запустили Джефф Этвуд и Джоел Спольски в 2008 году. Модель была простой: пользователь задаёт вопрос, другие пользователи дают ответы, система репутации поднимает лучшие решения наверх. Ни флуда, ни философии, только инженерные знания в удобном формате. В июне 2021 года инвестиционный холдинг Prosus купил Stack Overflow за 1,8 миллиарда долларов, хотя пик популярности к тому моменту уже прошёл.
Почему Stack Overflow сдал позиции ещё до ИИ?
К середине 2010-х годов база вопросов на Stack Overflow стала настолько полной, что новичку было проще загуглить код ошибки, чем задавать вопрос. А если кто-то всё же спрашивал, сообщество нередко встречало его жёстко: тема закрыта, пользуйтесь поиском.
Строгая модерация защищала качество базы, но убивала дух сообщества. Параллельно росло качество документации, появлялся контент на YouTube и других ресурсах, а GitHub обогатился сервисами и тоже стал источником ответов.
Что произошло после появления ChatGPT?
Люди перестали задавать вопросы другим людям. Вместо того чтобы искать ответ на Stack Overflow, разработчик просто спрашивал LLM (большую языковую модель) в чате и получал код за секунды.
Похожая судьба постигла все площадки формата «вопрос и ответ»: Quora, Yahoo! Answers, Expert Exchange, «Ответы Mail.ru». Модель себя исчерпала, а ИИ поставил в этой истории точку.
Ситуацию усугубила волна ИИ-генерированного контента. Ранние энтузиасты копировали ответы LLM на Stack Overflow, модераторам приходилось разгребать этот поток вручную. В мае 2023 года руководство Stack Exchange запретило использовать детекторы ИИ-контента при модерации, опасаясь ложных срабатываний и конфликтов с реальными пользователями. 11% добровольных модераторов в ответ объявили забастовку.
Что понадобится
Если вы хотите перестроить свой рабочий процесс так, чтобы не зависеть от умирающих баз знаний:
- Доступ к любой LLM с возможностью писать промпты (промпт, это текстовый запрос, который вы отправляете нейросети): ChatGPT, Claude, GigaChat, YandexGPT
- Базовое понимание, какую задачу вы решаете: отладка кода, поиск решения, генерация шаблона
- 10 минут на первую пробу вместо привычного поиска на Stack Overflow
Пошаговая инструкция: как заменить поиск на Stack Overflow диалогом с ИИ
-
Сформулируйте вопрос так, как вы бы задали его на Stack Overflow. Конкретный код ошибки, язык программирования, версия библиотеки. Чем точнее, тем лучше.
-
Превратите вопрос в промпт с контекстом. Добавьте роль, ограничения, формат ответа:
Ты опытный Python-разработчик. Я получаю ошибку
"TypeError: 'NoneType' object is not subscriptable"
при обращении к response["data"] после запроса к API.
Версия Python 3.11, библиотека requests 2.31.
Покажи причину и рабочий фикс с проверкой на None.
-
Проверьте ответ, не доверяйте слепо. LLM может выдать галлюцинацию (когда нейросеть уверенно генерирует то, чего не существует): несуществующий метод, устаревший синтаксис. Скопируйте ключевые фрагменты и проверьте в документации.
-
Итерируйте в диалоге. Если ответ не подошёл, уточните: «этот метод не работает в версии 2.0, предложи альтернативу». На Stack Overflow вам бы пришлось ждать ответа часы, здесь вы получаете его за секунды.
-
Сохраните рабочее решение. Заведите личную базу: Notion, Obsidian, текстовый файл. Stack Overflow хранил знания за вас, теперь это ваша ответственность.
Задача: выяснить, почему скрипт на Python падает при парсинге JSON из API.
Промпт:
Я отправляю GET-запрос к API и получаю ответ 200,
но json.loads(response.text) выбрасывает JSONDecodeError.
Вот первые 200 символов response.text: "<!DOCTYPE html>..."
Объясни причину и покажи, как правильно обработать такой случай.
Результат: LLM сразу указала, что сервер вернул HTML-страницу (вероятно, редирект или ошибку авторизации), а не JSON, и предложила проверять заголовок Content-Type перед парсингом. На Stack Overflow аналогичный вопрос нашёлся бы, но пришлось бы перебрать три-четыре ответа разных лет, прежде чем понять, какой актуален для текущей версии библиотеки.
- Слепое копирование кода из LLM. Нейросеть не проверяет код на вашей машине. Метод может быть устаревшим, а библиотека может называться иначе в свежей версии. Всегда запускайте и тестируйте.
- Слишком общий промпт. «Почему не работает код» без указания языка, версии и текста ошибки даст расплывчатый ответ, ровно как и вопрос без деталей на Stack Overflow закрывали с пометкой «недостаточно информации».
- Потеря контекста в длинном диалоге. После 10-15 сообщений LLM может «забыть» начальные условия. Повторите ключевые параметры или начните новый чат.
- Игнорирование документации. LLM обучена на данных до определённой даты. Если вы работаете с библиотекой, обновлённой на прошлой неделе, ответ может быть неверным. Официальная документация остаётся финальным арбитром.
Что делать с этим прямо сейчас, по ролям
Разработчику (не только профессионалу, но и автору Дзена, который пишет скрипты для автоматизации): перестаньте открывать Stack Overflow по привычке. Попробуйте неделю решать все кодовые вопросы через диалог с LLM и фиксировать, где ответ оказался точным, а где пришлось проверять. Это покажет границы инструмента лично для вас.
Маркетологу и контент-менеджеру: история Stack Overflow, это предупреждение. Если ваш продукт или медиа строится на формате «база ответов на типовые вопросы», ИИ-чат может сделать его ненужным. Подумайте, какая часть вашего контента уникальна и не воспроизводима диалогом с нейросетью.
Предпринимателю в РФ и СНГ: из доступных в России LLM для работы с кодом подходят YandexGPT и GigaChat, хотя для задач программирования многие разработчики по-прежнему используют англоязычные модели через VPN. Если вы строите продукт с базой знаний, закладывайте сценарий, в котором пользователь предпочтёт спросить ИИ-агента (программу, которая сама выполняет задачи по вашему запросу), а не листать ваш FAQ.
Гибель Stack Overflow как ежедневного инструмента разработчика, это не трагедия, а наглядный урок для всех, кто создаёт контент. Мы в dzen.guru видим ту же механику в нишах, далёких от кода: кулинарные сайты с рецептами, медицинские справочники, юридические базы. Везде, где ответ можно получить диалогом, статичная страница проигрывает.
Но у LLM есть честный предел: она не знает, что изменилось вчера, она не проверяет свой ответ на вашей машине, и она не несёт ответственности за результат. Stack Overflow, при всей токсичности модерации, давал проверенные сообществом решения с указанием версий и контекста. Этот слой верификации пока не заменён ничем. Так что полностью отказываться от чтения документации и проверки кода не стоит, даже если ИИ отвечает за три секунды.
Попробуйте генератор контента dzen.guru
Если вы автор Дзена и хотите ускорить работу с текстами так же, как разработчики ускорили работу с кодом, протестируйте наши инструменты для создания контента с помощью ИИ.
Попробовать бесплатноИстория Stack Overflow напоминает: ценность не в ответе, а в доверии к нему. LLM дают скорость, но проверка остаётся за человеком, и именно те, кто выстроит систему проверки, заберут аудиторию у тех, кто просто копирует выдачу нейросети.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
Платформа тестирования ИИ: как собрать конвейер экзаменов из документов за минуты
Платформа тестирования с искусственным интеллектом генерирует экзаменационные вопросы из нормативных документов за минуты вместо дней ручной работы методиста,…

Omen AI привлекла $31 млн: спектрометр следит за охлаждением дата центров в реальном времени
Omen AI — компания, чей миниатюрный спектрометр отслеживает состояние охлаждающей жидкости в серверных стойках, — 4 июня 2025 года объявила о привлечении 31…
MQTT и LLM через Model Context Protocol: датчики отвечают на вопросы текстом
Протокол MQTT (легковесный стандарт передачи сообщений между устройствами интернета вещей) давно стал рабочей лошадкой промышленных датчиков, но до недавнего…
Комментарии