Платформа тестирования ИИ: как собрать конвейер экзаменов из документов за минуты
Платформа тестирования с искусственным интеллектом генерирует экзаменационные вопросы из нормативных документов за минуты вместо дней ручной работы методиста, и сейчас я покажу, как собрать такой конвейер пошагово.
Ручной цикл «новый регламент, методист пишет вопросы, правит дубли, согласует» занимает дни и ломается при каждом обновлении документа. Автоматизация через LLM (большую языковую модель, ту же технологию, что стоит за ChatGPT) сокращает этот путь, но только если выстроен управляемый конвейер с проверкой качества, а не просто «скормить PDF нейросети».
Команда проекта Exam AI на Хабре подробно описала, как устроена их платформа тестирования с ИИ для корпоративной аттестации. Это не коробочный продукт для скачивания, а инженерный кейс: какие решения работают, какие ломаются и почему «просто попросить модель» даёт мусор вместо экзамена. Ниже я разобрал их опыт в формате пошаговой инструкции, чтобы вы могли повторить логику на своём стеке.
Что понадобится?
- Бэкенд: Python 3.12+ с FastAPI, база PostgreSQL с расширением pgvector для хранения эмбеддингов (числовых «отпечатков» текста, по которым ищут похожие фрагменты)
- Библиотека для структурированного вывода: pydantic-ai и Pydantic-схемы (шаблоны, которые заставляют модель отвечать строго в заданном формате, а не свободным текстом)
- Доступ к LLM-провайдеру: OpenAI API, YandexGPT, GigaChat или любая совместимая модель
- Фронтенд (если нужен интерфейс экзамена): React + xState для конечного автомата сессии
- Время: базовый конвейер генерации от 2 до 4 недель на одного разработчика, полноценная платформа тестирования с ИИ значительно дольше
Пошаговая инструкция: от документа до готового экзамена
-
Scan: разрежьте документ на фрагменты и постройте карту тем. Загрузите нормативный документ, разбейте его на смысловые куски, для каждого создайте эмбеддинг и сохраните в pgvector. На выходе получите пронумерованный список тем с привязкой к конкретным фрагментам текста.
-
Plan: спланируйте генерацию отдельным шагом. Определите, сколько вопросов нужно на каждую тему, какой тип (выбор одного ответа, множественный выбор, открытый ответ), расставьте приоритеты. Этот шаг критичен: без плана модель сама решает, о чём спрашивать, и выдаёт перекос в сторону первых абзацев документа.
-
Generate: генерируйте строго типизированные структуры, а не свободный текст. Используйте Pydantic-схемы, чтобы модель возвращала JSON с полями «вопрос», «варианты ответа», «правильный ответ», «привязка к теме». Если ответ не прошёл валидацию схемы, отправляйте повторный запрос с уточнением.
class GeneratedQuestion(BaseModel):
question_text: str
options: list[str]
correct_answer: str
knowledge_area: str
source_fragment_id: int
-
Validate: проверьте кандидатов автоматически. Запустите проверку на семантические дубли (сравнение эмбеддингов новых вопросов между собой и с банком), валидность ожидаемого ответа, привязку к нужной области знаний, полноту формата.
-
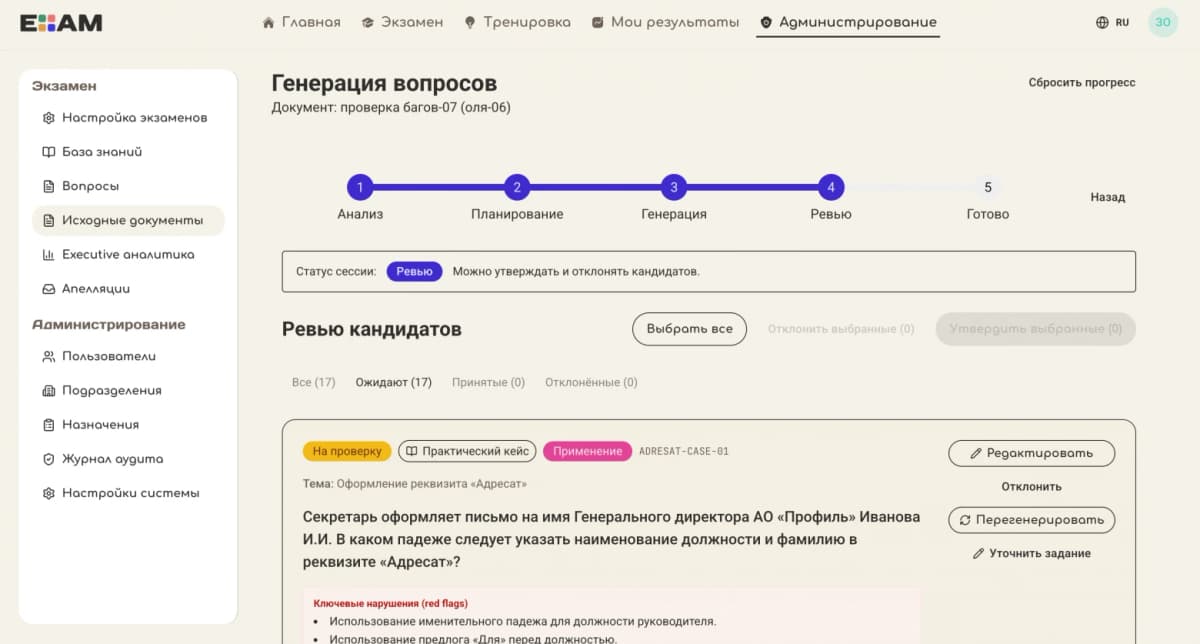
Review: оставьте финальное слово за человеком. Эксперт видит сгенерированные вопросы и выбирает: одобрить, отредактировать или отклонить. Команда Exam AI сознательно оставила «человека в контуре» как последний контроль качества.
Как победить главный баг: дубли при генерации нескольких вопросов?
Самая болезненная проблема, которую описала команда: пользователь просит два вопроса по теме, а получает два перефраза одного сценария. Причина в том, что человек мыслит тему как широкую область, а модель цепляется за один конкретный сценарий.
Решение состоит из четырёх частей:
- На этапе Scan нормализуйте фокус проверки как нумерованный список независимых граней темы
- На этапе Generate жёстко назначайте одну грань на каждый вопрос
- Добавьте отрицательный контекст: передавайте модели последние сформулированные вопросы и повторяющиеся опорные токены (токен, это единица текста, которую модель обрабатывает: слово или его часть)
- В промпте (prompt, текстовая инструкция для модели) зафиксируйте требование менять минимум два измерения кейса
Сгенерируй вопрос по грани #{facet_number} темы "{topic}".
НЕ ПОВТОРЯЙ следующие аспекты из уже созданных вопросов:
{previous_questions_summary}
Обязательно измени минимум 2 измерения: контекст ситуации,
тип ошибки, роль проверяющего, предлагаемое решение
или нормативный акцент.
Этот приём называют negative prompting, отрицательный контекст в промпте. После его внедрения команда добилась стабильного результата: два вопроса действительно покрывают два разных аспекта.
Экзаменационная сессия: конечный автомат вместо хаоса условий
Экзамен в реальном времени, это не один запрос «отправить ответ». Есть текущий шаг, таймеры, переходы между фазами, ограничения по действиям, восстановление сессии после обрыва связи.
Команда вынесла логику на фронтенде в xState (библиотека конечных автоматов), а на бэкенде поддержала событийную модель сессии. Результат: исчезает класс ошибок, когда кнопка на экране активна, но по правилам экзамена действие уже запрещено.
Что делать с этим прямо сейчас?
Авторам Дзена и копирайтерам. Тот же пайплайн Scan, Plan, Generate, Validate работает для создания тестов к обучающим курсам. Если вы продаёте экспертный контент, встроенный квиз повышает вовлечённость. Начните с ручного плана тем и генерации через ChatGPT или YandexGPT с Pydantic-подобной структурой в промпте.
Маркетологам. Корпоративная аттестация, это растущий рынок для EdTech-продуктов. Описанный подход показывает, что ценность не в самой генерации, а в антидублировании и валидации. Если вы выбираете платформу тестирования с ИИ для компании, спрашивайте именно про пайплайн проверки, а не про «умную генерацию».
Предпринимателям в РФ и СНГ. Стек полностью воспроизводим: Python, PostgreSQL, pgvector доступны без ограничений. В качестве LLM можно использовать YandexGPT или GigaChat. Подход с DDD-слоями (разделение кода на домен, приложение, инфраструктуру и представление) позволяет менять LLM-провайдера без переписывания ядра.
Входные данные: PDF регламента по охране труда на 40 страниц. Этап Scan разбил документ на 12 тематических кластеров. Этап Plan распределил 24 вопроса по кластерам. Этап Generate создал структурированные вопросы с привязкой к конкретным пунктам регламента. Этап Validate отсеял 3 вопроса как семантические дубли. Этап Review: эксперт отредактировал 4 формулировки и одобрил остальные. Итого: от загрузки документа до готового экзамена из 21 вопроса, часы вместо нескольких рабочих дней.
Генерация без плана. «Дадим модели большой документ и попросим N вопросов» даёт тематические перекосы, поверхностные вопросы и плохую воспроизводимость между запусками. Всегда разделяйте Scan и Plan.
Отсутствие отрицательного контекста. Без передачи уже созданных вопросов модель стабильно генерирует перефразы одного сценария. Особенно заметно при question_count больше одного.
Свободный текст вместо схемы. Без Pydantic-схемы или аналогичного шаблона модель возвращает ответы в произвольном формате, и парсинг ломается на каждом втором запуске.
Забытый фильтр в мультитенанте. Команда описала реальный дефект: при переключении организации на экране отображались данные чужой компании. Изоляция по организациям должна быть системным инвариантом, а не «парой WHERE в SQL».
Главная ценность этого кейса не в конкретном стеке, а в архитектуре пайплайна. Пять стадий (Scan, Plan, Generate, Validate, Review) применимы к любой задаче, где нужно массово создавать структурированный контент из документов: от тестов до FAQ, от чек-листов до карточек товаров. По моим наблюдениям, большинство команд застревают на этапе Generate и пропускают Validate, именно поэтому результат выглядит как «нейросеть нагенерировала мусор». Честная оговорка: даже с полным пайплайном человек-эксперт на финальном Review остаётся обязательным. Модели галлюцинируют (уверенно выдумывают факты), и в контексте аттестации сотрудников одна некорректная формулировка может стоить дорого.
Попробуйте промпт-конструктор dzen.guru
Соберите свой первый структурированный промпт для генерации тестовых вопросов из документа
Попробовать бесплатноЕсли вы строите свою платформу тестирования с ИИ или просто хотите автоматизировать создание квизов для аудитории, начните с малого: один документ, пять вопросов, Pydantic-схема и отрицательный контекст в промпте. Этого достаточно, чтобы увидеть разницу между «просто спросить нейросеть» и управляемым конвейером.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Omen AI привлекла $31 млн: спектрометр следит за охлаждением дата центров в реальном времени
Omen AI — компания, чей миниатюрный спектрометр отслеживает состояние охлаждающей жидкости в серверных стойках, — 4 июня 2025 года объявила о привлечении 31…
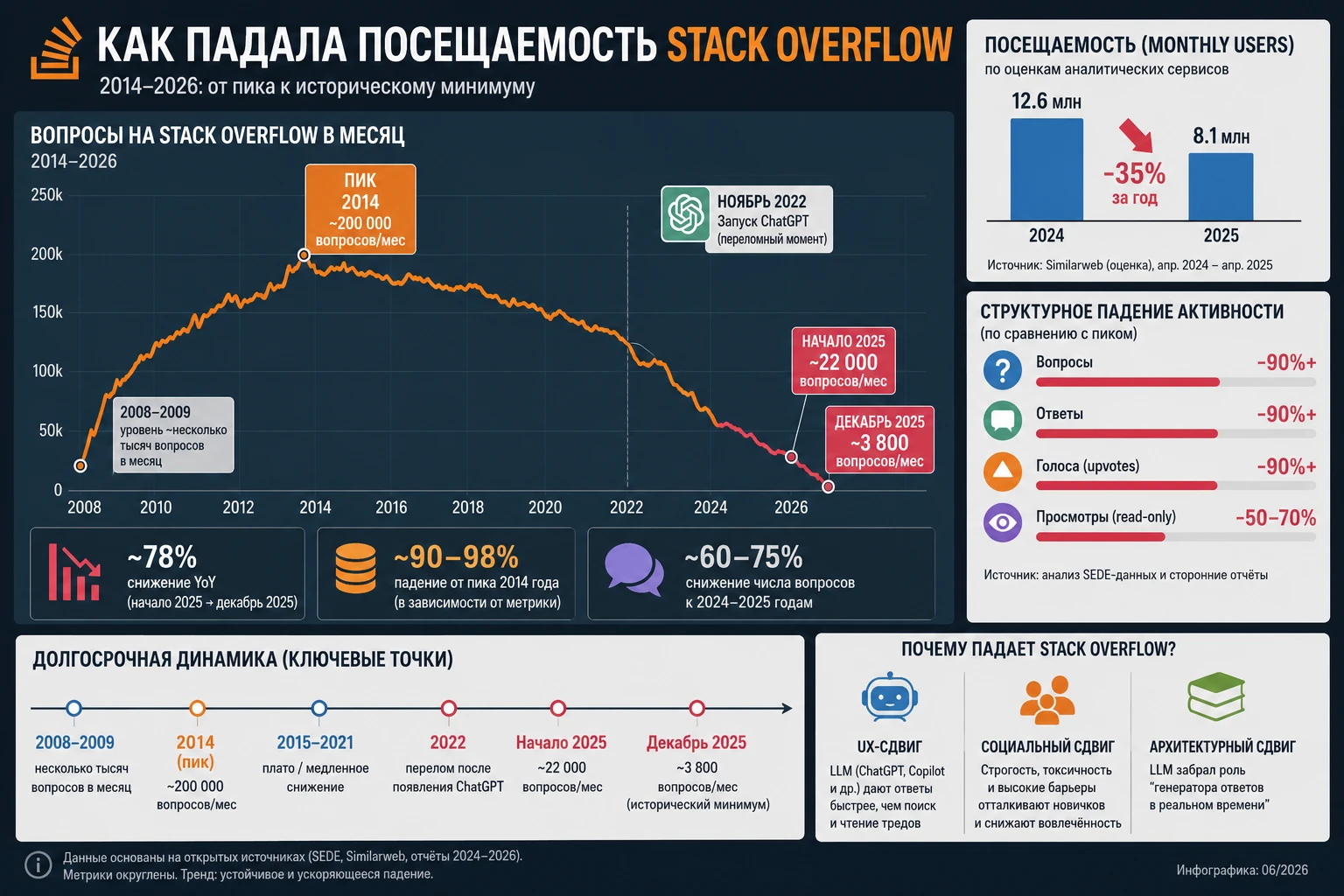
Stack Overflow купили за $1,8 млрд, а потом трафик упал почти до нуля
Stack Overflow когда-то был главным местом, где разработчик мог получить работающий ответ на конкретный вопрос по коду, и этот ресурс терял аудиторию ещё до…
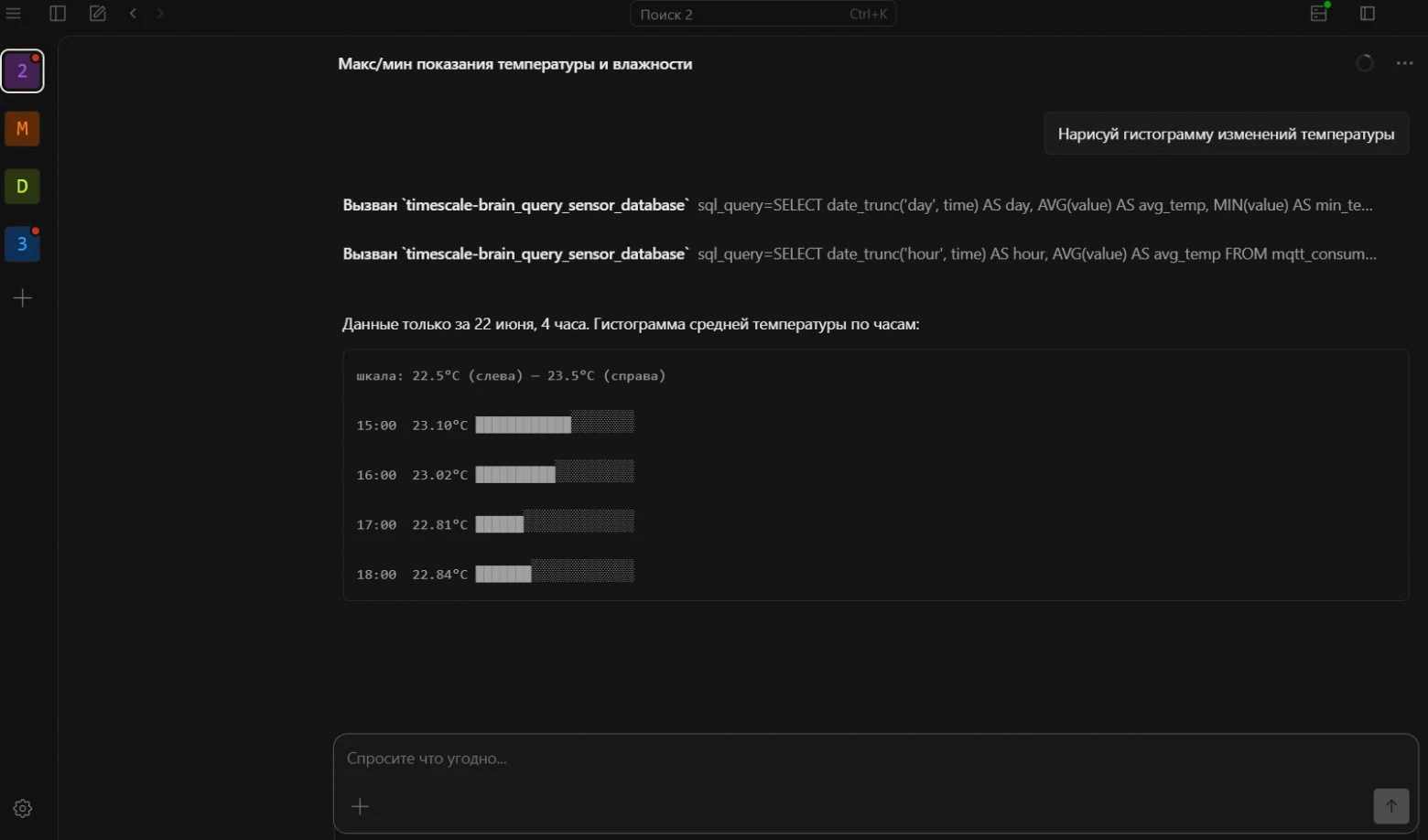
MQTT и LLM через Model Context Protocol: датчики отвечают на вопросы текстом
Протокол MQTT (легковесный стандарт передачи сообщений между устройствами интернета вещей) давно стал рабочей лошадкой промышленных датчиков, но до недавнего…
Комментарии