Распознавание еды ИИ: бенчмарк на 66 фото показал 84,8% точности и бесполезность confidence
Распознавание еды с помощью ИИ звучит просто, пока не попробуешь скормить модели фото гречки или домашней котлеты и не увидишь, как уверенно она называет это чем-то другим, а потом ещё и ставит себе высокую оценку за ответ.
Разработчик из России собрал открытый бенчмарк (набор тестовых задач с заведомо известными ответами) на 66 фотографиях русской, азиатской и европейской еды и обнаружил два факта: Gemini 2.5 Flash распознаёт русские блюда лучше западных, но показатель уверенности модели бесполезен и не предупреждает об ошибках.
Автор Habr ML строит приложение для подсчёта калорий по фото. Задача стандартная: пользователь снимает тарелку, модель определяет блюдо и считает КБЖУ (калории, белки, жиры, углеводы). Проблема в том, что «кажется, работает нормально» не годится как метрика, особенно когда приложение рассчитано на русскую кухню. Он решил измерить точность по-настоящему и выложил методику целиком.
Ниже разбираем, как повторить этот бенчмарк самостоятельно и на что обратить внимание, если вы делаете любое приложение с распознаванием еды ИИ.
Что понадобится
- Gemini 2.5 Flash через OpenRouter (или другая мультимодальная модель, то есть модель, которая понимает и текст, и картинки)
- Два открытых датасета: Food-101 от Stanford (101 класс блюд, по тысяче фото на каждый) и Roboflow russian-food (борщ, пельмени, оливье, блины)
- Go (язык программирования) для запуска скриптов, но логику можно перенести на Python
- Файл
labels_map.jsonс переводом классов Roboflow на русский - Примерно 2 часа на первый прогон с 66 фото
Пошаговая инструкция
- Скачайте датасеты и сгенерируйте манифест. Скрипт
setup.pyзабирает оба источника и создаёт файлmanifest.csv, где для каждого фото указано правильное блюдо и допустимый диапазон калорий.
file,cuisine,source,truth_dish,ref_kcal_low,ref_kcal_high
borscht_001.jpg,RU,roboflow,борщ,300,500
pelmeni_002.jpg,RU,roboflow,пельмени,400,700
sushi_003.jpg,ASIA,food101,суши,200,400
pizza_004.jpg,EU,food101,пицца,600,900
- Прогоните каждое фото через модель. Вызов
vision.Provider.Recognize()отправляет картинку в Gemini 2.5 Flash и получает обратно название блюда, список ингредиентов с весами, КБЖУ и показатель уверенности (confidence от 0 до 1). Результаты записываются вresults.csv.
res, err := provider.Recognize(ctx, f, mime)
// res.DishName — "борщ с говядиной"
// res.Confidence — 0.92
// res.Kcal — 420
// res.Ingredients — [{говядина, 100г}, {свёкла, 80г}, ...]
- Оцените результаты автоматически. Вместо ручной проверки 66 строк автор использует ту же модель как судью. Она получает правильный ответ и предсказание, затем выдаёт ровно одно слово.
const judgePrompt = `You are grading a food-photo recogniser.
Ground truth dish: "%s". The model predicted: "%s".
Classify the match:
- correct: the SAME core dish
- wrong-but-close: a DIFFERENT but related dish
- wrong: a fundamentally different dish
Reply with exactly one word.`
Параметры: temperature=0, max_tokens=16. Три вердикта вместо привычного «правильно/неправильно» разделяют ошибки на поправимые (пользователь переименует за пару нажатий) и критические (человек закроет приложение).
-
Проверьте калибровку уверенности. Сравните, получили ли фотографии с вердиктом
wrongнизкий confidence. Если нет, ваш порог предупреждения бесполезен. -
Проверьте правдоподобие калорий. Для каждого блюда в манифесте задан диапазон (борщ 300-500 ккал, пельмени 400-700 ккал). Попадает ли ответ модели в этот коридор?
-
Пересчитайте без повторного прогона. Вердикты в CSV можно поправить вручную и запустить пересчёт:
go run ./cmd/benchmark -rescore
go run ./cmd/benchmark -summarize
Что показали 66 фотографий?
Общая точность распознавания: 84,8% совпадений, 9,1% близких ответов, 6,1% критических ошибок. Восстановимый результат (correct + wrong-but-close) составил 93,9% при планке в 80%.
Распределение по кухням удивило самого автора:
- Русская еда: 14 из 14, ни одной ошибки
- Азиатская: 21 из 22, точность 95,5%
- Европейская: 27 из 30, точность 90%
Автор ожидал обратного: западных блюд в обучающих данных (материалах, на которых модель училась) заведомо больше. Но все четыре провала оказались составными или запечёнными блюдами, где ключевой ингредиент скрыт под сыром, соусом или корочкой. Лазанья под слоем сыра действительно похожа на запеканку. Граница проходит не между кухнями, а между «видно ингредиенты» и «не видно».
Confidence врёт, и это главный вывод
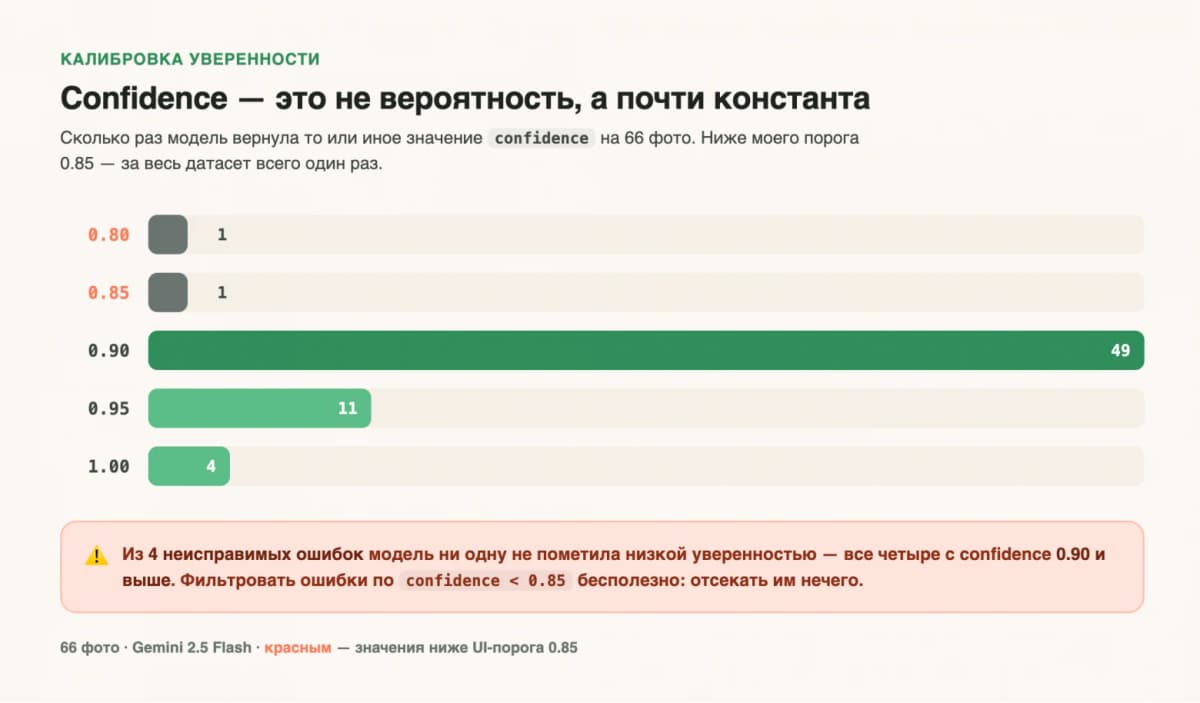
Ни одна из четырёх критических ошибок не получила предупреждения. Все четыре вышли с высоким confidence.
Но проблема глубже: 49 из 66 фотографий получили ровно 0,90. За весь датасет модель опустилась ниже порога 0,85 один раз. То есть confidence в данном случае не вероятность правильного ответа, а по сути константа. Порог предупреждения, который автор показывал пользователям, висел для красоты.
Для всех, кто строит приложения с распознаванием еды ИИ, это конкретный сигнал: нельзя полагаться на встроенную уверенность модели как на фильтр ошибок. Нужен внешний механизм проверки.
Что делать с этим прямо сейчас?
-
Разработчику приложения для подсчёта калорий: повторите бенчмарк на своих данных. Даже 66 фотографий достаточно, чтобы понять, работает ли ваш порог уверенности или просто занимает место в интерфейсе. Датасеты открыты, скрипты автор выложил.
-
Автору Дзена, который пишет про еду и здоровье: если рекомендуете приложения для подсчёта калорий по фото, теперь есть конкретные цифры. 6% критических ошибок означает, что примерно каждое шестнадцатое фото будет распознано принципиально неверно. Честная оговорка для читателей.
-
Предпринимателю, который думает о фуд-тех продукте: русская еда распознаётся не хуже западной, а по этому тесту даже лучше. Барьер входа ниже, чем кажется. Gemini 2.5 Flash доступен через OpenRouter, в РФ потребуется VPN или прокси.
Автор подал фото варёной гречки. Модель вернула правильное название и confidence 0,90. Но когда на тарелке оказалась гречка с котлетой, модель переключилась на котлету как основное блюдо. Это не критическая ошибка (вердикт wrong-but-close), но для пользователя означает неверный подсчёт калорий: котлета без гарнира и котлета с гречкой отличаются на 100-150 ккал. Если ваше приложение считает КБЖУ, тестируйте именно составные тарелки, а не одиночные блюда.
Не доверяйте confidence как фильтру качества. В этом бенчмарке показатель уверенности оказался практически константой и не отличал правильные ответы от критических ошибок. Если вы строите UX вокруг фразы «модель не уверена, проверьте», проверьте сначала, действительно ли модель хоть когда-нибудь выдаёт низкую уверенность. Ещё одна ловушка: использовать ту же модель как судью. Автор честно оговаривает риск предвзятости (self-serving bias, когда модель оценивает саму себя мягче). На 66 строках расхождений с ручной проверкой не нашлось, но на тысячах фотографий лучше взять отдельную модель.
Этот бенчмарк ценен не масштабом, а методом. 66 фото для статистики мало, автор это признаёт. Но сам подход: три уровня вердикта вместо бинарного «верно/неверно», проверка калибровки уверенности, отдельная проверка правдоподобия калорий повторим на любой задаче, где мультимодальная модель что-то классифицирует. Я бы добавил одно: если делаете продукт для российского рынка, соберите свой датасет из 30-50 фотографий домашней еды, снятых на телефон при кухонном освещении. Студийные фото из Food-101 и реальные снимки пользователей это два разных мира. По моим наблюдениям, качество распознавания на «грязных» бытовых фото падает заметно.
Хотите научиться тестировать ИИ-инструменты системно?
В dzen.guru мы разбираем, как проверять нейросети на практике, а не верить маркетинговым обещаниям.
Узнать большеПо материалам Habr ML

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Kimi Work запускает 300 AI-агентов на вашем ПК: облако больше не нужно
Moonshot AI на этой неделе выпустила Kimi Work, настольное приложение для macOS и Windows, где до 300 ИИ-агентов (программ, самостоятельно выполняющих задачи)…

IPO SpaceX: когда начнутся торги и почему $75 млрд побили рекорд втрое
SpaceX второго июня оценила свои акции в 135 долларов за штуку и привлекла 75 миллиардов долларов от андеррайтеров, оформив крупнейшее первичное размещение в…

Неделя на один комикс: какие LLM проблемы вскрыл эксперимент с ChatGPT
Автор из сообщества Habr неделю бился с генерацией комикса через бесплатный ChatGPT и подробно задокументировал каждый промпт и каждый провал, показав на…
Комментарии