Неделя на один комикс: какие LLM проблемы вскрыл эксперимент с ChatGPT
Автор из сообщества Habr неделю бился с генерацией комикса через бесплатный ChatGPT и подробно задокументировал каждый промпт и каждый провал, показав на практике, где именно большие языковые модели спотыкаются при работе с русскоязычными инструкциями.

Большинство советов по промпт-инжинирингу написаны на английском и для англоязычных задач. Русскоязычные пользователи сталкиваются с дополнительным слоем LLM проблем: модель хуже считывает пространственные указания на русском, путает кириллические надписи на изображениях и теряет детали в длинных структурированных промптах. Этот разбор показывает, как именно это происходит и что с этим делать.
Зачем нужен этот разбор?
Автор публикации на Habr поставил эксперимент: попросил бесплатную версию ChatGPT нарисовать многопанельный комикс с антропоморфными персонажами, кириллическими надписями на баннерах и монетах, точным расположением объектов и диалоговыми пузырями. Промпт занимал десятки строк с подробной разметкой каждого ряда и каждой панели.
Результат не совпал с заданием ни в одной из версий. Автор итерировал промпт уже неделю, и конца процессу не видно. Именно этот зазор между детальным техническим заданием и тем, что модель выдаёт, и есть главная иллюстрация LLM проблем при генерации визуального контента.
Что понадобится
- Доступ к ChatGPT (бесплатная версия подойдёт для воспроизведения эксперимента)
- Текстовый редактор для подготовки промптов (подойдёт любой, хоть «Блокнот»)
- Базовое понимание, что такое промпт (текстовая инструкция для нейросети)
- 30 минут на первую итерацию и готовность к нескольким повторным заходам
Пошаговая инструкция
-
Сформулируйте задачу на уровне сцены, а не на уровне пикселя. Опишите общий замысел одним абзацем: кто персонажи, что происходит, какой финал. Модель лучше «схватывает» сюжетную логику, чем координатные указания вроде «в правой части панели видна левая половина прилавка».
-
Разбейте сложный промпт на отдельные запросы. Вместо одного промпта на шесть панелей комикса отправьте шесть отдельных запросов, по одному на панель. Так модель удержит больше деталей. Длинный промпт (промпт-инжиниринг подразумевает и контроль длины) теряет инструкции ближе к середине.
-
Кириллические надписи задавайте отдельной строкой с пометкой.
Текст на баннере (кириллица, крупный шрифт): ОБМЕН ВАЛЮТЫ
Выделение в отдельную строку снижает вероятность галлюцинации (когда модель уверенно подставляет не тот текст или искажает буквы).
-
Проверяйте результат по чек-листу, а не «на глаз». Составьте список из пяти ключевых элементов, которые обязаны быть на изображении (персонаж, надпись, предмет, расположение, реплика). Пройдитесь по списку. Это экономит время на повторных итерациях.
-
Фиксируйте каждую версию промпта с пометкой, что изменили. Автор исходной статьи нумеровал версии (v1, v2). Добавьте к номеру одну строку: «v2: убрал координаты, добавил описание действия». Через пять итераций без этого вы не вспомните, что уже пробовали.
-
Для проверки стабильности запустите один и тот же промпт в трёх новых сессиях. Автор статьи задал критерий успеха: три корректных результата в трёх чистых сессиях. Это честный тест. Одна удачная картинка из десяти попыток не означает, что промпт работает.
Автор отправил промпт длиной более 80 строк с описанием трёх рядов комикса, включая точные надписи на монетах («10»), текст на баннере («ОБМЕН ВАЛЮТЫ»), указание, что правая половина прилавка «выходит за правую границу панели», и четыре диалоговых пузыря с репликами на русском. Модель в ответ сгенерировала изображение, где надписи были искажены, расположение объектов не совпадало с инструкцией, а часть реплик оказалась перепутана между персонажами. После нескольких итераций с укороченными промптами (одна панель за запрос, надписи отдельной строкой) часть ошибок удалось убрать, но стабильного результата автор так и не получил за неделю работы.
Перегруз промпта координатами. «В правой части панели видна левая половина» звучит точно для человека, но модель не оперирует координатной сеткой. Замените на действие: «Заяц сидит за прилавком, прилавок обрезан правым краем кадра».
Ожидание, что кириллица на картинке будет без ошибок. Генерация текста на изображениях остаётся слабым местом моделей. Если надпись критична, проще добавить её в графическом редакторе после генерации.
Один промпт на весь комикс. Чем длиннее инструкция, тем больше деталей модель «забывает». Токен (единица текста, которую модель обрабатывает) имеет лимит: даже если промпт помещается в окно, внимание модели распределяется неравномерно. Середина длинного промпта страдает.
Вера в то, что платная версия решит всё. Автор статьи прямо предупреждает: «Не надо мне рассказывать, что только в платных всё работает». Смысл бесплатной версии в том, чтобы показать возможности модели. Если логика промпта слабая, платная подписка не спасёт.
Что делать с этим прямо сейчас, по ролям
Автору на Дзене. Если вы генерируете обложки или иллюстрации через ChatGPT, дробите задачу. Один промпт на один элемент. Надписи на русском добавляйте в Canva или Figma поверх сгенерированной картинки. Это быстрее, чем пять итераций с надеждой, что модель напишет «ВАЛЮТЫ» без ошибок.
Маркетологу. LLM проблемы с визуалом означают, что пока нельзя автоматизировать создание баннеров с точным текстом. Закладывайте этап ручной доводки в пайплайн. Экономия времени от нейросети реальна, но на финише нужен человек с редактором.
Предпринимателю в РФ. Из доступных в России инструментов для генерации изображений есть Kandinsky от Сбера и Шедеврум от Яндекса. Обе модели тоже плохо справляются с кириллическими надписями на картинках. Это ограничение технологии в целом, а не конкретного сервиса.
Этот эксперимент ценен не результатом (комикс так и не получился), а процессом. Автор показал, что даже опытный пользователь с навыком составления технических заданий не может заставить модель стабильно выполнить визуальную задачу средней сложности. По моим наблюдениям, русскоязычные промпты для генерации изображений работают заметно хуже англоязычных: модель чаще путает детали и хуже воспроизводит кириллицу. Практический вывод: используйте нейросеть как «болванку» для визуала, а текст, расположение и финальную доводку делайте руками. И честная оговорка: ситуация меняется с каждым обновлением модели. То, что не работает сегодня, может заработать через месяц, но планировать рабочий процесс стоит исходя из текущих ограничений, а не из обещаний.
Попробуйте генератор промптов dzen.guru
Собрали шаблоны промптов для русскоязычных задач, от текста до изображений. Экономят время на итерациях.
Попробовать бесплатноГлавное, что стоит забрать из этого разбора: детальность промпта не равна качеству результата. Модель не читает ваш текст как чертёж. Она угадывает намерение. Чем проще и короче намерение, тем точнее угадывание. А всё, что требует точности до буквы и пикселя, пока остаётся работой для человека.
По материалам Habr ML

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
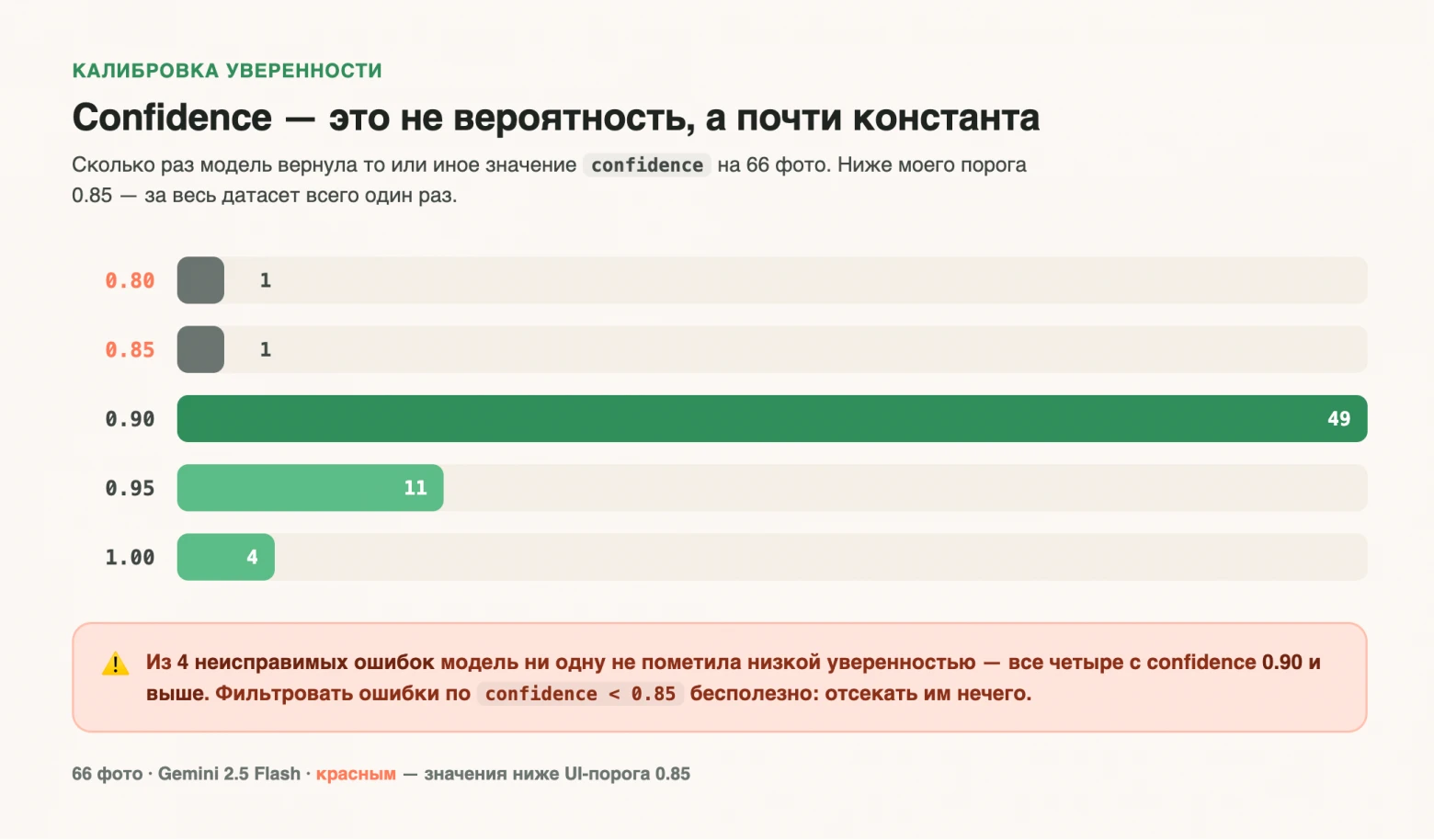
Распознавание еды ИИ: бенчмарк на 66 фото показал 84,8% точности и бесполезность confidence
Распознавание еды с помощью ИИ звучит просто, пока не попробуешь скормить модели фото гречки или домашней котлеты и не увидишь, как уверенно она называет это…

Kimi Work запускает 300 AI-агентов на вашем ПК: облако больше не нужно
Moonshot AI на этой неделе выпустила Kimi Work, настольное приложение для macOS и Windows, где до 300 ИИ-агентов (программ, самостоятельно выполняющих задачи)…

IPO SpaceX: когда начнутся торги и почему $75 млрд побили рекорд втрое
SpaceX второго июня оценила свои акции в 135 долларов за штуку и привлекла 75 миллиардов долларов от андеррайтеров, оформив крупнейшее первичное размещение в…
Комментарии