Спекулятивный декодинг DFlash ускоряет нейросети в 15 раз: потолок EAGLE-3 пробит
Компания z-lab из Калифорнийского университета в Сан-Диего представила DFlash, метод спекулятивного декодинга на основе блочной диффузии, который ускоряет генерацию текста большими языковыми моделями от 6 до 15 раз без потери качества ответов.
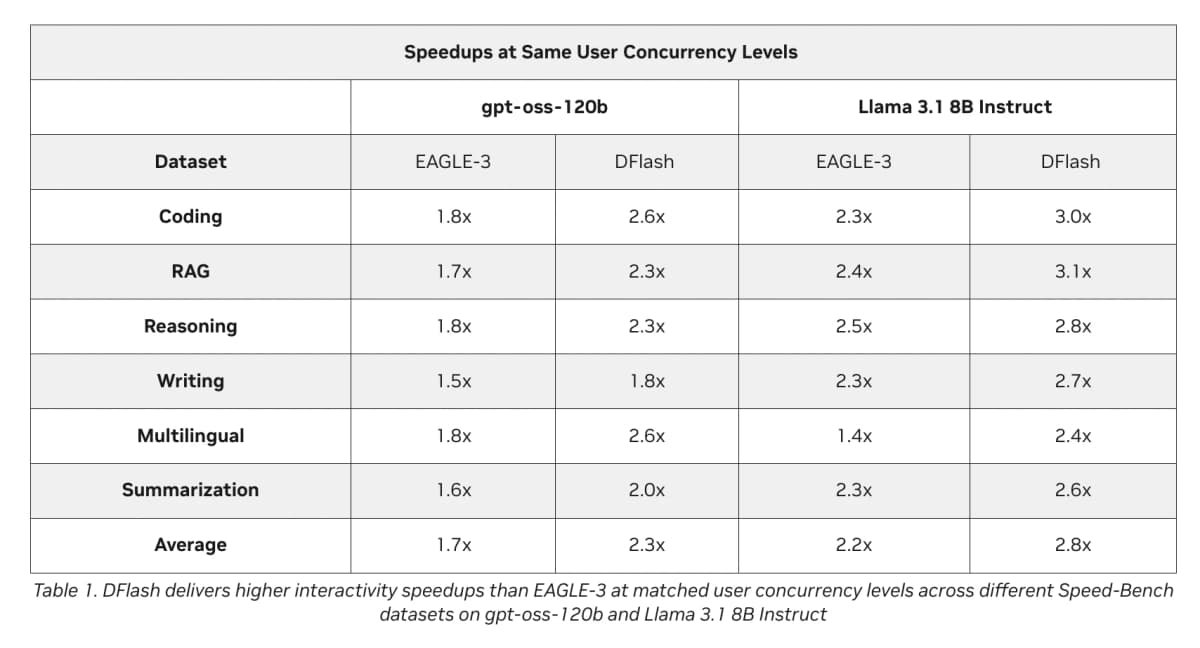
Стандартные методы спекулятивного декодинга, включая лучший на сегодня EAGLE-3, упираются в потолок ускорения 2-3 раза. DFlash ломает это ограничение: вместо последовательной генерации черновых токенов (токен, минимальная единица текста для модели, примерно один слог) он предлагает сразу целый блок за один проход.
Спекулятивный декодинг (speculative decoding) устроен просто: маленькая черновая модель быстро угадывает следующие слова, а большая целевая проверяет их параллельно. Угаданные сохраняются, ошибочные отбрасываются. Итоговый текст идентичен тому, что выдала бы большая модель сама, но быстрее. Проблема в том, что черновая модель до сих пор работала последовательно, слово за словом, и это тормозило весь процесс. Исследователи из z-lab заменили последовательный черновик на блочную диффузионную модель, и результаты, по данным их статьи и тестов инженеров NVIDIA, оказались кратно выше прежних.
| Что | Когда | Кто выпустил | Цена |
|---|---|---|---|
| DFlash, метод спекулятивного декодинга на блочной диффузии | Июнь 2025 | z-lab (Калифорнийский университет в Сан-Диего) | Бесплатно, открытый код |
Что меняет DFlash?
-
Черновик генерируется целым блоком за один проход. Обычные методы спекулятивного декодинга создают черновые токены по одному. DFlash предлагает сразу блок из 15-16 токенов за один шаг. Затраты на черновик почти не растут с увеличением длины блока.
-
Ускорение от 6 до 15 раз вместо 2-3. На модели Qwen3-8B с обычным бэкендом Transformers DFlash показывает среднее ускорение 4,86 раза, пиковое на математических задачах MATH-500 составляет 6,08 раза. Для сравнения: EAGLE-3 на тех же задачах даёт 1,76-2,02 раза. Это данные из статьи исследователей.
-
До 15 раз на серверном оборудовании NVIDIA. Инженеры NVIDIA протестировали DFlash на модели gpt-oss-120b с восемью GPU Blackwell в системе DGX B300. При целевой скорости 500-600 токенов в секунду на пользователя пропускная способность выросла более чем в 15 раз по сравнению с обычной генерацией. Это примерно в 1,5 раза больше, чем у EAGLE-3 при тех же условиях.
-
Качество не страдает. Целевая модель проверяет каждый блок. Финальный текст полностью совпадает с тем, что модель выдала бы без ускорения. Это называется lossless acceleration, ускорение без потерь.
-
Черновая модель крошечная. DFlash использует черновик всего из пяти слоёв (восемь для Qwen3-Coder). Предыдущие диффузионные методы (DiffuSpec, SpecDiff-2) требовали модели на 7 миллиардов параметров и давали ускорение лишь 3-4 раза.
Почему это работает лучше предшественников?
Ключевая идея авторов: большая целевая модель уже «знает» про будущие токены. Её скрытые состояния (hidden states, внутренние представления текста в модели) содержат информацию о нескольких следующих слов. DFlash извлекает эти состояния и подаёт их черновой модели через механизм ключей и значений (KV-кэш) в каждом слое, а не только на входе, как делает EAGLE-3.
Результат: чем глубже черновая модель, тем больше токенов она угадывает верно. Пятислойный черновик DFlash, генерирующий 16 токенов, по данным статьи, обгоняет EAGLE-3, генерирующий 8 токенов, и по скорости, и по доле принятых токенов.
Как попробовать?
-
Установите vLLM (фреймворк для запуска языковых моделей). DFlash уже поддерживается: достаточно указать метод
dflashв конфигурации при запуске модели. Код команды есть в документации проекта на GitHub (z-lab). -
Выберите модель и черновик. Готовые контрольные точки опубликованы для моделей семейства Qwen3 и Llama 3.1. Например, для Qwen3-8B черновик называется
z-lab/Qwen3-8B-DFlash-b16. -
Для Transformers используйте вызов
spec_generate. Загрузите черновую модель черезAutoModel, целевую черезAutoModelForCausalLM, и вызовите генерацию. Переделывать приложение не нужно. -
Проверьте требования к GPU. Целевая модель всё равно должна помещаться в память видеокарты. Черновая модель добавляет минимальную нагрузку, но для моделей на 8 миллиардов параметров потребуется видеокарта с 16 и более гигабайтами видеопамяти.
Есть ли аналоги в России?
Спекулятивный декодинг как метод доступен при локальном запуске открытых моделей, и DFlash не исключение: если у вас есть GPU и доступ к весам Qwen3 или Llama, вы можете использовать его из России.
Закрытые российские сервисы, YandexGPT и GigaChat, не раскрывают, какие методы ускорения инференса (инференс, процесс генерации ответа моделью) применяют на своей стороне. Пользователь этих сервисов не может подключить DFlash: ускорение внутри API контролирует сам провайдер.
Для тех, кто разворачивает модели локально или на арендованных серверах, DFlash актуален напрямую. Открытые веса и код позволяют запустить его без ограничений по региону.
DFlash решает одну из самых болезненных проблем для тех, кто запускает языковые модели на своём железе: долгое ожидание ответа. На мой взгляд, разница между ускорением в 2 раза и в 6 раз, это разница между «терпимо, но медленно» и «можно работать в реальном времени».
Для авторов Дзена это пока не кнопка в интерфейсе. Но если вы используете локальные модели для генерации черновиков, рерайта или анализа текстов, ускорение в 5-6 раз означает, что модель на 8 миллиардов параметров начинает отвечать с комфортной скоростью на обычной игровой видеокарте.
Оговорка: метод пока поддерживает ограниченный набор моделей (Qwen3, Llama 3.1). Для русскоязычных задач Qwen3 работает неплохо, но это не специализированная русская модель. Попробуйте развернуть Qwen3-8B с DFlash-черновиком и сравните скорость с обычной генерацией, разница заметна даже субъективно.
Частые вопросы
Нужно ли переобучать модель для работы с DFlash?
Нет. DFlash работает как внешний адаптер. Целевая модель остаётся без изменений. Вы подключаете готовый черновик (контрольные точки опубликованы), и генерация ускоряется. Качество ответов не меняется, потому что финальную проверку всегда проводит большая модель.
Работает ли DFlash с любой языковой моделью?
На данный момент, нет. Опубликованы контрольные точки для моделей семейства Qwen3 и Llama 3.1. Поддержка других архитектур зависит от того, обучит ли кто-то соответствующий черновик. Код открыт, поэтому сообщество может расширить список.
Чем спекулятивный декодинг отличается от простого уменьшения модели?
Маленькая модель отвечает быстрее, но хуже. Спекулятивный декодинг сохраняет качество большой модели, но использует маленькую только как «черновик для проверки». Итоговый текст математически идентичен тому, что выдала бы большая модель сама. Вы получаете скорость малой модели и точность большой.
Для разработчиков, которые запускают языковые модели локально на ограниченном железе, DFlash превращает мучительно медленный инференс (инференс) в рабочий инструмент. Код и контрольные точки уже доступны в открытом доступе z-lab на GitHub.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Профессии, связанные с ИИ: 5 уже исчезают, вот как оценить свою за вечер
Мне нужно написать how-to статью о профессиях, которые ИИ заменяет и создаёт. Текст должен быть практическим, с пошаговой инструкцией по оценке своей позиции…

Что такое галлюцинации нейросетей: как MCP-сервер запрещает модели считать в уме
Галлюцинация (когда нейросеть уверенно выдаёт цифру, которой нет в данных) остаётся главной причиной, по которой авторы и аналитики не доверяют языковым…
Graphify строит граф зависимостей проекта: статический анализ кода Python без облака
Библиотека Graphify анализирует Python-проект локально, без облака и без ключей к API, строит из кода граф знаний и показывает, какие модули связаны, где…
Комментарии