RAG нейросети в рекомендациях: как понять запрос «детектив в усадьбе» без истории оценок
Система рекомендаций на основе RAG (retrieval-augmented generation, генерация ответа с опорой на найденные документы) решает задачу, с которой классические алгоритмы не справляются: понимает запрос на живом языке, находит подходящий контент в каталоге и объясняет, почему именно он подходит.
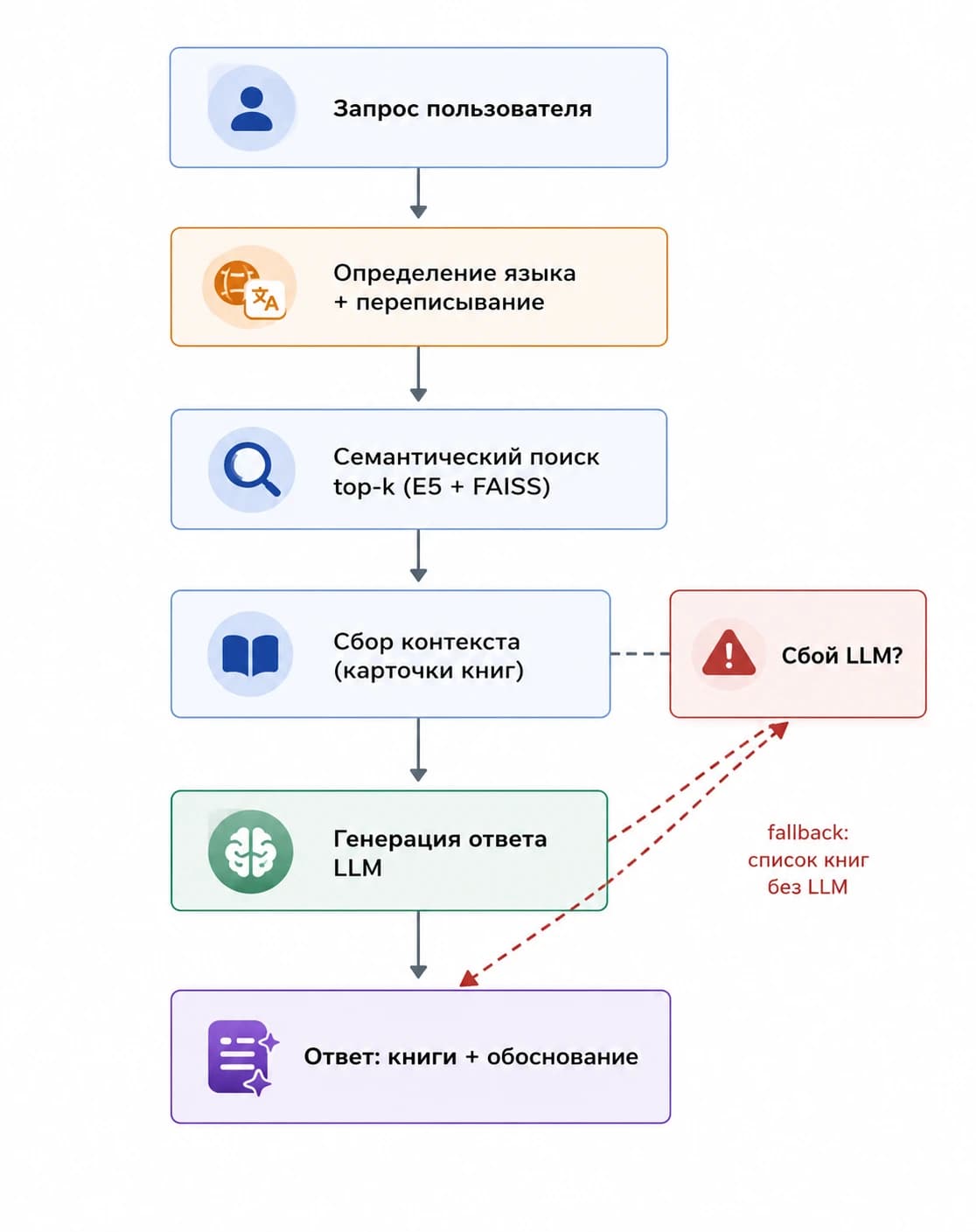
Классические рекомендательные системы не умеют работать с запросами вроде «детектив в английской усадьбе» или «фантастика про моральный выбор». RAG нейросети закрывают этот пробел: семантический поиск сопоставляет смысл запроса со смыслом описания, а языковая модель формирует понятное обоснование выбора.
Большинство руководств по RAG сосредоточено на чат-ботах и вопросно-ответных системах поверх базы знаний. Однако внутренняя механика подхода (семантический поиск плюс генерация ответа на основе найденного) ложится и на рекомендации. Об этом говорится в обзоре Gao et al., 2023, хотя сами авторы фокусируются на QA-сценариях. Ниже разберём, как собрать рекомендательный RAG-пайплайн (цепочку «поиск, контекст, генерация») на примере каталога книг и адаптировать подход под любой контент.
Какую проблему это решает?
Классические рекомендательные системы делятся на три семейства:
- Коллаборативная фильтрация (collaborative filtering) опирается на совпадение оценок и действий пользователей. Не работает без истории: новый пользователь или новый объект без оценок остаётся невидимым.
- Контентная фильтрация (content-based) сравнивает признаки объектов: жанр, автор, ключевые слова. Сходство измеряется через TF-IDF (метод оценки важности слова в документе) и косинусное расстояние, но эти метрики ищут совпадение слов, а не смысла.
- Гибридные модели комбинируют оба сигнала, частично смягчая холодный старт, но по-прежнему не понимают запрос на естественном языке.
Все три подхода ломаются на том, что в статье названо «проблемой холодного запроса». Запрос «медленный детектив в старинной английской усадьбе» содержит жанровый, стилистический и атмосферный ориентиры одновременно. Ни один из этих признаков не зафиксирован в каталоге в готовом виде, и классическая модель не способна их сопоставить.
RAG нейросети решают это в три шага: семантический поиск находит релевантные карточки по смыслу, контекстное окно собирает найденное в текст, а языковая модель генерирует ответ с объяснением и привязкой к реальным записям каталога.
Что понадобится
- Векторная база данных: Chroma, Qdrant, Milvus или аналоги. Для старта хватит бесплатного тарифа Chroma.
- Эмбеддинг-модель (модель, которая превращает текст в числовой вектор, сохраняя смысл): sentence-transformers, OpenAI Embeddings API или E5. Для русскоязычного каталога подойдут multilingual-модели.
- Языковая модель для генерации: GPT-4o, Claude, GigaChat или YandexGPT. Подойдёт любая, принимающая текстовый контекст.
- Каталог контента: таблица с полями «название», «автор», «жанры», «описание». Минимум 100 записей для осмысленных результатов.
- Python 3.10+ и библиотеки: langchain или llama-index, pandas.
- Время: базовый прототип собирается за 2 до 4 часа.
Пошаговая инструкция
- Подготовьте карточки каталога. Каждая запись должна содержать название, автора, жанры и описание. Соберите их в единую строку для эмбеддинга:
Title: Десять негритят
Author: Агата Кристи
Genres: детектив, классика
Description: Десять незнакомцев приглашены на остров...
Именно такой формат (структурированная строка с полями) позволяет эмбеддинг-модели использовать название, автора и жанр параллельно с описанием, а не только текст аннотации.
- Векторизуйте карточки и загрузите в базу. Пропустите каждую строку через эмбеддинг-модель и сохраните вектор в базе:
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-base")
vectorstore = Chroma.from_texts(card_texts, embeddings)
- Настройте поиск по запросу. Когда пользователь вводит запрос на естественном языке, система ищет ближайшие по смыслу карточки:
results = vectorstore.similarity_search(
"медленный детектив в старинной английской усадьбе",
k=5
)
Параметр k задаёт, сколько карточек попадёт в контекст для языковой модели. Для книжных рекомендаций 5 до 10 карточек обычно достаточно.
- Сформируйте промпт для языковой модели. Соберите найденные карточки в контекстное окно и добавьте системный промпт (инструкцию, которая задаёт поведение модели):
Ты — рекомендательный сервис. На основе карточек ниже
порекомендуй книги, соответствующие запросу пользователя.
Для каждой рекомендации объясни, почему она подходит.
Рекомендуй ТОЛЬКО книги из предоставленных карточек.
Карточки:
{найденные карточки}
Запрос пользователя: {текст запроса}
Инструкция «только из предоставленных карточек» снижает галлюцинации (ситуации, когда модель уверенно выдумывает несуществующую книгу или приписывает ей чужой сюжет).
-
Отправьте промпт в языковую модель и получите ответ с объяснениями. Модель вернёт список рекомендаций, каждая с обоснованием: почему эта книга соответствует запросу.
-
Проверьте результат вручную. Убедитесь, что все рекомендованные книги реально существуют в каталоге, а объяснения не содержат выдуманных деталей.
Запрос: «научная фантастика о моральном выборе в духе Урсулы Ле Гуин»
Результат (сокращённо):
- «Левая рука тьмы», Урсула Ле Гуин. Подходит потому, что роман ставит вопрос о гендерной идентичности и доверии между культурами, это центральная моральная дилемма.
- «Обделённые», Урсула Ле Гуин. Конфликт между двумя политическими системами вынуждает героя делать выбор между свободой и безопасностью.
- «Цветы для Элджернона», Дэниел Киз. Хотя автор другой, тема морального выбора (право человека на интеллект и его последствия) перекликается с тональностью Ле Гуин.
Классическая контентная фильтрация нашла бы первые два результата по тегу «Ле Гуин», но не предложила бы Киза: слово «моральный выбор» не записано в метаданных, а семантический поиск уловил смысловую близость описаний.
- Слишком короткие описания в карточках. Если описание состоит из одного предложения, эмбеддинг получается бедным и поиск теряет точность. Минимум 3 до 5 предложений на карточку.
- Забыли ограничить модель каталогом. Без явной инструкции «рекомендуй только из предоставленных карточек» модель начнёт придумывать книги из своих обучающих данных. Это главный источник галлюцинаций в рекомендательном RAG.
- Один эмбеддинг на всё. Для русскоязычного каталога англоязычная модель эмбеддингов даст слабые результаты. Используйте мультиязычные модели (multilingual-e5, labse) или русскоязычные.
- Слишком большой k. Если подать в контекст 50 карточек, модель начнёт путаться и терять релевантность. Для начала держитесь диапазона от 5 до 10.
- Нет проверки на галлюцинации. Даже с RAG модель может исказить сюжет книги или перепутать авторов. На этапе прототипа проверяйте каждый ответ вручную.
Что это даёт вам прямо сейчас?
Авторам Дзена. Если вы ведёте канал с подборками (книги, фильмы, курсы, рецепты), RAG-подход позволяет строить подборки по запросам читателей в свободной форме. Вместо ручного перебора каталога вы задаёте запрос и получаете кандидатов с готовыми объяснениями, которые можно взять за основу текста.
Маркетологам. Рекомендательный RAG решает задачу персонализации без сбора поведенческих данных. Это актуально для новых продуктов и небольших каталогов, где коллаборативная фильтрация невозможна из-за нехватки истории покупок.
Предпринимателям в РФ и СНГ. Для генерации подойдут GigaChat или YandexGPT, оба доступны через API. Для эмбеддингов работают мультиязычные опенсорс-модели (модели с открытым исходным кодом), которые запускаются локально и не требуют передачи данных за рубеж. Весь пайплайн можно развернуть на собственном сервере.
По моим наблюдениям, главная ценность RAG нейросети в рекомендациях не в точности (коллаборативная фильтрация на большом массиве данных всё ещё выигрывает по метрикам), а в двух вещах: умении понять «атмосферный» запрос и способности объяснить выбор человеческим языком. Для авторов контента это означает, что можно перестать угадывать теги и начать описывать то, что ищешь, так, как описал бы другу.
Честная оговорка: RAG не заменяет рекомендательную систему с историей поведения миллионов пользователей. Он закрывает конкретный сценарий, «холодный запрос» на естественном языке, и делает это хорошо. Но если у вас уже есть зрелая коллаборативная модель и миллион оценок, RAG стоит добавлять как дополнительный вход, а не как замену.
Попробуйте собрать прототип на своём каталоге: 100 карточек, бесплатный Chroma, мультиязычная модель эмбеддингов и GigaChat через API. Два часа работы покажут, стоит ли масштабировать подход на ваш проект.
Хотите разобраться в нейросетях для контента?
В dzen.guru мы тестируем ИИ-инструменты и показываем, как применять их для Дзена и маркетинга.
Узнать больше
Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Allbirds продала обувь за $43 млн и стала платформой стартапов по искусственному интеллекту
Компания Allbirds, ещё в марте торговавшая кроссовками, в апреле 2025 года продала обувной бизнес за 43 миллиона долларов, привлекла 100 миллионов долларов на…

Как включить ИИ на Айфоне iOS 18: функции работают сами, настраивать почти нечего
Apple встраивает ИИ-функции прямо в привычные приложения iPhone, и чтобы включить их на iOS 18, не нужно осваивать нового ассистента: достаточно обновить…

Anthropic новости: Белый дом впервые принудительно отключил ИИ-модели компании
Anthropic второго июня лишилась двух флагманских моделей Fable 5 и Mythos 5 после того, как администрация Трампа применила к компании экспортный контроль,…
Комментарии