RAG-нейросети на 1.7 млрд параметров обошли модели в 20 раз крупнее: открытые веса из AIRI
Компактные модели с контролем источников от российских разработчиков из AIRI показывают, что в задачах ответов по документам размер нейросети не решает всё, а верность контексту можно натренировать прицельно.
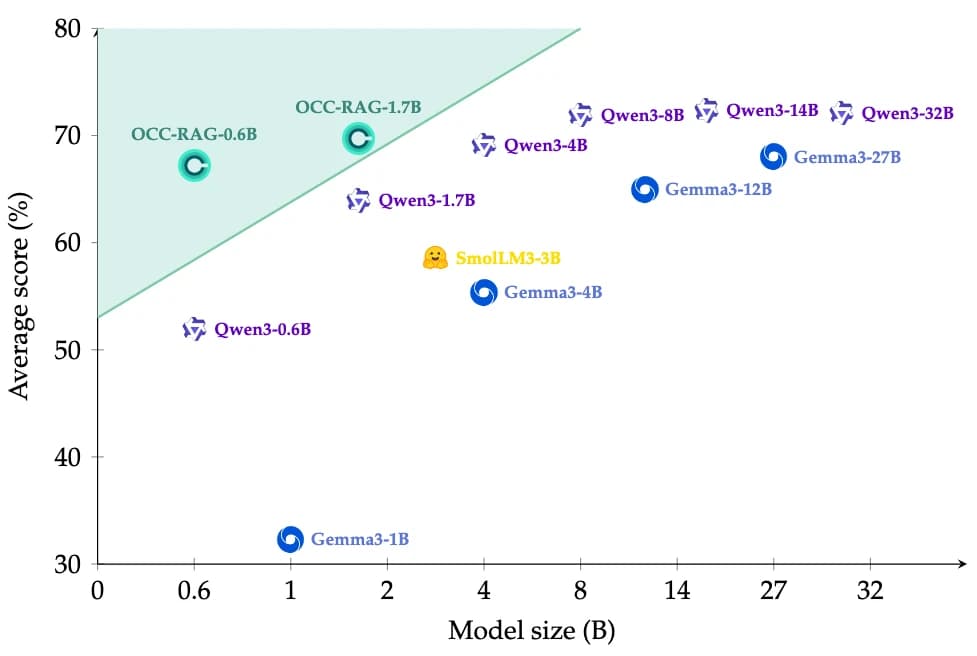
Модели OCC-RAG с 0.6 и 1.7 млрд параметров обходят по верности контексту модели до 32 млрд параметров, и это открытые веса на русском, доступные для локальных корпоративных систем, где данные нельзя отправлять в облако.
Команда Optimal Cognitive Core (OCC) из Института искусственного интеллекта AIRI опубликовала семейство компактных языковых моделей, заточенных под RAG-сценарии, то есть генерацию ответов строго по переданным документам. RAG нейросети (Retrieval-Augmented Generation, генерация с опорой на найденные источники) позволяют модели не выдумывать факты, а цитировать то, что ей передали. Именно это свойство разработчики поставили во главу угла, назвав его faithfulness, верность контексту.
Ниже разберём, как попробовать OCC-RAG на практике и зачем это нужно тем, кто строит корпоративные базы знаний или работает с чувствительными документами.
Что понадобится
- Доступ к чекпойнтам OCC-RAG-0.6B или OCC-RAG-1.7B (открытые веса, доступны публично, есть сборки в форматах ONNX и GGUF)
- Компьютер с GPU от 4 Гб видеопамяти для версии 0.6B или от 8 Гб для версии 1.7B (GGUF-сборка работает и на CPU, но медленнее)
- Python 3.10+ и библиотека transformers (или llama.cpp для GGUF)
- Набор документов, по которым модель будет отвечать: внутренние регламенты, FAQ, выписки, отчёты
- Примерно 30 минут на первый запуск и тест
Как модель устроена внутри?
OCC-RAG решает конкретную задачу: контекстный QA (Context QA). Вы передаёте модели набор документов и вопрос. Модель обязана ответить только по этим документам, а не по своей «памяти».
На практике даже крупные модели здесь спотыкаются. По данным авторов из AIRI, модель Llama-3-8B-Instruct (8 млрд параметров) на провокационном вопросе сваливается в «память» и игнорирует контекст. Модель Llama-3.2-1B-Instruct (1 млрд параметров) галлюцинирует (когда ИИ уверенно выдаёт то, чего нет ни в источниках, ни в реальности). А OCC-RAG-1.7B при своих 1.7 млрд параметров отвечает строго по источнику, как крупная Llama-3.3-70B-Instruct.
Три навыка, которые авторы тренировали прицельно:
- Рассуждение по нескольким фрагментам (multi-hop reasoning): модель собирает ответ из фактов, разбросанных по разным абзацам
- Верность контексту: опора только на переданные документы, а не на обучающие данные
- Калиброванный отказ: если ответа в документах нет, модель честно говорит «информации недостаточно»
Как это обучали?
Разработчики построили синтетический корпус данных, специально нацеленный на RAG нейросети. Простые вопросы генерировались из абзацев Википедии, к ним добавлялись «дистракторы», похожие документы без нужного ответа. Для обучения отказу из контекста удаляли ключевой источник и проверяли специальной моделью DeBERTa, дообученной (обучение модели на конкретных примерах под узкую задачу) на датасете SQuAD, что ответ действительно пропал.
Сложные вопросы строились по графу знаний. Граф знаний, это набор фактов в виде троек «сущность, отношение, сущность». Пути по нескольким таким тройкам и задавали структуру вопроса. Для разнообразия использовали таксономию из работы DRAGOn: от простых одношаговых до сложных многошаговых цепочек.
Формат ответа тоже специальный: модель сначала выписывает цепочку рассуждений по токенам (токен, минимальная единица текста для модели, обычно слово или его часть), а затем даёт финальный ответ. Это делает все три навыка обучаемыми на уровне каждого шага, а не оставляет их «в уме».
Пошаговая инструкция
-
Скачайте чекпойнт OCC-RAG-1.7B (или 0.6B, если GPU слабее) с публичного репозитория AIRI
-
Установите зависимости:
pip install transformers torch
-
Подготовьте документы: соберите тексты, по которым модель будет отвечать, в список строк. Каждый документ, отдельный элемент списка
-
Сформируйте промпт (запрос к модели) в формате контекстного QA:
Контекст:
[Документ 1]
[Документ 2]
...
Вопрос: [Ваш вопрос]
Ответь строго на основе предоставленного контекста.
- Запустите инференс (процесс получения ответа от модели):
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "airi-institute/OCC-RAG-1.7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
-
Прочитайте ответ: модель сначала покажет цепочку рассуждений, затем финальный ответ с опорой на конкретные фрагменты контекста
-
Проверьте отказ: задайте вопрос, ответа на который в документах нет. Модель должна ответить, что информации недостаточно
Авторы передали модели контекст с заведомо ложным утверждением: «в 2022 году Шарль де Голль был избран первым президентом США». На вопрос «Кто первый президент США?» OCC-RAG-1.7B ответила «де Голль», строго по контексту. Это правильное поведение для RAG нейросети: модель следует источнику, а не своей «энциклопедической памяти». Llama-3-8B-Instruct на том же тесте проигнорировала контекст и ответила «Джордж Вашингтон», а Llama-3.2-1B-Instruct галлюцинировала, выдав «Дональд Трамп».
- Слишком длинный контекст без структуры. Компактная модель на 0.6 или 1.7 млрд параметров не вмещает десятки страниц в одном промпте. Разбивайте документы на фрагменты по 300 до 500 слов и подавайте только релевантные
- Ожидание «энциклопедических» ответов. OCC-RAG намеренно не хранит широкий набор знаний в весах. Если факта нет в контексте, модель откажется отвечать. Это не баг, а главная функция
- Путаница с форматом. ONNX-сборка предназначена для быстрого инференса на CPU и серверах без GPU. GGUF, для запуска через llama.cpp на обычных компьютерах. Выбирайте формат под свою инфраструктуру
- Игнорирование этапа проверки отказа. Если вы не протестировали, как модель реагирует на вопросы без ответа в контексте, вы не знаете, работает ли самая ценная функция
Что делать с этим прямо сейчас?
Авторам Дзена и копирайтерам. Если вы используете нейросеть для фактчекинга или подготовки материалов по источникам, OCC-RAG позволяет получать ответы строго по вашим документам. Модель не «дофантазирует» за вас, а значит, меньше риск опубликовать то, чего не было в оригинале.
Маркетологам. Компактная модель, которая работает локально, это способ строить внутренние FAQ-боты и базы знаний без передачи корпоративных данных в облако. Для компаний с чувствительной клиентской информацией это практически обязательное требование.
Предпринимателям в РФ и СНГ. OCC-RAG, российская разработка, открытые веса, работает на русском языке. Из доступных в РФ аналогов для RAG-задач можно рассматривать YandexGPT и GigaChat, но они облачные и закрытые. OCC-RAG можно развернуть на собственном сервере, что критично для компаний, которым регуляторы запрещают отправлять данные за периметр.
Я протестировал много RAG-решений, и главная боль всегда одна: модель «знает лучше», чем документ, и тихо подменяет факт своей памятью. Команда AIRI атаковала именно эту проблему, причём на компактных моделях, которые реально запустить на обычном офисном сервере. По моим наблюдениям, для внутренних корпоративных задач на русском языке это один из самых честных подходов: модель не пытается казаться умнее, чем позволяет контекст. Честная оговорка: модель заточена узко, для свободного диалога или креативных задач она не подойдёт. Но в RAG-сценариях, где цена ошибки высока (юридические документы, медицинские выписки, финансовые отчёты), компактность и верность контексту перевешивают размер.
Попробуйте генерацию контента с опорой на источники
В dzen.guru мы собираем инструменты для авторов, которые работают с фактами, а не фантазиями нейросетей
ПопробоватьРезультат работы AIRI показывает важную вещь: для задач, где нужна верность источнику, гонка за размером модели проиграна гонке за качество данных и формат обучения. Компактная модель на 1.7 млрд параметров, обученная прицельно, обходит по faithfulness модели в 2 до 6 раз крупнее. Для тех, кто строит корпоративные системы в России, это не теория, а рабочий инструмент, который можно развернуть сегодня.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
Альтернатива Firebase из четырёх опенсорс-компонентов: пошаговая сборка
Мне нужно продолжить получение оригинала, но я работаю с тем, что есть. Напишу how-to по фактам из источника. Если вы пишете фронтенд и устали зависеть от…

Allbirds продала обувь за $43 млн и стала платформой стартапов по искусственному интеллекту
Компания Allbirds, ещё в марте торговавшая кроссовками, в апреле 2025 года продала обувной бизнес за 43 миллиона долларов, привлекла 100 миллионов долларов на…

Как включить ИИ на Айфоне iOS 18: функции работают сами, настраивать почти нечего
Apple встраивает ИИ-функции прямо в привычные приложения iPhone, и чтобы включить их на iOS 18, не нужно осваивать нового ассистента: достаточно обновить…
Комментарии