Microsoft открыла olmo-eval: оценка языковых моделей теперь встроена в каждый этап обучения
Microsoft второго июня выложила в открытый доступ olmo-eval, рабочий стенд для оценки языковых моделей на каждом этапе разработки, от первых экспериментов с данными до масштабирования готовой модели.

Большинство инструментов для оценки языковых моделей заточены под финальные тесты готовых продуктов. olmo-eval закрывает другую задачу: непрерывную проверку модели прямо в процессе обучения, когда каждая правка в данных или архитектуре требует нового замера. Для разработчиков в РФ, которые строят собственные модели, это сокращает рутину и убирает угадывание из цикла «поменял, проверил, сравнил».
Инструмент выпустил Allen Institute for AI (Ai2), исследовательская лаборатория, стоящая за серией открытых моделей OLMo и Tulu. olmo-eval продолжает их предыдущий проект OLMES (Open Language Model Evaluation Standard), стандарт оценки языковых моделей, появившийся в 2024 году. OLMES решал конкретную проблему: одни и те же модели на одних и тех же тестах получали разные баллы из-за различий в формате промптов (промпт, текстовая инструкция для модели) и формулировке задач. olmo-eval идёт дальше и покрывает весь цикл разработки, а не только финальный результат.
Что делает olmo-eval и чем отличается от аналогов?
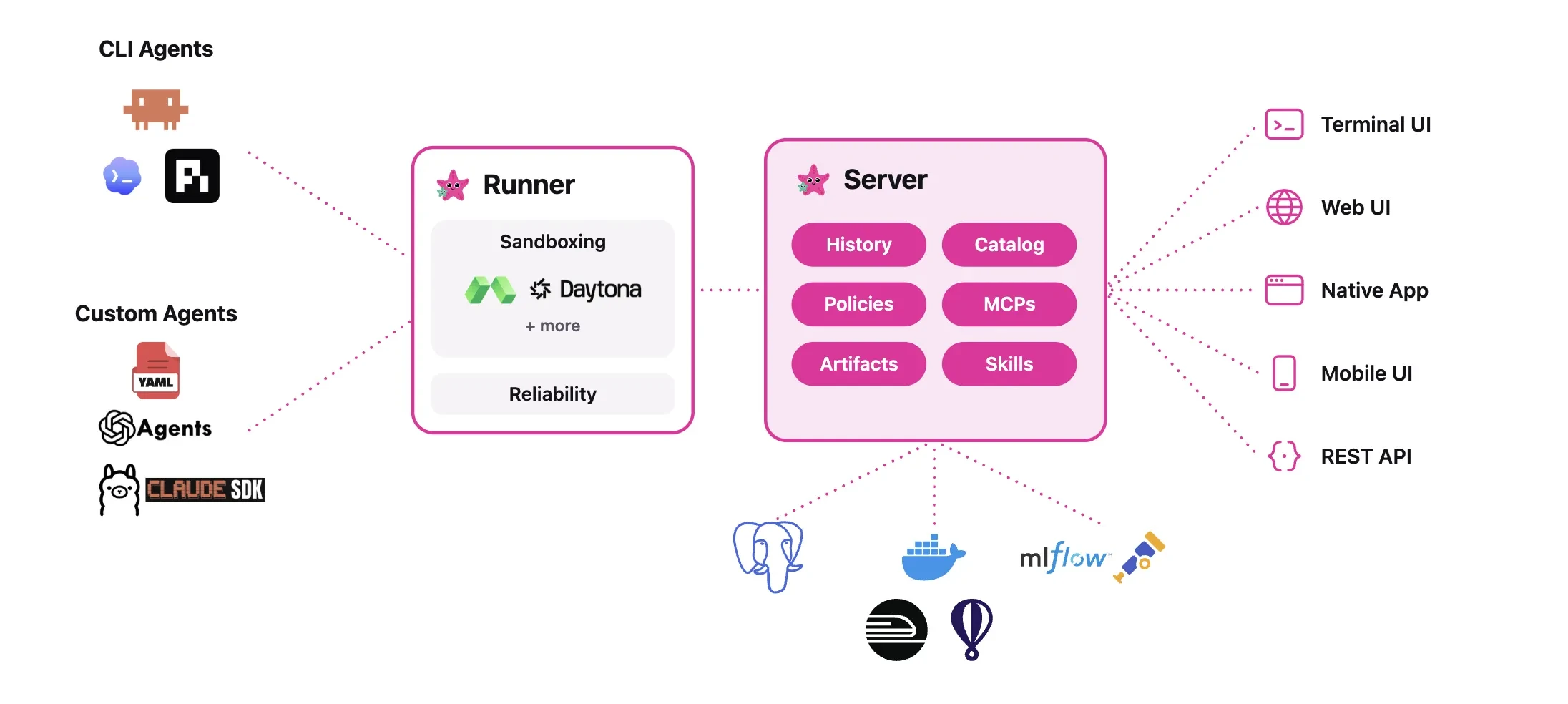
Инструмент состоит из четырёх компонентов, которые работают вместе, но могут использоваться и по отдельности.
- Абстракция «задача, набор, обвязка». Задача описывает, что именно проверяется. Набор группирует задачи для совместного запуска. Обвязка (harness) определяет, как запускать каждую задачу. Это разделение позволяет прогнать один и тот же тест и в базовом режиме, и с инструментами, не меняя саму метрику.
- Песочница и маршрутизация. Если модель должна написать и выполнить код или использовать веб-поиск, olmo-eval запускает эти инструменты и возвращает результат модели. Лёгкие тесты, где модель просто отвечает на вопросы, запускаются напрямую, без контейнеров, что быстрее и дешевле.
- Единая схема экспериментов. Каждый запуск, его настройки и результаты записываются в одном структурированном формате. Это позволяет группировать эксперименты, сравнивать контрольные точки во времени и не терять данные в длинных циклах разработки.
- Попромптовое сравнение. Вместо одного общего балла olmo-eval выстраивает одни и те же вопросы для двух версий модели и сравнивает ответы один к одному. Каждый балл сопровождается стандартной ошибкой и минимальным обнаруживаемым эффектом (наименьшая разница, которую можно надёжно отличить от шума). Это помогает понять, реальное ли улучшение вы видите или статистический шум.
Чем olmo-eval отличается от Harbor?
Авторы прямо сравнивают свой инструмент с Harbor, открытой платформой для оценки ИИ-агентов (ИИ-агент, программа, которая сама выполняет задачи, используя инструменты) в изолированных контейнерах. Разница в фокусе: Harbor предназначен для публикации готовых бенчмарков агентов, olmo-eval построен для ежедневной работы разработчика.
Harbor запускает всё внутри изолированных контейнеров, что ресурсоёмко. olmo-eval позволяет выбирать: простой тест идёт напрямую, контейнер подключается только когда тест действительно этого требует.
Добавление нового бенчмарка в Harbor предполагает шаги верификации для публичного использования. В olmo-eval процесс зависит от задачи: короткое описание для базового теста, обёртка для бенчмарка с собственным кодом, или настройка с инструментами. Все компоненты модульные: модель, инструменты, среда, модель-судья (LLM, которая оценивает ответы другой LLM) заменяются независимо друг от друга.
Одни и те же модели оценивались на одних и тех же бенчмарках по-разному: формат промптов и формулировка задач часто менялись от статьи к статье, поэтому заявления о том, какая модель лучше, зачастую не воспроизводились. : Команда Allen Institute for AI, блог на HuggingFace
Что это значит для вас?
Разработчику моделей в РФ и СНГ. olmo-eval позволяет стандартизировать оценку языковых моделей на каждом этапе обучения: от подбора обучающих данных (training data, набор текстов, на которых модель учится) до масштабирования. Вместо того чтобы собирать скрипты вручную, вы получаете единый стенд с попромптовым сравнением и статистикой шума. Инструмент открытый, код доступен, ограничений по региону нет.
Автору Дзена и копирайтеру. Напрямую вы этим инструментом пользоваться не будете. Но olmo-eval ускоряет цикл разработки открытых моделей (открытая модель, модель с опубликованным кодом и весами, которую может скачать и запустить любой), а значит, модели, которые вы используете для генерации текста, будут быстрее проходить проверку качества и реже выдавать галлюцинации (когда ИИ уверенно выдумывает то, чего не было).
Предпринимателю, который строит продукт на LLM. Если вы дообучаете (fine-tuning, обучение модели на ваших примерах под узкую задачу) открытую модель под свои нужды, olmo-eval даёт способ измерить, помогло ли изменение или навредило, до того как вы выкатите обновление пользователям.
Проблема, которую решает olmo-eval, знакома каждому, кто хоть раз сравнивал результаты двух моделей: цифры в таблицах разных авторов не бьются, потому что условия тестирования отличались. Ai2 последовательно закрывает эту дыру: сначала OLMES зафиксировал правила, теперь olmo-eval встроил эти правила в рабочий процесс. Для российского рынка, где команды строят модели на базе открытых весов (open weights, параметры модели, опубликованные для скачивания), это практичный инструмент. Оговорка: olmo-eval не заменяет оценку на русскоязычных бенчмарках, его придётся дополнять задачами на русском языке самостоятельно. Но каркас для этого он даёт.
Если вы разрабатываете или дообучаете модель, попробуйте встроить olmo-eval в свой цикл экспериментов прямо сейчас: код открыт, документация опубликована, а попромптовое сравнение двух чекпоинтов покажет, стоило ли последнее изменение потраченных GPU-часов.
По материалам HuggingFace

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Anthropic закрыл доступ к Claude в Индии за ночь: стартапы требуют $5 млрд на суверенный ИИ
Anthropic второго июня без предупреждения заблокировал доступ к своим новым моделям Fable 5 и Mythos 5 для всех иностранных пользователей, включая собственных…
Databricks открыла Omnigent: бесплатный фреймворк объединяет AI агентов под одним оркестратором
Databricks 13 июня выложила в открытый доступ Omnigent, фреймворк, который объединяет несколько ИИ-агентов (программ, самостоятельно выполняющих задачи) в одну…

Amazon сдала Anthropic Claude властям США: две модели отключены по всему миру
Amazon подняла тревогу по поводу моделей Anthropic Claude перед правительством США, и через несколько дней власти ввели экспортный контроль, а Anthropic…
Комментарии