Как превратить рабочий проект в статьи по машинному обучению для NeurIPS и ICLR
Машинное обучение научные статьи, публикации на ведущих конференциях, путь от идеи до принятой работы: всё это кажется недоступным, пока не разложишь процесс по шагам.
Мария Тихонова, исследователь из Sber AI, 3 июня 2025 года опубликовала подробный разбор того, как русскоязычные разработчики могут превратить свои рабочие проекты в научные статьи уровня A и A* и подать их на NeurIPS, ICLR или ACL.
Датасеты и бенчмарки (стандартные наборы задач для сравнения моделей) на русском языке критически нехватает, и это не слабость, а конкурентное преимущество: именно такие работы по машинному обучению заполняют пробел, который западные коллеги закрыть не могут.
Большинство специалистов в России создают ИИ-агентов (программы, которые сами выполняют цепочку действий), RAG-системы (поиск по базе знаний плюс генерация ответа), собирают данные и обучают модели, но останавливаются на посте в Хабре. По словам Тихоновой, разница между Хабром и публикацией на топовой конференции часто не в качестве исследования, а в умении правильно оформить результат.
Что понадобится
- Завершённый проект или сильный промежуточный результат: новый датасет, бенчмарк, комбинация методов с измеримым улучшением, SoTA-результат (State of the Art, лучший известный показатель на стандартном тесте).
- Доступ к порталу Conference Ranks для проверки ранга конференции.
- LaTeX-редактор (Overleaf или локальный) для набора статьи по шаблону конференции.
- Запас времени: по рекомендации Тихоновой, оценку срока на исследование нужно умножить на 2 или даже на 2,5, потому что написание текста занимает больше времени, чем сама работа.
- Английский язык на уровне, достаточном для научного текста, или помощь редактора.
Пошаговая инструкция
-
Определите, что именно нового вы привнесли. Не нужно было изобрести трансформер. Подойдёт новая комбинация известных методов, дающая более высокий результат. Новый датасет на русском языке. Исследование поведения моделей в нишевых условиях: устойчивость к атакам, знание культурного кода, поведение на чувствительных темах. SoTA-результат на известном бенчмарке с воспроизводимым методом. Хорошо задокументированная система с демонстрацией работы.
-
Выберите конференцию и формат. Тихонова предлагает ответить на пять вопросов:
- Соответствует ли тема профилю конференции?
- Какой уровень новизны: концептуально новая архитектура, улучшение существующего решения или новый датасет плюс модель?
- Какой объём работы: длинная статья для журнала или короткая для конференции?
- Формат результата: прикладное демо или теоретическая работа?
-
Укладываетесь ли вы в дедлайн конференции?
-
Проверьте ранг конференции на Conference Ranks. A* означает «исключительные», флагманские мероприятия. Для русскоязычных датасетов Тихонова рекомендует смотреть и на российские конференции, потому что такие работы в первую очередь интересны локальному сообществу.
-
Спланируйте время с запасом. Умножайте оценку на 2,5. Типичная ошибка: «У нас есть результаты, осталось только написать». Текст пишется итеративно и отдельно от исследования.
-
Структурируйте статью по стандартам конференции. Задайте себе вопросы, которые задаст рецензент: насколько корректен базовый уровень сравнения (baseline)? Что будет, если изменить гиперпараметр? Этот процесс, по словам Тихоновой, сам по себе повышает качество исследования.
-
Оформите код и данные для воспроизводимости. Загрузите код на GitHub, модель на HuggingFace. Рецензенты ценят прозрачность.
-
Отправьте статью до дедлайна, а не в последний момент. Тихонова называет это «крайне непопулярным подходом среди учёных», но настаивает на нём.
Допустим, вы собрали датасет для оценки того, как генеративные модели понимают русские идиомы. Вы протестировали на нём три открытые модели (открытые веса, то есть доступные для скачивания и проверки) и зафиксировали, что ни одна не справляется выше 40% точности. Это уже материал для статьи по машинному обучению: новый бенчмарк на русском языке плюс измеримый результат, который можно сравнить с английскими аналогами. Подаёте на Workshop (секцию для коротких работ) при ACL, потому что конференция специализируется на обработке языка. Ранг проверяете на Conference Ranks.
- Не указывать, что нового. Рецензент не будет угадывать вашу новизну. Если вы комбинируете известные методы, прямо напишите, какая именно комбинация раньше не проверялась.
- Недооценивать время на текст. По опыту Тихоновой, написание занимает больше, чем само исследование. Без запаса вы сдадите черновик вместо статьи.
- Игнорировать формат. Каждая конференция требует свой шаблон, лимит страниц, стиль цитирования. Несоответствие формату может привести к отклонению ещё до рецензирования.
- Бояться подавать. Тихонова подчёркивает: исследовательское сообщество настроено конструктивно, конференции, это про обсуждение, а не про критику ради критики.
- Забывать про визовые ограничения и логистику. Оцените заранее, сможете ли вы физически добраться до конференции.
Почему русскоязычные датасеты дают реальное преимущество?
Тихонова прямо рекомендует создавать бенчмарки на русском: их значительно меньше, чем на английском, и они нужны сообществу. Для авторов из России и СНГ это конкретный путь к публикации: западные исследователи физически не могут закрыть эту нишу, а рецензенты на международных конференциях ценят работы, расширяющие языковое покрытие.
Что делать с этим прямо сейчас, по ролям
Автору Дзена и контент-специалисту. Если вы работаете с нейросетями и пишете о них, формализация результатов в машинное обучение научные статьи добавляет вес вашей экспертизе. Статья на конференции, это не абстрактная «наука», а строчка в портфолио, которую невозможно отозвать.
Разработчику и дата-сайентисту. Пересмотрите свои проекты: комбинация методов, новый датасет, агентная система с нетривиальным поведением могут стать основой для подачи. Начните с Workshop-треков, у них ниже порог входа.
Предпринимателю в РФ и СНГ. Публикации сотрудников повышают репутацию компании и упрощают найм. Поддержите команду временем и оплатой участия. Для российских команд особенно перспективны работы с русскоязычными данными.
По моим наблюдениям, главный барьер для русскоязычных специалистов, не качество работы, а убеждённость, что «это не для нас». Тихонова работает в Sber AI и говорит из практики, а не из теории. Совет умножать время на 2,5 звучит банально, пока не попробуешь: я видел, как люди бросали статью за неделю до дедлайна именно потому, что текст оказывался сложнее кода. Честная оговорка: одной статьи по машинному обучению мало, рецензирование может занять месяцы, а отказ не означает, что работа плохая. Подавайте, получайте отзывы, дорабатывайте и подавайте снова.
Статья остаётся с вами навсегда, как напоминает Тихонова. Код на GitHub могут заархивировать, пост может затеряться, а принятая публикация на NeurIPS или ACL, это ваш вклад, который уже не отменить.
Прокачайте свой контент с dzen.guru
Если вы готовите экспертный материал и хотите, чтобы он работал на вашу репутацию, начните с инструментов dzen.guru для авторов Дзена.
Попробовать бесплатно
Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
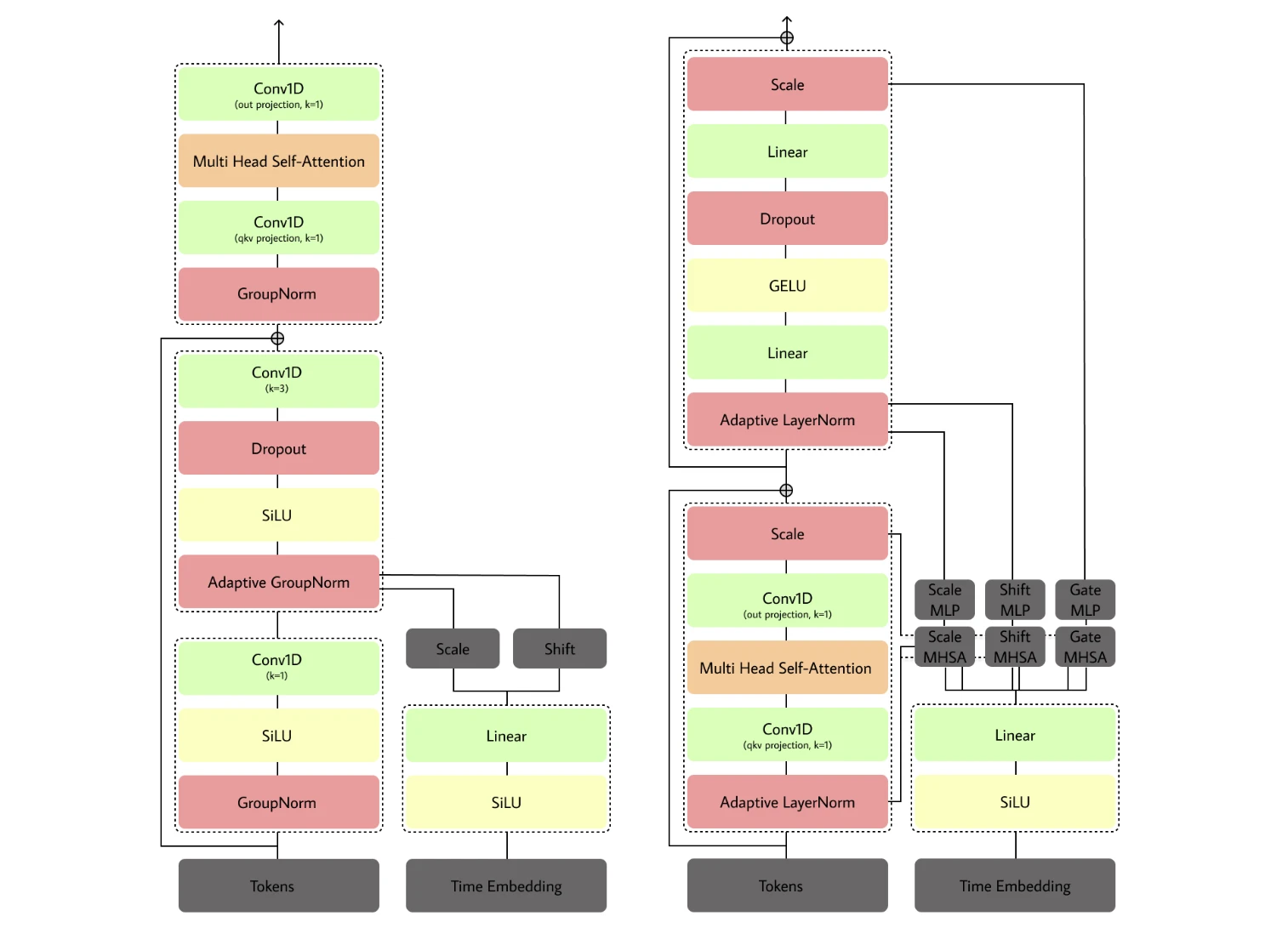
Яндекс ускорил text to speech нейросеть: как оптимизировали декодер для перевода видео
Разработчики Яндекса опубликовали детальный разбор оптимизации диффузионного декодера в пайплайне синтеза речи для перевода видео в Яндекс Браузере, где каждая…

Adobe купила Topaz Labs: ИИ для улучшения видео заработает без облака прямо на видеокарте
Adobe второго июня объявила о покупке Topaz Labs, компании с двадцатилетней историей, которая разработала технологию запуска тяжёлых ИИ-моделей прямо на…

Ford вернула 350 инженеров для исправления ошибок искусственного интеллекта на заводах
Ford 2 июня рассказала, как вернула более 350 опытных инженеров, чтобы исправить ошибки искусственного интеллекта и роботизированных систем на своих заводах, и…
Комментарии