Яндекс ускорил text to speech нейросеть: как оптимизировали декодер для перевода видео
Разработчики Яндекса опубликовали детальный разбор оптимизации диффузионного декодера в пайплайне синтеза речи для перевода видео в Яндекс Браузере, где каждая сэкономленная миллисекунда на генерации фразы ощутима в масштабах сервиса.
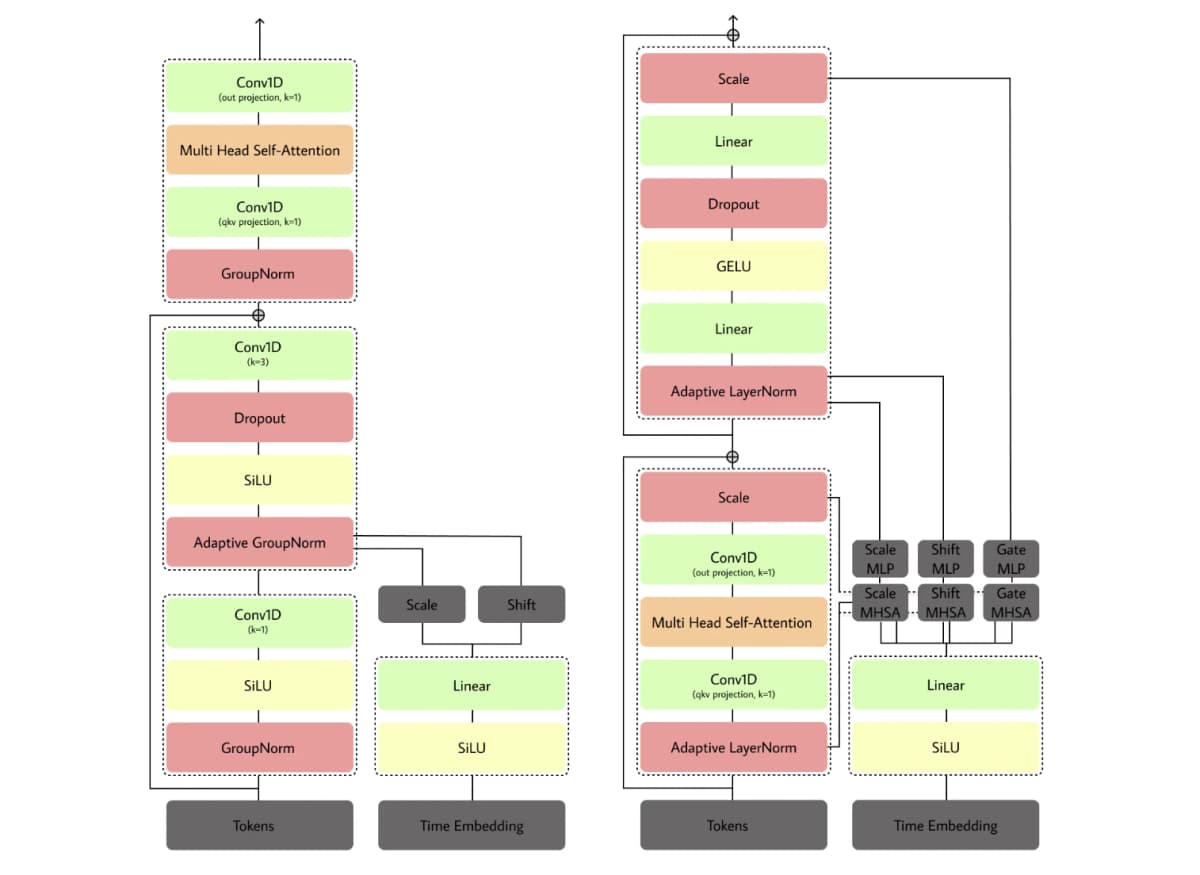
Синтез речи (text to speech нейросеть) в продакшене упирается не в качество голоса, а в скорость: декодер вызывается десятки раз на каждую фразу, и именно его оптимизация даёт наибольший выигрыш после того, как языковая модель уже ускорена.
Цырен-Доржо Цыбиков, ML-инженер команды TTS в Яндексе, и Даниил Маслов, студент МФТИ и ШАД, описали на Хабре исследовательскую ветку по ускорению диффузионного декодера латентов. Год назад та же команда рассказывала, как заменила старый многоголосый синтез на zero-shot TTS на базе переработанной архитектуры Tortoise. Теперь фокус сместился на один компонент: декодер, чей forward pass (прямой проход вычислений через сеть) запускается на каждом шаге сэмплинга диффузии.
Как устроен пайплайн и где узкое место?
Внутри TTS-пайплайна (text to speech нейросеть для перевода видео) работают три компонента:
- Языковая модель предсказывает аудиотокены (токен, минимальная единица данных, которую обрабатывает модель) по тексту.
- Диффузионный декодер восстанавливает мел-спектрограмму (визуальное представление звука, из которого можно воссоздать аудио) из латентов (внутренних представлений модели).
- Вокодер превращает спектрограмму в звуковую волну.
После оптимизации языковой модели самым тяжёлым стал именно декодер. Его ядро состоит из стека слоёв DiffusionLayer, каждый из которых включает residual-ветку (свёртки Conv1D, функцию активации SiLU и адаптивную нормализацию) и attention-блок (механизм внимания) с авторской реализацией QKVAttentionLegacy.
Что показало профилирование?
Команда запустила torch.profiler на инференсе (инференс, процесс генерации ответа обученной моделью) декодера в конфигурации, близкой к продакшену. Результат:
- Основное время уходит в
AttentionBlock, а внутри него вQKVAttentionLegacy. Матрица внимания материализуется целиком черезeinsum, и PyTorch не может заменить цепочку операций одним оптимизированным ядром. - На каждом forward pass заново строится
RelativePositionBias(обучаемое позиционное смещение, которое добавляется к логитам внимания перед softmax), хотя оно не зависит ни от шага диффузии, ни от конкретного сэмпла.
Именно эти два факта определили план оптимизации.
Что понадобится
- Python 3.10+, PyTorch с поддержкой SDPA (версия 2.0 и выше)
- GPU с поддержкой CUDA (для memory-efficient backend и FlashAttention)
torch.profilerдля замеров узких мест- Обученный чекпоинт модели на базе Tortoise
- Время: базовые оптимизации этапа 1 занимают от нескольких часов до пары дней, включая замеры
Пошаговая инструкция
1. Профилирование декодера
Запустите torch.profiler на инференсе декодера с реальным размером батча и длиной последовательностей. Цель: найти, какой именно блок съедает больше всего времени.
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
record_shapes=True
) as prof:
decoder(latents, timesteps, conditioning)
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=20))
2. Замена рукописного attention на SDPA
Перепишите QKVAttentionLegacy на вызов torch.nn.functional.scaled_dot_product_attention. Это позволяет PyTorch автоматически выбирать оптимальный backend: math, memory-efficient или FlashAttention.
import torch.nn.functional as F
# Было: ручной einsum с материализацией матрицы QK^T
# Стало:
attn_output = F.scaled_dot_product_attention(
query, key, value,
attn_mask=relative_position_bias # аддитивная маска
)
На этом шаге RelativePositionBias передаётся как attn_mask. Это совместимо с memory-efficient backend, но не с FlashAttention, потому что FlashAttention не поддерживает произвольную аддитивную маску из коробки.
3. Кэширование RelativePositionBias
Позиционное смещение при фиксированной длине последовательности одинаково для всех шагов диффузии и для всех элементов батча. Вычислите его один раз и переиспользуйте:
# Один раз при инициализации или при первом вызове с данной длиной:
cached_bias = self.relative_position_bias(seq_len)
# На каждом forward pass:
attn_output = F.scaled_dot_product_attention(
query, key, value,
attn_mask=cached_bias # не пересчитываем
)
Для последовательностей меньшей длины берите соответствующий срез уже посчитанной матрицы.
4. Планирование перехода на RoPE и FlashAttention
Замена RelativePositionBias на RoPE (Rotary Position Embedding, метод кодирования позиций, при котором координаты «вращаются» в пространстве модели) открывает путь к FlashAttention, потому что RoPE вшивается прямо в Query и Key и не требует отдельной маски. Этот шаг уже требует дообучения модели.
5. Дистилляция classifier-free guidance
На каждом шаге сэмплинга декодер делает два forward pass: с условием и без. Дистилляция (обучение компактной модели воспроизводить поведение большой) позволяет убрать второй проход, сократив вычисления вдвое на каждом шаге.
На этапе профилирования команда Яндекса увидела, что QKVAttentionLegacy с einsum занимает основную долю времени декодера. После замены на F.scaled_dot_product_attention с memory-efficient backend матрица внимания перестаёт материализоваться целиком: GPU-память освобождается, а PyTorch выполняет всю цепочку одним оптимизированным ядром вместо набора мелких кернелов. При этом веса модели остаются теми же, дообучение не требуется, и новую реализацию можно проверить на существующем чекпоинте без затрат на тренировочные кластеры.
- Пропуск профилирования. Без
torch.profilerвы оптимизируете наугад. Декодер может быть не самым медленным компонентом в вашем конкретном пайплайне. - Попытка сразу включить FlashAttention с RelativePositionBias. FlashAttention не поддерживает произвольную аддитивную маску. Результат: либо ошибка, либо молчаливый откат на медленный math-backend. Сначала memory-efficient, потом переход на RoPE.
- Забыть кэшировать позиционный bias. Пересчёт
RelativePositionBiasна каждом из десятков шагов диффузии для каждой фразы это чистая потеря, которую легко устранить одной строкой. - Менять архитектуру без замеров до и после. Каждый шаг оптимизации должен сопровождаться бенчмарком на фиксированном наборе фраз, иначе невозможно понять, дало ли изменение реальный выигрыш.
Что делать с этим прямо сейчас, по ролям
ML-инженерам, работающим с TTS. Начните с профилирования: запустите torch.profiler на своём декодере и посмотрите, где именно тратится время. Замена рукописного attention на SDPA и кэширование неизменных тензоров это действия, которые не требуют дообучения и дают результат в тот же день.
Авторам Дзена и контент-мейкерам. Если вы используете text to speech нейросеть для озвучки роликов или подкастов, вам полезно понимать: за скоростью генерации стоит не магия, а конкретные инженерные решения. Когда сервис озвучки работает быстрее, это значит, что кто-то прошёл именно такой путь.
Предпринимателям в РФ. Описанный подход применим к любому TTS-пайплайну на базе диффузионных моделей, не только к Tortoise. Если ваш продукт использует синтез речи и вы упираетесь в скорость, план «SDPA, кэширование, RoPE, дистилляция» это готовая дорожная карта для вашей ML-команды.
Этот разбор от Яндекса ценен не результатом (конкретные цифры ускорения в статье не приведены), а методом. Профилирование, выделение узкого места, оптимизации без дообучения, затем архитектурные изменения с дообучением. Такой порядок работает в любом ML-проекте, не только в TTS. Честная оговорка: шаги 1 и 2 (SDPA и кэширование) действительно можно сделать за день, но переход на RoPE и дистилляция guidance это полноценные исследовательские задачи на недели. Не ждите, что весь план реализуется быстро. Но первые два шага бесплатны в буквальном смысле: ни GPU-часов на дообучение, ни риска сломать качество.
Главное, что стоит забрать из этого разбора: прежде чем менять архитектуру или запускать дообучение, откройте профайлер и посмотрите, где именно ваша модель тратит время, потому что ответ почти всегда не там, где кажется.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
Google встроил искусственный интеллект в образовании: Gemini адаптирует уроки и даёт бесплатные экзамены
Google запускает в Gemini «учебные тетради», адаптивные уроки, которые подстраиваются под каждого студента по результатам диагностических тестов, и впервые…

Adobe купила Topaz Labs: ИИ для улучшения видео заработает без облака прямо на видеокарте
Adobe второго июня объявила о покупке Topaz Labs, компании с двадцатилетней историей, которая разработала технологию запуска тяжёлых ИИ-моделей прямо на…

Ford вернула 350 инженеров для исправления ошибок искусственного интеллекта на заводах
Ford 2 июня рассказала, как вернула более 350 опытных инженеров, чтобы исправить ошибки искусственного интеллекта и роботизированных систем на своих заводах, и…
Комментарии