Искусственный интеллект объясняет работу мозга: нейронаука получила метод проверки гипотез прямо в томографе
Компания Microsoft Research совместно с учёными из Калифорнийского университета в Беркли, Калифорнийского университета в Сан-Франциско и Колумбийского университета разработала метод, который превращает непрозрачные нейросетевые модели мозга в проверяемые научные гипотезы и подтверждает их прямо в томографе.
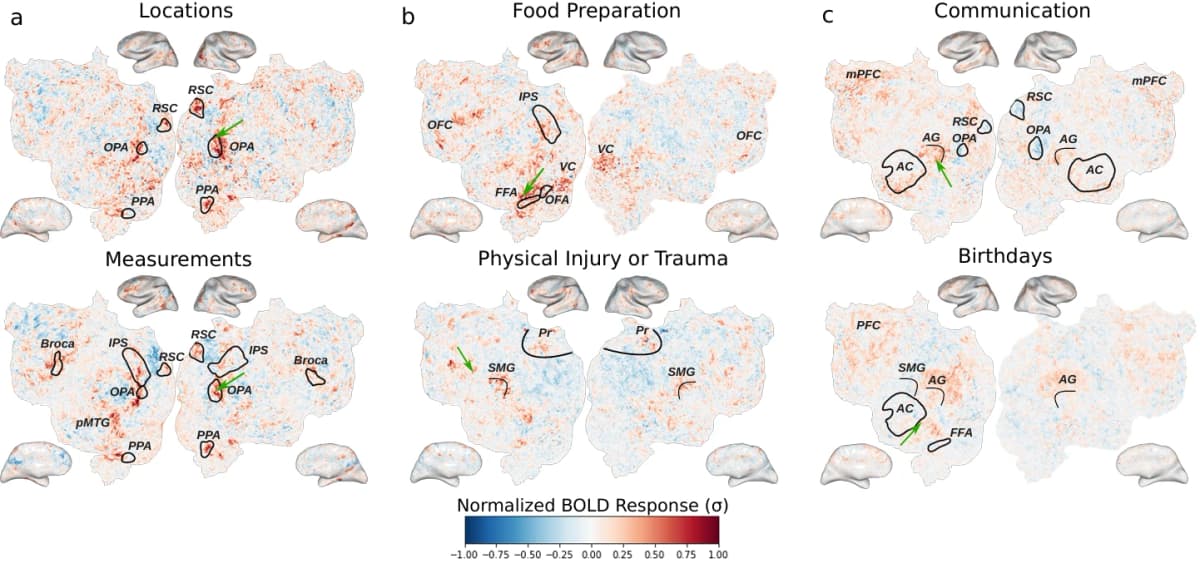
Впервые большая языковая модель не просто предсказывает активность коры мозга, а объясняет, на что именно реагирует каждый участок, и тут же доказывает это экспериментом на живых людях.
За последнее десятилетие большие языковые модели (LLM, модели вроде GPT, которые работают с текстом) стали лучшими инструментами для предсказания реакций мозга на речь. Но предсказание и понимание не одно и то же. Модель из миллионов параметров точно угадывает, какой участок коры «загорится», когда человек слышит рассказ, однако не может объяснить, почему: реагирует ли зона на еду, на названия мест или на числа. Статья об этом принята в журнал Nature Neuroscience, а метод назвали «генеративное каузальное тестирование» (Generative Causal Testing, GCT).
| Показатель | Значение | Источник |
|---|---|---|
| Название метода | Генеративное каузальное тестирование (GCT) | Nature Neuroscience |
| Участники разработки | Microsoft Research, UC Berkeley, UC San Francisco, Columbia University | Nature Neuroscience |
| Число испытуемых на этапе верификации | 3 человека | Nature Neuroscience |
| Что подтверждено экспериментально | Синтетические рассказы надёжно активировали целевые зоны коры у всех трёх испытуемых | Nature Neuroscience |
| Новые «микрорегионы» | Обнаружены ранее не описанные участки префронтальной коры, настроенные на диалог, время суток и числовые измерения | Nature Neuroscience |
Как устроен эксперимент?
Метод работает в два шага. Сначала берут нейросетевую модель, которая уже умеет предсказывать активность конкретного участка мозга. Из неё вытягивают короткие фразы, сильнее всего «возбуждающие» этот участок. Затем языковая модель сжимает их в одно читаемое объяснение: например, «приготовление еды» или «названия мест».
Второй шаг и есть главная новизна. Та же языковая модель пишет новые рассказы, специально сконструированные так, чтобы активировать нужную зону мозга, если объяснение верное. Испытуемые слушают эти рассказы в томографе (фМРТ, прибор, который фиксирует, какие области мозга «включаются» при обработке информации). Если целевая зона активируется заметно сильнее, чем при обычном тексте, гипотеза подтверждена не корреляцией, а причинно-следственной проверкой.
Что удалось обнаружить?
-
Синтетические рассказы сработали у всех испытуемых. Зоны, для которых были написаны «активирующие» тексты, реагировали значимо сильнее, чем на нейтральный текст. Чем точнее базовая модель предсказывала мозг, тем надёжнее срабатывало объяснение.
-
Разделены три зоны, которые раньше считали похожими. Ретросплениальная кора (RSC), парагиппокампальная область (PPA) и затылочная область мест (OPA) обрабатывают информацию о пространстве, но долго считались функционально взаимозаменяемыми. GCT создал «дифференциальные стимулы», рассказы, включающие одну зону и выключающие соседние. Выяснилось, что RSC реагирует сильнее на имена собственные мест (Токио, Коннектикут), а не на обобщённые описания локаций.
-
Найдены ранее неизвестные «микрорегионы» в префронтальной коре. Один настроен на диалог между людьми (слова «сказал», «ответил»), другой на упоминания времени суток («час дня»), третий на числовые измерения («50 футов»). Никто раньше целенаправленно не искал такие участки: они всплыли, потому что метод умеет предложить гипотезу и тут же проверить её.
Исследование проведено на трёх испытуемых, это стандарт для дорогих экспериментов с фМРТ, но маленькая выборка. Авторы показали воспроизводимость у каждого из трёх участников, однако масштабирование на большие группы ещё впереди. Метод зависит от качества базовой предсказательной модели: где модель слабая, объяснения тоже будут ненадёжными. Наконец, GCT проверен на восприятии речи на слух. Работает ли он так же для чтения, зрения или музыки, пока неизвестно.
Что делать с этим прямо сейчас?
Исследователям нейробиологии, в том числе в России: метод превращает «чёрный ящик» (модель, которая выдаёт результат, но не показывает логику) в цепочку «гипотеза, текст, сканер, ответ». Если у вас есть доступ к фМРТ и открытой языковой модели, вы можете воспроизвести подход и проверить собственные гипотезы о локализации функций коры. Искусственный интеллект в нейронауке перестаёт быть просто инструментом прогноза и становится генератором проверяемых теорий.
Авторам и копирайтерам: исследование показывает, что мозг реагирует на текст не «в целом», а микроучастками, каждый из которых настроен на свой тип информации: диалог, числа, названия мест. Это перекликается с практикой: тексты, в которых чередуются конкретные цифры, прямая речь и географические привязки, физически задействуют больше зон коры. Не рецепт волшебного заголовка, но аргумент в пользу разнообразия деталей.
Разработчикам ИИ-продуктов: GCT показывает рабочий способ объяснять поведение больших моделей. Тот же принцип (объясни, сгенерируй проверочный пример, измерь) применим не только к мозгу, но и к любой задаче, где нужна интерпретируемость модели, от медицинской диагностики до модерации контента.
Искусственный интеллект в нейронауке обычно упоминают как метафору: «нейросеть работает как мозг». Здесь всё наоборот: нейросеть помогает понять настоящий мозг и при этом объясняет саму себя. По моим наблюдениям, для российских лабораторий это один из немногих методов, который можно воспроизвести без проприетарных данных: нужна открытая языковая модель, доступ к сканеру и готовность писать синтетические стимулы на русском. Главный вызов как раз в языке: все эксперименты проведены на английском, и перенос на русский потребует отдельной валидации. Но сам каркас «объясни, сгенерируй, проверь» универсален, и я ожидаю, что первые русскоязычные реплики появятся в ближайший год.
Метод GCT не решает все проблемы объяснимости разом, но делает конкретный и проверяемый шаг: модель больше не просто угадывает, а формулирует гипотезу, которую можно опровергнуть. Для науки это принципиально, потому что неопровержимое предсказание не является теорией, а опровержимое уже наука.
По данным Nature Neuroscience / Microsoft Research

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Открытые модели кодирования Ornith 1.0 сами пишут себе обвязку: 82.4 на SWE-Bench
Компания DeepReinforce выпустила Ornith-1.0, семейство открытых моделей кодирования, которые сами создают себе инструменты вместо использования готовых…

Macy's встроила ИИ в розницу от поиска до логистики: пошаговая модель для любого ритейлера
Розничная торговля переживает тихую, но глубокую перестройку: крупные сети вроде американской Macy's переходят от точечных экспериментов с нейросетями к тому,…
Alibaba скопировала модель Claude
Alibaba, по данным Anthropic, провела крупнейшую атаку на Claude: 28,8 млн запросов через 25 000 поддельных аккаунтов за полтора месяца, чтобы скопировать…
Комментарии