Гибридные модели ИИ лучше предсказывают смысл, но хуже копируют: данные AI2 на 7 млрд параметров
Гибридные модели ИИ, архитектура, которая совмещает механизм внимания трансформера с рекуррентными слоями (слоями, читающими текст последовательно и сжимающими контекст в фиксированную память), предсказывают смысловые токены лучше классических трансформеров, но уступают им на буквальных повторах из текста, и понимание этой разницы поможет вам осознанно выбирать архитектуру, если вы обучаете или дообучаете собственную языковую модель.
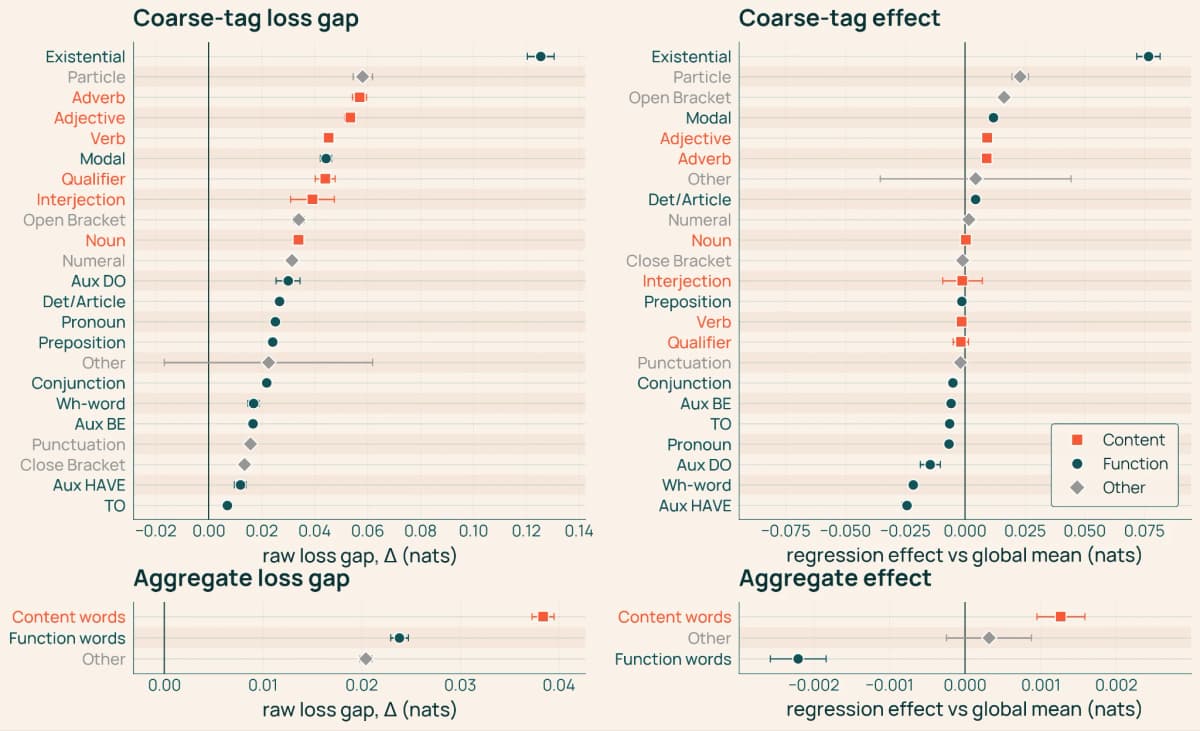
Команда AI2 впервые детально сравнила предсказания гибридной и трансформерной моделей одинакового размера (7 млрд параметров) на уровне отдельных токенов (единиц текста, на которые модель разбивает входные данные), и результаты показывают, где именно гибриды сильнее, а где нет.
Исследование проведено на моделях OLMo 3 (трансформер) и OLMo Hybrid (гибрид), которые команда Allen Institute for AI намеренно сделала максимально похожими по обучающим данным, токенизатору и рецепту обучения. Единственное различие между ними, сама архитектура. Это значит, что любая разница в предсказаниях отражает именно архитектурный выбор, а не качество данных или объём обучения.
Что понадобится
- Базовое понимание того, что такое токен и как языковая модель предсказывает следующее слово
- Доступ к открытым весам OLMo (модели опубликованы, веса доступны для скачивания)
- Для воспроизведения экспериментов: GPU-сервер, способный запустить модель на 7 млрд параметров (подойдёт карта с 24 ГБ видеопамяти)
- Время на чтение и осмысление: 10 минут
Как устроен эксперимент и что из него извлечь?
-
Возьмите две модели одного размера, но разной архитектуры. OLMo 3 построена целиком на механизме внимания (attention). OLMo Hybrid заменяет большую часть слоёв внимания рекуррентными слоями, которые читают текст слева направо и несут сжатую память фиксированного размера. Несколько слоёв внимания при этом остаются.
-
Подайте на вход одинаковые тексты. Команда использовала статьи, записи из Википедии, книги, научные работы, а также структурированный текст: код на Python, HTML и LaTeX.
-
Замерьте вероятность правильного следующего токена у каждой модели. Обе модели видят одни и те же предшествующие токены и назначают вероятность каждому возможному продолжению. Записывается вероятность того токена, который реально стоит следующим.
-
Посчитайте разницу потерь (loss gap). Положительная разница означает, что гибрид предсказал лучше. Отрицательная означает, что лучше справился трансформер.
-
Разбейте токены по категориям. Исследователи группировали токены по частям речи (существительные, глаголы, прилагательные, служебные слова вроде «the», «of», «is») и по контексту (повторяющийся фрагмент, открывающая или закрывающая скобка).
-
Проверьте результат регрессией. Средний показатель по категории может быть искажён редкостью категории или частотой повторов. Поэтому команда дополнительно провела регрессионный анализ, чтобы выделить эффект самой категории при прочих равных.
Где гибриды выигрывают, а где проигрывают?
Гибридные модели ИИ предсказывают смысловые слова лучше, чем трансформер. Существительные, глаголы, прилагательные и наречия, всё, что несёт содержание предложения, гибрид угадывает точнее.
Служебные слова («the», «of», «is») обе модели предсказывают почти одинаково. Разница потерь на них близка к нулю: любая архитектура почти безошибочно восстанавливает грамматический каркас.
Гибрид также сильнее на токенах, требующих отслеживания состояния. Например, определить, к кому относится местоимение, можно только если модель «помнит», что происходило в тексте последовательно. Рекуррентный слой, который складывает каждый новый токен в сжатую память, справляется с этим лучше.
Трансформер берёт реванш на буквальных повторах. Если следующий токен просто воспроизводит фрагмент, уже встречавшийся в тексте, механизм внимания находит его напрямую, как поиск по индексу. Чем длиннее повторяющийся фрагмент, тем меньше преимущество гибрида, пока оно не приближается к нулю.
Закрывающие скобки (но не открывающие) тоже нивелируют разницу. Механизм внимания хорошо решает задачу сопоставления парных скобок, и рекуррентные слои здесь ничего не добавляют.
Почему рекуррентные слои сильнее на смысловых токенах?
Слой внимания сравнивает текущий токен с каждым предыдущим. Это мощный механизм для извлечения конкретного факта из длинного контекста, но его стоимость растёт с длиной входа. При этом внимание хуже справляется с информацией, которая меняется последовательно: кто сейчас действует, какое настроение у абзаца, какой аргумент развивается.
Рекуррентный слой читает токены по порядку и обновляет фиксированную память. Память сжатая и «с потерями»: точный токен из начала текста он может не воспроизвести. Зато он хорошо ведёт «бегущий счёт» изменений. Именно поэтому предсказание содержательных слов, зависящих от контекста и логики повествования, ему удаётся лучше.
Что делать с этим прямо сейчас?
Если вы обучаете собственную модель и ваша задача связана с генерацией связного текста (статьи, сценарии, аналитические отчёты), гибридная архитектура даст лучшее качество на смысловых токенах при том же размере модели.
Если задача связана с точным извлечением фрагментов (цитирование, поиск по документу, повторение структурированных блоков), чистый трансформер по-прежнему предпочтительнее.
Авторам на Дзене и копирайтерам. Понимание этой разницы пригодится при выборе модели для генерации черновиков. Когда выйдут доступные гибридные модели для массового пользователя, они будут сильнее именно в смысловой части текста, но могут хуже воспроизводить длинные цитаты или шаблоны.
В России открытых гибридных моделей уровня OLMo Hybrid пока нет. Из доступных в РФ крупных языковых моделей работают YandexGPT и GigaChat, обе построены на трансформерной архитектуре. Следить за появлением гибридных архитектур стоит через репозитории открытых моделей на Hugging Face.
Моделям подали абзац из статьи, где слово «нейробиолог» встречалось в начале, а через два предложения шло местоимение «он». OLMo Hybrid точнее предсказала, что следующий глагол относится к тому самому нейробиологу, потому что рекуррентный слой «донёс» контекст. OLMo 3 в том же месте дала более размытое распределение вероятностей. Но когда в конце абзаца дословно повторилась фраза из начала, трансформер восстановил её точнее: механизм внимания нашёл совпадение напрямую.
- Не считайте, что «гибрид лучше во всём». На задачах с буквальным копированием и на замыкании скобок трансформер не уступает или побеждает.
- Не переносите результаты для моделей на 7 млрд параметров автоматически на модели другого размера. Исследование проведено на конкретной паре OLMo, масштабирование может изменить баланс.
- Не путайте «рекуррентный слой» с классическими RNN (рекуррентными нейросетями) десятилетней давности. Современные рекуррентные слои в гибридах (например, на основе архитектур Mamba или RWKV) устроены иначе и обучаются параллельно.
Я считаю это исследование ценным не столько выводами (они ожидаемы для тех, кто следит за архитектурами), сколько методом. Команда AI2 показала, как сравнивать модели не по средней оценке на бенчмарке, а на уровне каждого токена с контролем переменных. Для тех, кто в России экспериментирует с дообучением, это готовая схема: берёте две модели, одинаковые во всём, кроме одного параметра, и смотрите, где именно расходятся предсказания. Честная оговорка: гибридные модели ИИ пока остаются нишевым выбором. Массовые API (GPT, Claude, Gemini) работают на трансформерах, и переход к гибридам в коммерческих продуктах, вопрос не месяцев, а лет.
Попробуйте генерацию контента с нейросетями
В dzen.guru мы собираем рабочие промпты и инструменты для авторов, которые используют ИИ в работе на Дзене
Перейти к инструментамРезультаты AI2 дают конкретный ориентир: если ваша задача про смысл и связность, гибридная архитектура уже обыгрывает трансформер при равных ресурсах, а если про точное воспроизведение, трансформер пока надёжнее, и выбор архитектуры стоит делать, отталкиваясь от задачи, а не от моды.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Macy's встроила ИИ в розницу от поиска до логистики: пошаговая модель для любого ритейлера
Розничная торговля переживает тихую, но глубокую перестройку: крупные сети вроде американской Macy's переходят от точечных экспериментов с нейросетями к тому,…
Alibaba скопировала модель Claude
Alibaba, по данным Anthropic, провела крупнейшую атаку на Claude: 28,8 млн запросов через 25 000 поддельных аккаунтов за полтора месяца, чтобы скопировать…

Amazon вложит $13 млрд в инфраструктуру Индии: инвестиции в искусственный интеллект достигли $48 млрд
Amazon в четверг объявила о дополнительных инвестициях в размере 13 млрд долларов в расширение ИИ-инфраструктуры и облачных мощностей в Индии до 2030 года,…
Комментарии