ChatGPT размечает каждый источник скрытым тегом: SEO-специалист перехватил 1 240 записей
ChatGPT не просто «ищет в интернете»: под каждым ответом лежит JSON-разметка с полями, которые показывают, откуда именно пришёл каждый источник, и 3 июня 2025 года SEO-специалист Том Зугек опубликовал разбор этой механики на основе реального сетевого трафика.
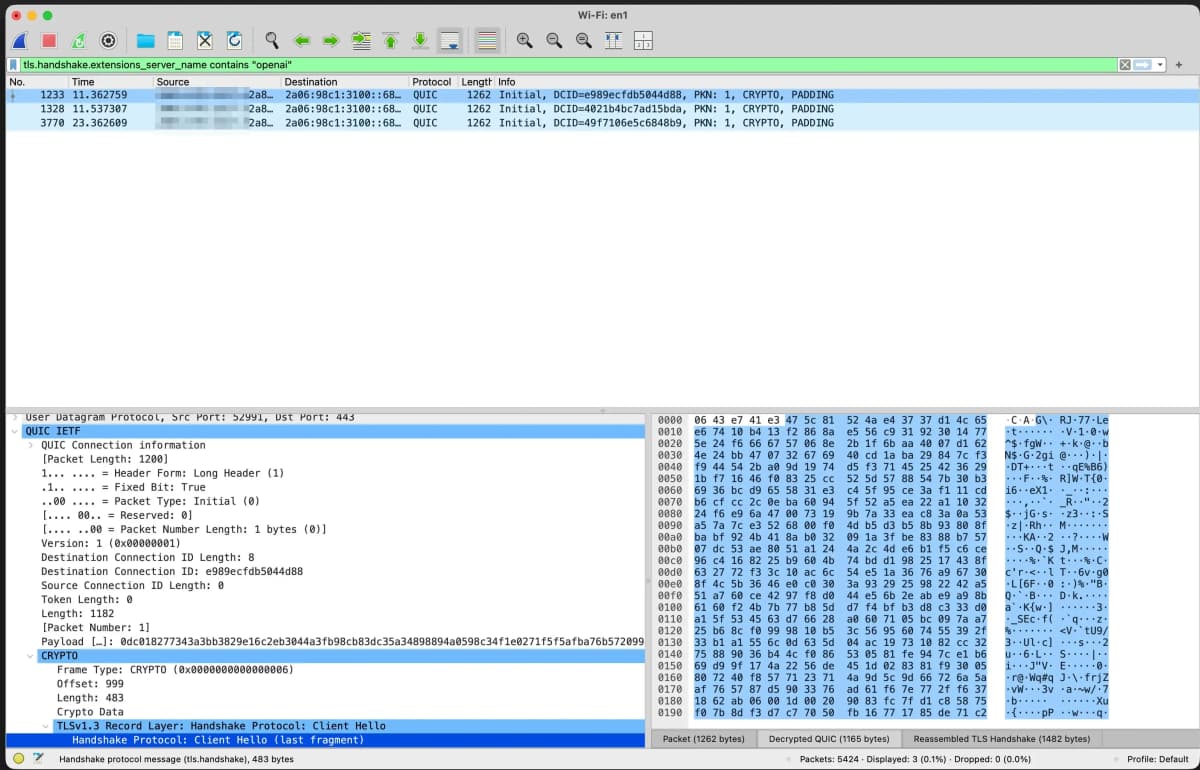
Впервые кто-то показал не «какие сайты упоминает ChatGPT», а какие внутренние метки он ставит на каждый результат и через каких поставщиков данных получает информацию. Для тех, кто продвигает сайты, это карта, а не догадка.
До сих пор советы «как попасть в ответы ChatGPT» передавались по цепочке: один эксперт цитировал другого, никто не заглядывал под капот. Том Зугек, SEO-консультант, потратил несколько дней на чтение сетевого трафика между браузером и серверами ChatGPT. Он перехватил около 1 240 записей об источниках и задокументировал поля, которые ChatGPT использует для классификации каждого результата. Ниже разбираем, что он нашёл и как это применить.
Что понадобится
- Браузер Chrome с открытой панелью DevTools (вкладка Network)
- Аккаунт ChatGPT (в исследовании использовалась подписка Pro)
- Включённая опция Preserve log в DevTools, чтобы записи не пропадали при обновлении страницы
- 30 минут на эксперимент и анализ JSON-ответов
Как ChatGPT размечает источники: пошаговая инструкция
-
Откройте DevTools. В Chrome нажмите F12, перейдите на вкладку Network, поставьте галочку Preserve log.
-
Задайте ChatGPT обычный вопрос с веб-поиском. Подойдёт любой запрос, где модель полезет в интернет, например «лучшие CRM для малого бизнеса».
-
Найдите поле
result_source. В ответах сервера (JSON) ищите объекты с полямиattribution,url,snippet,pub_dateиresult_source. Это поле стоит на каждом веб-результате, который ChatGPT подтянул, но пользователю оно не показывается. -
Определите значение метки. Зугек обнаружил четыре значения:
-
serpозначает обычную поисковую выдачу, классический веб-поиск labradorозначает лицензированный контент, сайты, подписавшие контентные сделки с OpenAI (крупные издания уровня национальных газет)brightозначает данные от Bright Data, коммерческого поставщика веб-данных-
oxylabsозначает данные от Oxylabs, другого поставщика веб-данных -
Посмотрите поле
turn_use_case. Зугек нашёл шесть значений этого поля. Оно определяет, как ChatGPT классифицирует ваш запрос: нужен ли веб-поиск или модель ответит из «головы». Запросы с меткойtextвообще не обращаются к вебу. -
Обратите внимание на подзапросы. Когда включён режим рассуждений (Thinking), ChatGPT генерирует десятки дополнительных поисковых запросов, включая запросы вида
site:и проверки цен. Это видно в том же сетевом трафике. -
Зафиксируйте домены-лидеры. В выборке Зугека (SaaS и технологические запросы) Reddit оказался самым цитируемым доменом, а YouTube практически не попадал в источники. Причина механическая: Reddit это текст, который легко процитировать, YouTube это видео, из которого модель берёт только метаданные.
Почему Reddit лидирует, а YouTube нет?
Здесь работает не популярность, а формат. ChatGPT цитирует текстовый контент, потому что может вставить фрагмент в ответ. Видео он «видит» только через заголовок и описание, поэтому YouTube-ролики почти не появляются как источник ответа. Для авторов Дзена это прямая подсказка: текстовый контент с конкретными ответами имеет больше шансов попасть в выдачу ИИ, чем видео без текстовой расшифровки.
Зугек честно предупреждает: его выборка состоит из нескольких десятков запросов по SaaS-тематике на одном аккаунте. Процентные соотношения (например, «70 % результатов через Bright Data») нужно воспринимать как направление, а не как точное измерение. Структурные находки, сами поля и их значения, надёжны: поле либо существует, либо нет, и Зугек видел их многократно.
Зугек задал ChatGPT вопрос из категории технических обзоров. В JSON-ответе один из источников выглядел так:
{
"attribution": "TechRadar",
"url": "https://www.techradar.com/best/...",
"snippet": "...",
"pub_date": "2026-05-09",
"result_source": "labrador"
}
Метка labrador означает, что TechRadar входит в число лицензированных партнёров OpenAI. Рядом в том же ответе были источники с метками bright и serp, то есть ChatGPT комбинирует каналы получения данных в одном ответе.
Что делать с этим прямо сейчас, по ролям
SEO-специалисту и владельцу сайта. Теперь вы знаете, что ChatGPT размечает источники по каналам. Если ваш сайт попадает через serp, вы конкурируете с обычной поисковой выдачей. Проверьте свой сайт: откройте DevTools и посмотрите, появляется ли ваш домен в ответах ChatGPT и с какой меткой.
Автору Дзена и копирайтеру. Текстовый контент со структурированными ответами, списками, сравнениями, конкретными рекомендациями, имеет механическое преимущество. ChatGPT цитирует текст, не видео. Пишите материалы, из которых легко вырезать фрагмент.
Маркетологу и предпринимателю в РФ. Данные о том, что ChatGPT использует Bright Data и Oxylabs как поставщиков, означают: ваш сайт должен быть доступен для веб-краулеров (программ, которые автоматически обходят сайты и собирают данные). Если вы заблокировали ботов в robots.txt, ChatGPT может просто вас не увидеть. В России chatgpt источник информации часто обсуждают абстрактно, теперь есть конкретная механика.
Для тех, кто работает с CRM-системами вроде OkoCRM (okocrm.com) и подобных российских сервисов: проверьте, индексируются ли ваши справочные страницы и блог. Именно такие тексты, с ответами на конкретные вопросы, ChatGPT подтягивает чаще всего.
Не путайте структуру с частотой. Зугек нашёл четыре метки result_source, это факт. Но доля каждой метки в его выборке отражает только его запросы, а не «среднюю по рынку». Не цитируйте проценты из этого исследования как универсальную статистику.
Не начинайте с Wireshark. Зугек пробовал перехватывать пакеты сетевым анализатором и признаёт: это не работает, потому что трафик зашифрован (TLS). Читаемые данные лежат уже в браузере, после расшифровки, в панели Network.
Не используйте автоматизированный браузер. Зугек пытался запустить автоматический Chrome и быстро получил блокировку от Cloudflare (системы защиты от ботов). Работайте в обычном браузере со своей сессией.
Не забывайте про стриминг. Ответ ChatGPT приходит через долгоживущее соединение, открытое при загрузке страницы. Если вы подключите DevTools после загрузки, вы можете не увидеть ответ. Включайте Preserve log заранее.
Исследование Зугека ценно не процентами, а тем, что оно впервые документирует конкретные поля и поставщиков данных. По моим наблюдениям, большинство советов «как попасть в ответы ИИ» до сих пор строились на обратной логике: смотрели на выдачу и гадали о механизме. Здесь подход обратный, и он честнее.
Честная оговорка: это данные одного человека с одного аккаунта за несколько дней. OpenAI может менять поставщиков и метки в любой момент. Но сам факт, что ChatGPT не просто «гуглит», а получает данные через коммерческих поставщиков вроде Bright Data и Oxylabs, важен для понимания: ваш контент проходит минимум два фильтра, поисковую выдачу и краулеры поставщиков данных, прежде чем стать источником ответа.
Знание механики не гарантирует попадание в ответы ChatGPT, но избавляет от главного: работы вслепую. Откройте DevTools, задайте вопрос из вашей ниши и посмотрите, кого ChatGPT цитирует прямо сейчас, это займёт десять минут и покажет больше, чем месяц чтения чужих гайдов.
Проверьте, как ИИ видит ваш контент
Инструменты dzen.guru помогают авторам адаптировать тексты под новые каналы дистрибуции, включая ИИ-поиск
Попробовать бесплатно
Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Локальный маркетинг это инфраструктура, а не реклама: 89% CMO не окупили вложения в технологии
Локальный маркетинг перестаёт быть набором ручных задач по филиалам: 89% руководителей признают, что их инвестиции в технологии не окупились, а главной…

Мета описание, которое Google не перепишет: инструкция с промптом для ИИ
Мета описание для страницы в поисковой выдаче решает одну задачу: показать человеку, что он найдёт после клика, и сделать это так, чтобы Google не переписал…
CTR, что это в рекламе: почему ИИ-стратегии ставок обесценили главную метрику кликов
Десять лет назад эталонным CTR (click-through rate, доля кликов от показов) для поисковой рекламы без бренда считались 2%, и этот ориентир так глубоко врос в…
Комментарии