Бенчмарки нейросетей по биологии: лучшая модель OpenAI решила лишь 36% задач
OpenAI выпустила LifeSciBench, бенчмарк из 750 научных задач по биологии, на котором даже лучшая модель справляется лишь с каждой третьей задачей, что показывает реальный разрыв между ИИ и учёным.

Бенчмарки нейросетей обычно проверяют память на факты, а LifeSciBench впервые оценивает способность рассуждать как биолог: взвешивать неполные данные, проектировать эксперимент и формулировать вывод со свободным ответом, а не выбором из вариантов.
Большинство существующих тестов для ИИ в биологии задают узкие вопросы с единственным правильным ответом. Настоящая научная работа устроена иначе: учёный оценивает неполные данные, принимает решения в условиях неопределённости и выстраивает цепочку рассуждений. OpenAI опубликовала LifeSciBench, бенчмарк, который целится именно в этот разрыв. По данным технического описания, источником является сама OpenAI, а оценку проводили на пяти моделях.
| Показатель | Значение | Источник |
|---|---|---|
| Число задач | 750 | OpenAI, LifeSciBench |
| Число критериев оценки | 19 020 (около 25 на задачу) | OpenAI, LifeSciBench |
| Доля задач с многошаговым рассуждением | 79%, в среднем 4 шага | OpenAI, LifeSciBench |
| Число экспертов-составителей | 173 (все с Ph.D.) | OpenAI, LifeSciBench |
| Число рецензентов | 453 (97% с докторской степенью) | OpenAI, LifeSciBench |
| Приложенные артефакты | 1 062 (53% задач требуют хотя бы один) | OpenAI, LifeSciBench |
| Лучший результат по прохождению задач | 36,1% (GPT-Rosalind) | OpenAI, LifeSciBench |
| Задачи, не решённые ни одной моделью | 171 (22,8%) | OpenAI, LifeSciBench |
Что именно проверяет LifeSciBench?
Бенчмарк (набор тестовых заданий для оценки нейросети) устроен не как экзамен с галочками, а как рабочий бриф коллеге-учёному. 750 задач охватывают семь рабочих процессов: работа с доказательствами, анализ данных, проектирование и оптимизация, научное рассуждение, валидация, трансляция результатов и научная коммуникация.
Области тоже семь: от геномики и медицинской химии до клинических и трансляционных исследований.
Ответ свободный, не множественный выбор. 79% задач требуют нескольких шагов рассуждения, в среднем четырёх. К задачам приложены реальные артефакты: последовательности генов, графики, таблицы, PDF-файлы, химические структуры.
Каждую задачу писали учёные с Ph.D. и опытом в биотехнологиях или фармацевтике. Одна задача проходила в среднем шесть автоматических проверок и минимум два экспертных ревью. Согласие рецензентов по релевантности, обоснованности и полезности превысило 96%.
Рубрика вместо «правильного ответа»
Главная механика LifeSciBench: оценка идёт не по единственной эталонной строке, а по рубрике (набору атомарных критериев). Всего 19 020 критериев на 750 задач, примерно по 25 на задачу.
Каждый критерий проверяет одно конкретное свойство: упомянут ли факт, выполнен ли шаг рассуждения, попал ли числовой ответ в допустимый диапазон.
Из оценки выводят два показателя:
- Нормализованный балл: сколько баллов модель набрала от максимума. Допускает частичный зачёт.
- Прохождение задачи: порог 70%. Ответ может набрать баллы, но при этом не пройти задачу. Порог намеренно строгий.
Это разделение позволяет видеть, где модель «почти справляется», а где проваливается полностью.
Как выступили модели?
OpenAI тестировала пять моделей в режиме одного запроса: модель видела задачу и артефакты один раз, с доступом к интернету.
- GPT-Rosalind, специализированная модель OpenAI для естественных наук, показала лучший результат: 36,1% задач пройдено. Она лидировала на 386 из 750 задач.
- GPT-5.5 прошла 25,7% задач.
- Gemini 3.1 Pro уникально лидировала на 214 задачах, хотя агрегированный балл ниже. Бенчмарки нейросетей по общему рейтингу не показывают, что на конкретных задачах другая модель может оказаться точнее.
Итого: ни одна модель не вышла за 36,1%. Результат далёк от «насыщения» теста.
Где модели буксуют?
Главные точки слабости по данным LifeSciBench:
- Артефакты: GPT-Rosalind проходила 45,1% задач без артефактов, но только 28,1% задач с артефактами. GPT-5.5 упала с 29,9% до 21,9%. Работа с графиками, таблицами и химическими структурами остаётся узким местом.
- Точные выходные данные: задачи на генерацию последовательностей и структур прошли на 18,0%-46,9% в зависимости от модели. Разница между GPT-Rosalind и GPT-5.5 на таких задачах составила всего +0,001.
- «Застревание» на середине задачи: у GPT-Rosalind 109 задач набрали минимум 50% баллов, но прошли менее чем в 20% случаев. Модель понимает часть логики, но не доводит рассуждение до конца.
- Непроходимые задачи: 171 задачу (22,8%) не прошла ни одна модель. 261 задача (34,8%) прошла у лучшей модели менее чем в 20% случаев.
Факт, что тест собран и модели оценены одной и той же компанией, стоит держать в голове при интерпретации: GPT-Rosalind создавалась с прицелом на такие задачи.
Бенчмарк охватывает семь областей биологии, но 750 задач не покрывают каждую специальность. Тест проводился в режиме одного запроса, тогда как реальная научная работа итеративна и многошаговая: учёный возвращается к данным, уточняет гипотезу, перепроверяет. Кроме того, LifeSciBench создан OpenAI, которая поставляет большинство оцениваемых моделей. Публичный доступ к бенчмарку может быть ограничен лицензионными условиями.
Что это значит для вас?
Авторам Дзена и копирайтерам: если вы используете нейросеть для подготовки материалов о медицине, генетике или фармацевтике, LifeSciBench подтверждает то, что стоит проговорить прямо: даже лучшая модель проваливает две трети научных задач. Опираться на ИИ-ответ по биологии без проверки экспертом опасно. Это аргумент и для ваших читателей: указывайте в тексте, что данные проверены специалистом, а не только «сгенерированы нейросетью».
Разработчикам и биоинформатикам в РФ и СНГ: бенчмарк полностью англоязычный и заточен под западные базы данных. Если вы работаете с локальными биобанками, химическими базами или медицинскими документами на русском, результаты LifeSciBench не переносятся напрямую. Модели, вероятно, покажут ещё более низкие результаты на русскоязычных данных, где обучающих примеров меньше. Из доступных в РФ аналогов (YandexGPT, GigaChat) ни один пока не тестировался на подобных научных бенчмарках.
Предпринимателям: прежде чем вкладываться в ИИ-продукт для фармы или биотеха, полезно знать реальный потолок. 36% прохождения у лучшей модели означает, что автоматизация научного анализа пока работает как помощник, а не замена учёному.
LifeSciBench ценен не рейтингом моделей, а самим фактом: появился тест, который не даёт нейросети списать за счёт зубрёжки фактов. Рубричная система с 25 критериями на задачу, это подход, который я хотел бы видеть и в оценке текстовых моделей для контента. Пока же вывод прагматичный: нейросеть в биологии умеет подсказывать, но не умеет завершать рассуждение. Для тех, кто работает с наукой на русском языке, дистанция ещё больше: ни данных, ни бенчмарков на русском пока нет.
Тот факт, что 171 задача не поддалась ни одной модели, а 109 задач «зависают» на полпути, показывает конкретное направление, куда пойдёт доработка: не общее «улучшение рассуждений», а способность доводить цепочку до конца, особенно при работе с таблицами, графиками и структурами. Для практиков это значит одно: проверяйте каждый научный вывод нейросети, как проверяли бы работу стажёра.
По материалам MarkTechPost

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

G7 потребовала гарантий: американский искусственный интеллект могут отключить любой стране за ночь
Мировые лидеры на саммите G7 17 июня потребовали гарантий, что Вашингтон не сможет в одностороннем порядке отключить их странам доступ к американскому…
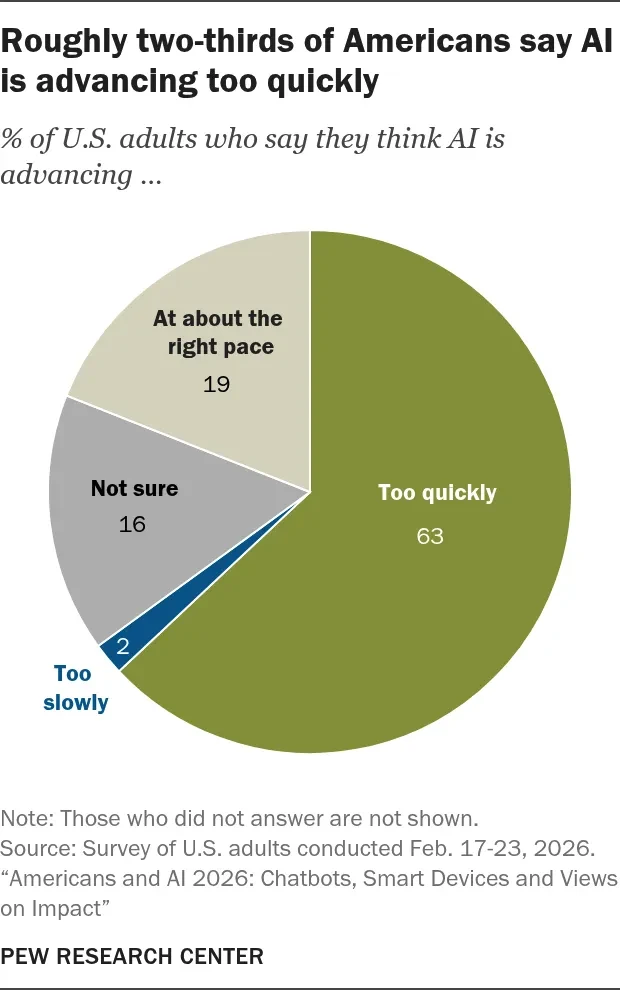
Парадокс в истории развития искусственного интеллекта: 49% американцев пользуются ИИ, но лишь 16% ему доверяют
Согласно новому исследованию Pew Research, 49% американцев пользуются чат-ботами хотя бы иногда, но две трети считают, что технология развивается слишком…
Pramaana Labs привлекла $27 млн на формальную верификацию ИИ в праве и фармацевтике
Pramaana Labs, стартап из сферы надёжности нейросетей, 18 июня привлёк $27 млн посевных инвестиций, чтобы применить формальную верификацию ИИ к областям, где…
Комментарии