Baidu открыла OCR-нейросеть на 3 млрд параметров: 40 страниц за проход без роста памяти
Baidu, китайская технологическая компания, 10 июня 2025 года выложила в открытый доступ Unlimited OCR, нейросеть для распознавания текста, которая обрабатывает десятки страниц за один проход без роста потребления памяти.
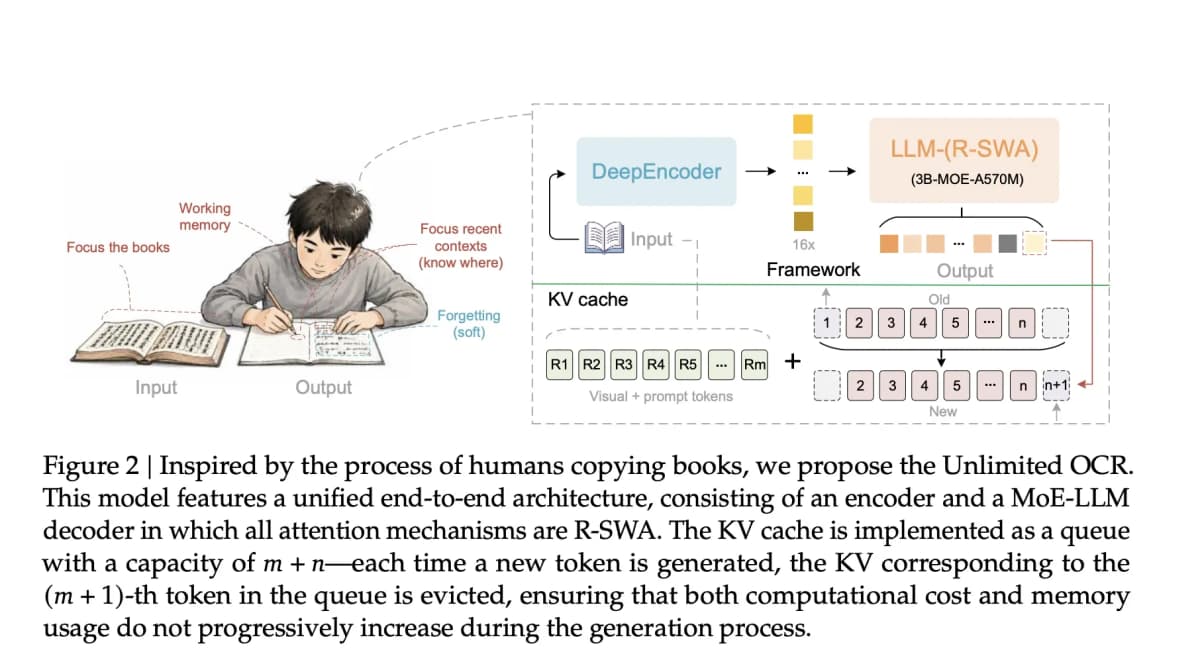
Большинство OCR-нейросетей (моделей для распознавания текста на изображениях и в документах) замедляются с каждой новой страницей: память растёт, скорость падает. Unlimited OCR решает эту проблему архитектурно, и модель выложена под открытой лицензией MIT.
| Что | Когда | Кто выпустил | Цена |
|---|---|---|---|
| Unlimited OCR, модель для распознавания текста в документах | Июнь 2025 | Baidu | Бесплатно, лицензия MIT |
Модель построена поверх DeepSeek OCR методом дообучения (обучения готовой модели на новых данных под узкую задачу): команда Baidu не создавала нейросеть с нуля, а продолжила обучение с контрольной точки DeepSeek OCR за 4 000 шагов. Это делает Unlimited OCR частью экосистемы DeepSeek, знакомой российской аудитории по доступным моделям этого разработчика.
Что умеет OCR-нейросеть Unlimited OCR?
-
Постоянный расход памяти. Обычные модели хранят ключи и значения для каждого обработанного токена (минимальной единицы текста для нейросети). Чем длиннее документ, тем больше памяти уходит. Unlimited OCR использует механизм R-SWA (Reference Sliding Window Attention), при котором модель «помнит» только исходное изображение и последние 128 сгенерированных токенов. Всё остальное вытесняется. Память не растёт.
-
Десятки страниц за один проход. Модель обрабатывает 40 и более страниц в одном прогоне при максимальной длине контекста 32 000 токенов. По данным исследования Baidu, на 40 страницах показатель edit distance (ошибка распознавания) остаётся ниже 0,11.
-
Только 500 млн активных параметров из 3 млрд. Модель использует архитектуру MoE (Mixture-of-Experts, «смесь экспертов», когда в каждый момент работает только часть нейросети). Это снижает требования к оборудованию при инференсе (процессе генерации ответа моделью).
-
Результат 93,23 балла на бенчмарке OmniDocBench v1.5. Это на 6,22 балла выше базовой модели DeepSeek OCR по данным статьи Baidu. На версии v1.6 результат ещё выше: 93,92 балла.
-
Прирост скорости на 12,7%. В базовом режиме модель выдаёт 5 580 токенов в секунду против 4 951 у DeepSeek OCR. По данным того же исследования, при длинных документах (порог 6 000 токенов на выходе) разрыв достигает 35%.
-
Распознаёт не только текст. Таблицы, формулы, порядок чтения извлекаются за один проход.
Как попробовать OCR-нейросеть онлайн и локально?
-
Скачайте модель с Hugging Face. Репозиторий называется
baidu/Unlimited-OCR. Открытые веса (файлы с параметрами модели, которые можно скачать и использовать на своём оборудовании) доступны бесплатно под лицензией MIT. -
Установите зависимости. Нужна библиотека Transformers с параметром
trust_remote_code=Trueи видеокарта с поддержкой CUDA. Для одной страницы используется режим Gundam (динамическое разрешение), для многостраничных документов и PDF вызывается режим Base при разрешении 1024. -
Для массовой обработки запустите сервер SGLang. В комплекте идёт скрипт
infer.py, который поднимает API, совместимый с OpenAI, и обрабатывает папку с файлами или PDF параллельными запросами. -
Учитывайте ограничения. Распознавание не безгранично: контекст ограничен 32 000 токенами. Многостраничный режим работает только в Base-разрешении, и мелкий текст может теряться. Применение для распознавания речи и перевода заявлено как направление будущих исследований, а не готовый результат.
Есть ли аналоги в России?
Для российских пользователей, которым нужна массовая оцифровка документов и архивов, ситуация такая:
| Параметр | Unlimited OCR (Baidu) | Доступные в РФ варианты |
|---|---|---|
| Тип | Открытая модель, запуск локально | YandexGPT и GigaChat умеют извлекать текст из изображений, но это не специализированные OCR-модели |
| Многостраничность | До 40+ страниц за один проход | Как правило, постраничная обработка |
| Стоимость | Бесплатно (нужна видеокарта) | По тарифам облачных API |
| Язык | Обучена преимущественно на документах; о поддержке русского языка Baidu не сообщала | Русский язык поддерживается нативно |
Главный вопрос для автора из РФ: насколько хорошо Unlimited OCR справляется с кириллицей. В статье Baidu этот момент не раскрыт. Если ваши документы на русском, перед переходом стоит протестировать модель на собственных файлах.
Что делать с этим прямо сейчас, по ролям?
Автору Дзена. Если у вас архив сканов, старых PDF или фотографий текста, Unlimited OCR может стать бесплатным инструментом оцифровки. Распознанный текст можно использовать как материал для статей, цитат, подборок. Проверьте на своих файлах, справляется ли модель с русским.
Маркетологу. Массовая обработка договоров, отчётов, каталогов в текст без ручного набора. Экономия заметна, когда счёт идёт на сотни страниц. При этом модель запускается локально, данные не уходят на сторонние серверы.
Предпринимателю в РФ и СНГ. Лицензия MIT позволяет использовать модель в коммерческих продуктах. Для запуска нужна видеокарта с поддержкой CUDA. Облачного API от Baidu для российских пользователей на момент публикации не заявлено.
OCR-нейросеть от Baidu технически интересна: постоянный расход памяти при длинных документах решает реальную боль. Я вижу прямое применение для тех, кто работает с архивами, оцифровывает книги, старые журналы, документацию. Но есть два момента, которые нужно проверить лично. Во-первых, качество на русском языке: модель дообучалась на данных, о языковом составе которых Baidu не рассказала. Во-вторых, 32 000 токенов это потолок, и на очень объёмных книгах придётся разбивать работу на части. Мой совет: скачайте модель, прогоните через неё десяток своих типичных документов и сравните с тем, чем пользуетесь сейчас. Если качество на кириллице устроит, это один из лучших бесплатных вариантов OCR-нейросети онлайн для пакетной обработки.
Частые вопросы
Unlimited OCR работает без интернета?
Да. Модель запускается локально после скачивания. Нужна видеокарта с поддержкой CUDA и библиотека Transformers. Данные не отправляются на серверы Baidu или куда-либо ещё.
Можно ли использовать модель в коммерческом проекте?
Да. Лицензия MIT разрешает коммерческое использование, модификацию и распространение без ограничений.
Модель справится с рукописным текстом или только с печатным?
В исследовании Baidu описана работа с документами: PDF, сканами печатных страниц, таблицами, формулами. О распознавании рукописного текста в статье не сказано. Если вам нужно распознавать рукописные записи, протестируйте отдельно и будьте готовы к ошибкам.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Gemini 3.5 Flash получил управление компьютером: агент видит экран и сам нажимает кнопки
Google встроила в Gemini 3.5 Flash управление компьютером: модель видит экран, рассуждает и сама нажимает кнопки в браузере, на десктопе и в мобильных…
Что такое ИИ-агент: собираем runtime с контролем токенов и бюджета с нуля
Компания или человек, написавший оригинальный код OpenHarness, не указаны в источнике как конкретный бренд или лицо. Источник представляет собой учебный…

Accenture раздула бюджет на ИИ конвертацией PDF: как не повторить её ошибку
Компания Accenture сначала грозила сотрудникам потерей повышений за неиспользование ИИ, а теперь вынуждена ограничивать доступ к нейросетям, потому что бюджет…
Комментарии