3 млрд параметров догоняют триллион: VibeThinker-3B решает олимпиады без облака и больших языковых моделей
Microsoft второго июня запустила VibeThinker-3B, компактную рассуждающую модель на 3 миллиарда параметров, которая на задачах по математике и коду догоняет модели в сотни раз крупнее и при этом помещается на одну бюджетную видеокарту.
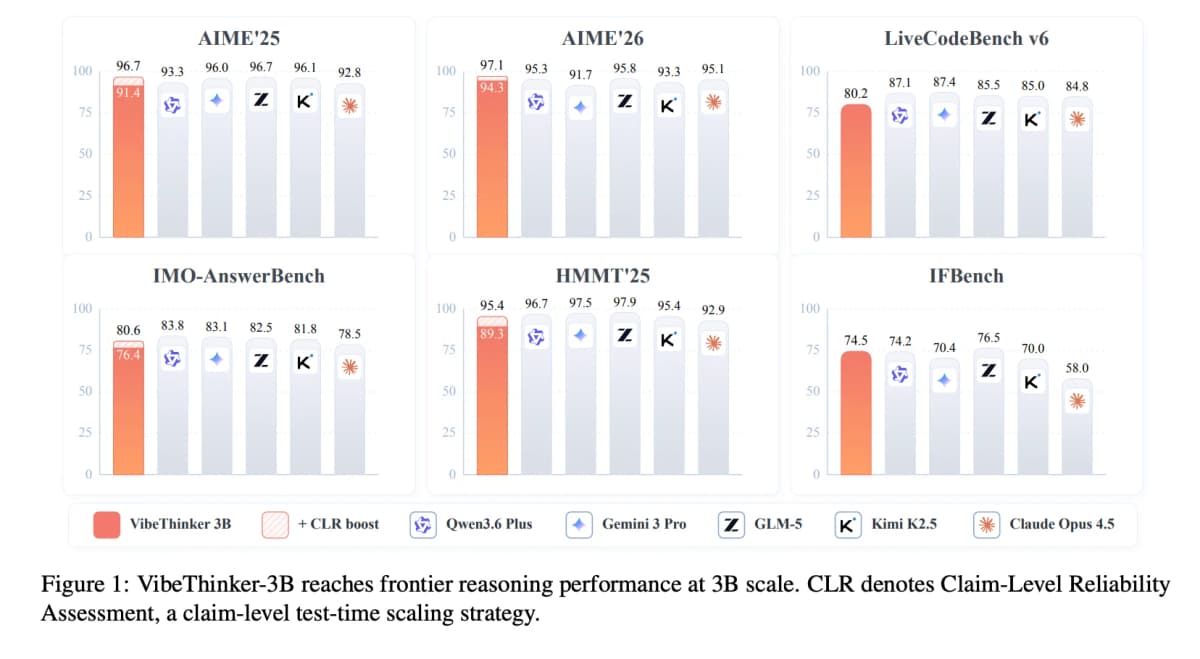
Модель с 3 миллиардами параметров показывает результаты на уровне гигантов с 671 миллиардом и триллионом параметров на проверяемых задачах, а весит около 6 ГБ, это реальный шанс запустить серьёзное логическое ядро локально, без облака и подписок.
Исследователи из Sina Weibo (Китай) выпустили VibeThinker-3B под открытой лицензией MIT. Модель построена поверх Qwen2.5-Coder-3B: её не обучали с нуля, а дообучили (fine-tuning, обучение модели на специальных примерах под узкую задачу) с помощью обучения с подкреплением и самодистилляции. Для русскоязычного сообщества это событие: впервые настолько компактная открытая модель (открытые веса, open weights) на китайской базе достигает уровня, который раньше требовал серверных кластеров.
| Показатель | Значение | Источник |
|---|---|---|
| Число параметров | 3 млрд | Исследование VibeThinker-3B |
| Размер весов (BF16) | около 6 ГБ | Исследование VibeThinker-3B |
| AIME26 (математика) | 94,3 | Исследование VibeThinker-3B |
| AIME26 с CLR (тестовое масштабирование) | 97,1 | Исследование VibeThinker-3B |
| LiveCodeBench v6 (код) | 80,2 Pass@1 | Исследование VibeThinker-3B |
| BruMO25 | 93,8 (99,2 с CLR) | Исследование VibeThinker-3B |
| HMMT25 (математика) | 89,3 | Исследование VibeThinker-3B |
| IMO-AnswerBench (400 задач уровня олимпиады) | 76,4 | Исследование VibeThinker-3B |
| LeetCode (свежие контесты, апрель-май 2026) | 96,1% принятых решений (123 из 128) | Исследование VibeThinker-3B |
| Лицензия | MIT (полностью открытая) | Исследование VibeThinker-3B |
Что именно измеряли?
Авторы проверяли модель на задачах, где ответ можно однозначно проверить: олимпиадная математика, алгоритмическое программирование, дисциплины STEM (наука, технологии, инженерия, математика). Идея проста: если задача имеет проверяемый правильный ответ, компактная модель способна конкурировать с гигантами. Для задач, где нужны обширные «мировые знания» (общие вопросы, открытые диалоги), авторы честно рекомендуют использовать большие языковые модели общего назначения.
Метод обучения называется Spectrum-to-Signal: сначала модели показывают широкий «спектр» допустимых путей решения, потом обучение с подкреплением усиливает правильные пути, «сигнал». Это не одноразовая тренировка, а конвейер из четырёх этапов: двухступенчатое дообучение с учителем, обучение с подкреплением по математике, коду и STEM, самодистилляция (когда модель учится у собственных лучших ответов), и финальная настройка на следование инструкциям.
Где VibeThinker-3B догоняет гигантов, а где нет?
Результаты на проверяемых задачах:
- AIME26 (олимпиадная математика): 94,3 балла. По данным исследования, это сопоставимо с DeepSeek V3.2 (671 млрд параметров) и Kimi K2.5 (1 трлн параметров).
- LiveCodeBench v6 (код): 80,2 Pass@1.
- LeetCode (свежие задачи за апрель-май 2026, которых модель не видела при обучении): 123 из 128 решений приняты с первой попытки, 96,1%.
- BruMO25: 93,8, а с тестовым масштабированием CLR поднимается до 99,2.
Где модель уступает:
- OJBench (сложный кодовый бенчмарк): 38,6, заметно ниже крупных моделей.
- GPQA-Diamond (задачи, требующие глубоких знаний): разрыв с большими языковыми моделями сохраняется. Авторы открыто признают: это специалист по проверяемым задачам, не универсал.
CLR: масштабирование без дополнительных параметров
CLR расшифровывается как Claim-Level Reliability Assessment, оценка надёжности на уровне утверждений. Представьте: модель решает задачу 32 раза, из каждого решения извлекает пять ключевых утверждений и сама же их проверяет. Одно слабое утверждение резко снижает вес всего решения. Затем ответы группируются, и побеждает ответ с наибольшим «весом надёжности».
Это не добавляет параметров: расход идёт на вычисления при использовании (инференс, inference, момент, когда модель генерирует ответ), а не на размер модели. CLR поднимает AIME26 с 94,3 до 97,1 и BruMO25 с 93,8 до 99,2.
Результаты впечатляют, но важны оговорки. Во-первых, сравнение с DeepSeek V3.2 и Kimi K2.5 приведено авторами исследования, независимого воспроизведения пока нет. Во-вторых, модель заточена под проверяемые задачи: на открытых вопросах, творческих текстах и диалогах она по замыслу авторов уступит универсальным большим языковым моделям. В-третьих, CLR-режим (32 прогона на задачу) многократно увеличивает вычислительную нагрузку: вы получаете точность, но тратите время и электричество. Наконец, тесты на LeetCode покрывают только Python, поведение на других языках программирования не проверялось.
Что делать с этим прямо сейчас?
Автору Дзена и копирайтеру. Прямого применения для текстов пока нет: модель не генерирует статьи и не работает с русским языком в задачах общего назначения. Но если вы пишете образовательный контент по математике, программированию или STEM, VibeThinker-3B может генерировать проверенные решения задач локально, без подписки на облачные сервисы.
Маркетологу и аналитику. Для тех, кто строит внутренние инструменты с элементами логики (калькуляторы, автопроверки, скоринг), модель размером 6 ГБ на одной видеокарте снижает порог входа. Вместо оплаты API крупных моделей можно развернуть локальное решение.
Предпринимателю в России и СНГ. Модель доступна под лицензией MIT, никаких санкционных ограничений. Веса на 6 ГБ помещаются на потребительскую видеокарту. Из российских аналогов для задач рассуждения стоит следить за YandexGPT и GigaChat, но они пока не предлагают открытых моделей сопоставимого размера для локального запуска. VibeThinker-3B, по сути, первая практичная альтернатива для тех, кто хочет запустить логическое ядро у себя, без облака и без зависимости от зарубежных API.
Я вижу в VibeThinker-3B не столько готовый рабочий инструмент для контентщика, сколько доказательство важного принципа: эпоха «чем больше, тем умнее» заканчивается. Три миллиарда параметров и грамотный пайплайн обучения дают результат, за которым полгода назад нужен был целый дата-центр. Для российского рынка это особенно ценно: у нас дорогие GPU, ограниченный доступ к облачным API, а спрос на локальные решения растёт. Если тренд продолжится и следующие версии подтянут качество на русском языке и открытых задачах, мы получим реальную альтернативу подпискам. Пока же рекомендую попробовать модель тем, кто работает с математикой и кодом: запуск через vLLM занимает пару команд в терминале, а результат может удивить.
Для запуска достаточно установить vLLM и одной командой поднять сервер, совместимый с API OpenAI. Весь процесс укладывается в три строки в терминале, и модель готова принимать запросы на той же машине, где вы работаете, без облачных затрат и без передачи данных на чужие серверы.
По данным исследования VibeThinker-3B

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Нейросети CIFAR на Cortex-M0+ теряют до 40% точности: пять багов и их исправления
Нейросети на микроконтроллерах ARM Cortex-M0+ теряют от 30 до 40 процентов точности из-за багов квантизации и особенностей компилятора GCC, и в этом разборе…

Минторг США обвинил ASML в утечке чипов в Китай, но не показал доказательств
Компания ASML (производитель литографического оборудования, без которого невозможно выпускать самые передовые чипы в мире) оказалась в центре конфликта с…

Midjourney строит сканер тела на 500 000 датчиков, а генератор картинок открыла бесплатно
Midjourney, компания, которую знают по генерации картинок, 4 июня 2025 года объявила о запуске медицинского сканера тела, работающего на ультразвуке и…
Комментарии