VK раскрыла архитектуру нейропоиска контента Discovery AI: ответ за 500 мс на петабайтах данных
Евгений Астафуров, ведущий разработчик отдела экспериментальных технологий AI VK, впервые описал внутреннюю архитектуру нейропоиска контента Discovery AI, обслуживающую петабайты данных Дзена, VK Видео и других сервисов с задержкой до первого ответа менее 500 миллисекунд.
VK раскрыла техническую начинку поисковой системы, которая будет поэтапно встроена в Дзен, VK, VK Видео и медиапроекты Mail, а значит, изменит то, как миллионы пользователей находят контент авторов на этих площадках.
До сих пор авторы и маркетологи видели только результат: лента рекомендаций показывала одни публикации и скрывала другие. Теперь команда AI VK опубликовала подробный разбор технологии нейропоиска контента изнутри. Источник публикации, статья Евгения Астафурова на Хабре. Это редкий случай, когда крупная российская платформа открывает архитектуру поиска и ранжирования до уровня конкретных цифр производительности.
Что стоит за Discovery AI?
Discovery AI это набор технологий для поиска, рекомендаций и взаимодействия с контентом внутри экосистемы VK. По словам разработчика, в него вошли:
- Нейропоиск контента на основе большой языковой модели (LLM, модель, обученная на огромных массивах текста и способная генерировать ответы).
- Анализ контекста и персонализация для подстройки выдачи под конкретного пользователя.
- Генеративные модели для формирования ответов.
- Рекомендательные алгоритмы, объединяющие всё перечисленное.
Технология работает с многомиллиардной контентной базой VK и будет поэтапно внедряться в Дзен, VK, VK Видео, медиапроекты Mail и другие сервисы.
| Что | Когда | Кто выпустил | Цена |
|---|---|---|---|
| Discovery AI, архитектура нейропоиска контента | Дата публикации статьи не указана, внедрение поэтапное | Отдел экспериментальных технологий AI VK | Бесплатно для пользователей и авторов платформ VK |
Как устроен нейропоиск контента внутри?
Система состоит из нескольких слоёв, каждый из которых отсеивает лишнее и оставляет релевантное.
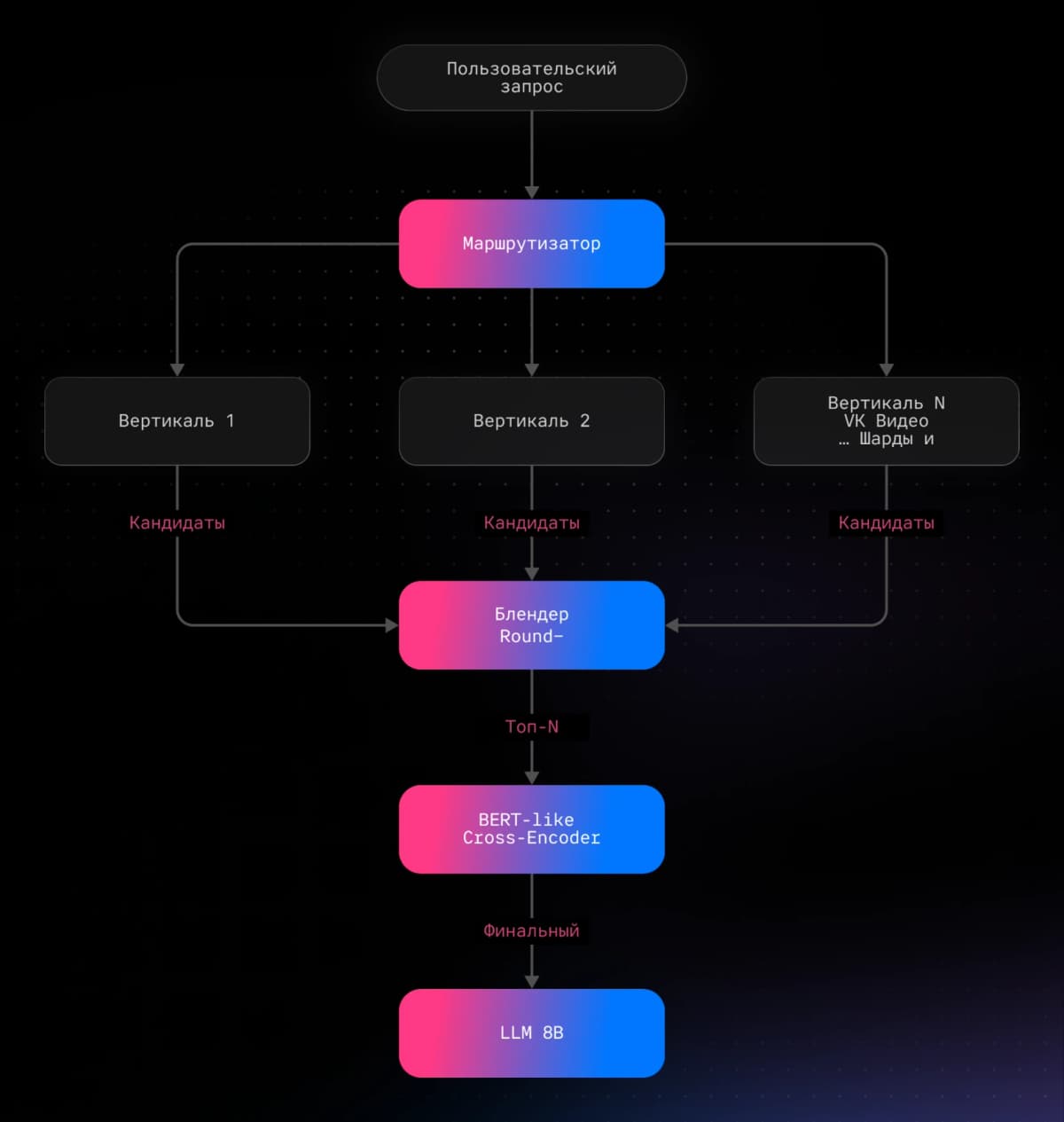
- Два типа поиска работают в паре. Текстовый поиск BM25 находит документы по точным словоформам и редким терминам. Семантический нейропоиск (ANN, Approximate Nearest Neighbors, поиск ближайших соседей) ищет по смыслу: понимает синонимы и размытые запросы. Вместе они покрывают весь спектр, от конкретного «как настроить монетизацию Дзена» до абстрактного «интересный контент про путешествия».
- «Блендер» смешивает результаты. Кандидаты из разных вертикалей (типов контента) объединяются через модифицированный алгоритм round-robin (механизм поочерёдного отбора). Каждому источнику присваивается динамический вес. Дубли и перезаливы удаляются.
- Нейросетевое «бутылочное горлышко». Даже после смешивания результаты ещё грубые. Специальная модель на основе BERT (трансформер, тип нейросети для понимания текста) режет каждый документ на фрагменты (чанки) до 320 токенов (токен, минимальная единица текста для модели, примерно одно слово или его часть), оценивает релевантность каждого фрагмента к запросу и формирует фиксированный контекст для LLM.
- Агентный сценарий Deep Research. Для сложных запросов создан многошаговый поиск и анализ, когда ИИ-агент (программа, выполняющая цепочку действий самостоятельно) последовательно ищет, проверяет и собирает ответ.
Какие оптимизации дали скорость менее 500 мс?
Главная цифра: задержка от отправки запроса до первого токена ответа составляет менее 500 мс. По данным статьи, модель обрабатывает до 5 тысяч документов (около 30 тысяч чанков) в секунду на одном GPU среднего потребительского уровня.
Ключевые решения, которые обеспечили такую скорость:
- Собственный токенизатор BPE (Byte-Pair Encoding, метод разбиения текста на токены), обученный на контенте из соцсетей и новостей. Фертильность (количество токенов на слово) составила 1,2, то есть 12 токенов на 10 слов текста, при словаре в 128 тысяч единиц. По данным Астафурова, это самая низкая фертильность среди всех открытых моделей для русскоязычного контента из соцсетей. Одна только эта оптимизация дала прирост скорости инференса (вычисления ответа моделью) примерно на 50%.
- Подбор гиперпараметров модели с учётом особенностей GPU: размерности, операторы и порядок исполнения настроены так, чтобы снизить эффект квантования волн (GPU Wave Quantization, потеря производительности из-за неоптимальной загрузки вычислительных блоков видеокарты).
- Синтетические датасеты из миллиардов размеченных примеров для обучения семейства BERT-подобных трансформеров.
Что это значит для тех, кто работает на платформах VK?
Авторам Дзена и VK. Нейропоиск контента Discovery AI будет определять, какие публикации пользователи увидят в поиске и рекомендациях. Система понимает смысл, а не только ключевые слова. Это значит: тексты, точно отвечающие на вопрос читателя, получат больше шансов на показ, даже если в них нет буквального совпадения с поисковым запросом.
Маркетологам. Персонализация и контекстный анализ меняют экономику продвижения. Покупать трафик «на ключевые слова» станет менее результативно, чем создавать контент, который отвечает на реальные запросы аудитории.
Предпринимателям в РФ. Discovery AI уже работает внутри VK и будет расширяться. Это полностью российская разработка, никакой зависимости от зарубежных сервисов и рисков блокировок.
Есть ли аналоги за рубежом?
| Параметр | VK Discovery AI | Google (поисковая система) |
|---|---|---|
| Семантический поиск | ANN плюс BM25, собственные BERT-модели | Собственные трансформеры |
| Работа с русскоязычным контентом соцсетей | Токенизатор обучен на соцсетях и новостях RU | Универсальный, без специализации |
| Доступность в РФ | Полностью доступен | Доступен, но ряд сервисов ограничен |
| Задержка до первого токена | Менее 500 мс (по данным VK) | Не раскрывается |
Прямое сравнение корректно только по архитектурным подходам, не по масштабу: Google обрабатывает весь интернет, Discovery AI работает внутри экосистемы VK.
Публикация VK примечательна не столько технологическими деталями, сколько самим фактом открытости. Российская платформа объясняет автору, как именно его контент находят и ранжируют. Для тех, кто публикуется на Дзене и VK, это практическое руководство: если система ищет по смыслу, а не по ключевым словам, значит, надо писать под реальный вопрос читателя, а не набивать текст «ключами».
Оговорка: конкретные сроки внедрения нейропоиска контента в каждый сервис VK не названы, технология описана как поэтапная. Цифры производительности приводит сам разработчик, независимых замеров пока нет.
Что сделать сегодня: откройте свои самые популярные статьи на Дзене и проверьте, отвечает ли первый абзац на конкретный вопрос. Если там общие слова, перепишите вступление так, чтобы поисковый нейропоиск контента сразу «увидел» ответ.
Частые вопросы
Нейропоиск контента уже работает в Дзене?
Технология разрабатывается внутри AI VK и, по словам Астафурова, будет поэтапно внедряться в Дзен, VK, VK Видео и медиапроекты Mail. Точные даты запуска для каждого сервиса не раскрыты.
Нужно ли авторам что-то менять в своих текстах?
Система ищет по смыслу, а не только по точным словам. Это значит, что тексты с чётким ответом на конкретный вопрос получат приоритет над материалами, просто набитыми ключевыми фразами. Менять стоит подход: начинайте публикацию с прямого ответа.
Можно ли использовать эти оптимизации в своих проектах?
Часть подходов, описанных Астафуровым (обучение токенизатора на собственных данных, оптимизация длины чанков, использование BERT-моделей для ранжирования), применима к любому поисковому проекту. Конкретный код и модели VK не опубликованы как открытые.
Для авторов и маркетологов, работающих на площадках VK, главный вывод прост: нейропоиск контента ставит смысл выше формулы. Пишите так, чтобы первый абзац отвечал на вопрос, а не обещал ответить позже.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Конференция HighLoad++ 2025 обнажила парадокс: компании внедряют ИИ-агентов, не меняя процессы
Я вижу проблему: H1 говорит «Конференция HighLoad++ 2026 об искусственном интеллекте», а формат задан как how-to. Но источник — это отчёт-обзор с конференции,…

AI-агенты в CAD ломаются на MCP: как граф из 47 000 узлов API решил проблему
Автоматизация проектирования в KOMPAS-3D силами ИИ-агента (программы, которая сама пишет и выполняет код) упирается не в возможности модели, а в архитектуру…

Альтернатива Microsoft Office с ИИ в ядре: индийский фаундер вложил $30 млн своих денег
Индийский серийный предприниматель Бхавин Турахия вложил 30 миллионов долларов собственных денег в Neo, платформу, которая заменяет привычный офисный пакет…
Комментарии