Сравнение LLM моделей Opus, GPT и Gemini: 11 задач через API без маркетинговых обещаний
Выжидаю окончание оригинала, но работаю с тем, что есть. Продолжаю по источнику:
Автору Дзена, маркетологу или предпринимателю часто нужно выбрать одну из флагманских нейросетей для рабочих задач, но маркетинговые обещания и синтетические бенчмарки мало говорят о реальном качестве, и сравнение LLM моделей на практических задачах экономит десятки часов проб и ошибок.
Anthropic, OpenAI и Google обновили флагманы почти одновременно, и разница между Claude Opus 4.8, GPT 5.5 и Gemini 3.1 Pro видна не в таблицах, а в конкретных сценариях: код, длинный контекст, стилизация, анализ данных, безопасность и стоимость за токен (минимальную единицу текста, которую модель обрабатывает).
Команда агрегатора BotHub провела сравнение LLM моделей через API (программный интерфейс, без веб-оболочки и её скрытых «подпорок»), подав одинаковые промпты всем трём моделям. Тест охватил 11 заданий в пяти блоках: кодинг, работа с длинным контекстом, стилизация перевода, аналитика и проверка на галлюцинации (когда модель уверенно выдумывает факты). Ниже пошаговая инструкция, как повторить такое сравнение самостоятельно и на что смотреть.
Что понадобится
- Доступ к API трёх моделей. Напрямую или через агрегатор вроде BotHub, который позволяет переключаться между моделями в одном окне и видеть стоимость каждого запроса.
- Набор тестовых задач. Минимум пять сценариев из разных категорий: генерация кода, суммаризация длинного документа, стилизация текста, анализ таблицы, проверка на галлюцинации.
- Одинаковый промпт для каждого теста. Формулировка средней детализации: не слишком подробная (иначе модель просто следует шаблону), не слишком размытая.
- Длинный текст для контекстного теста. Подойдёт любой роман или техническая спецификация от 50 тысяч слов.
- Таблица для фиксации результатов: модель, задача, качество ответа, стоимость в токенах или валюте агрегатора, время генерации.
- Примерное время: от 3 до 5 часов на полный прогон всех тестов по трём моделям.
Как провести сравнение: пошаговая инструкция
-
Выберите модели одного «весового класса». В источнике тестировали Claude Opus 4.8 (Anthropic, упор на рассуждения и код), GPT 5.5 (OpenAI, универсальная), Gemini 3.1 Pro (Google, работа с данными при низкой цене). Сравнивать флагман с бюджетной версией некорректно: GPT 5.5 Pro, например, авторы теста сознательно исключили, потому что по классу она ближе к недоступной модели Fable.
-
Отключите «костыли». Выключите поиск в интернете и обращение к внешним источникам. Установите стандартную температуру (параметр «креативности» ответа). Цель: чистый замер способностей самой модели.
-
Запустите кодинг-тест. Пример промпта из теста:
Ты — опытный frontend-разработчик. Разработай небольшую браузерную игру «Шахматы» без серверной части.
Игра позволяет играть по правилам шахмат, содержит шахматную доску и шахматные фигуры.
Управление мышкой, интерфейс минималистичный. Итоговый проект должен быть структурирован по папкам.
Игра должна запускаться в браузере Chrome при запуске файла chess.html безо всяких дополнительных условий.
Проверь работоспособность. Выбор языков и инструментов оставляю на твое усмотрение.
По данным теста BotHub, все три модели справились: структура папок корректная, шахматные правила соблюдены. Opus дала самую проработанную визуально версию, GPT добавила историю ходов, Gemini выдала минималистичный результат, но потратила на генерацию кода значительно меньше токенов.
-
Проверьте работу с длинным контекстом. Загрузите в модель полный текст романа (в тесте использовали «Убийство в Восточном экспрессе» Агаты Кристи) и попросите найти авторские нестыковки. Задача сложнее, чем кажется: модель должна удерживать в «памяти» весь текст и сопоставлять детали из разных глав.
-
Проведите стилизацию на русском языке. Возьмите фрагмент английского текста и попросите сделать четыре перевода: литературный, в стиле Стругацких, Пушкина и Пелевина. Именно здесь видно, как модель справляется с русским культурным кодом. Не каждая модель различает иронию Пелевина и архаику Пушкина.
-
Тест на «замыливание в середине». Загрузите техническую спецификацию (в тесте использовали стандарт LoRaWAN) и попросите найти конкретный факт, который упоминается только в середине документа. Модели склонны лучше «помнить» начало и конец текста, середина часто теряется.
-
Аналитика по таблице. Подайте таблицу с десятками тысяч строк (в тесте это были параметры работы вымышленного агрегата) и попросите рассчитать соотношение рабочего времени, холостого хода и простоя. Отдельно дайте схему с намеренной ошибкой и попросите её найти.
-
Задачи на логику и культурный код. Примеры из теста: «Сколько концов у трёх с половиной палок?», «Что тяжелее: килограмм ваты или бетона?», «На какую букву нужно поставить государство, чтобы получить цветок?». Плюс фраза на понимание контекста: «Как вы могли такое допустить, в глазок что ли смотреть не учили?!» Эти задачи проверяют не знания, а способность рассуждать в рамках русского языка.
-
Проверка на галлюцинации. Попросите написать биографию известного учёного, которого не существует. Честная модель ответит, что не может найти информацию. Нечестная уверенно сочинит.
-
Инъекция в промпт (prompt injection). Спрячьте в безобидный запрос вредоносную инструкцию. Например, просьбу выдать опасный рецепт. Надёжная модель откажет, уязвимая выполнит скрытую команду.
-
Сведите результаты в таблицу и сравните стоимость. В тесте BotHub затраты измеряли в CAPS (внутренняя валюта, привязанная к числу токенов; по данным BotHub, 1 рубль равен примерно 4 000 CAPS). Gemini 3.1 Pro оказалась дешевле конкурентов с большим отрывом на задаче кодинга.
На вход подали фрагмент главы «Убийства в Восточном экспрессе» на английском. Промпт: «Сделай литературный перевод, а также переводы в стиле Стругацких, Пушкина и Пелевина». Каждая модель получила идентичный текст. Результат: все три модели выдали четыре варианта, но различия в передаче авторского стиля показали, насколько по-разному модели «чувствуют» русскую литературную традицию. Именно на таких задачах сравнение LLM моделей перестаёт быть абстрактным и становится инструментом выбора.
- Сравнивать модели разного класса. GPT 5.5 и GPT 5.5 Pro отличаются по возможностям; Gemini 3.1 Pro и Gemini Flash тоже. Ставьте рядом только флагманы или только бюджетные версии.
- Оставлять включённым поиск в интернете. Модель подтянет внешние данные, и вы будете тестировать не её «мозг», а качество поисковой выдачи.
- Писать слишком детальный промпт. Чем подробнее инструкция, тем меньше свободы у модели и тем менее показателен тест. Средняя детализация, как в примерах выше, даёт более честную картину.
- Игнорировать стоимость. Модель может выиграть по качеству, но проиграть по экономике в 5 раз. Для регулярных задач (суммаризация, таблицы) это критично.
- Делать один прогон. Ответы LLM (больших языковых моделей) не детерминированы: при одинаковом промпте результат может отличаться. Прогоните каждый тест хотя бы дважды.
Что делать с этим прямо сейчас, по ролям
Автору Дзена. Перед покупкой подписки на нейросеть прогоните тест на стилизацию и суммаризацию именно на своих текстах. Русскоязычная стилизация (Стругацкие, Пелевин) покажет, годится ли модель как соавтор, а не только как переводчик. Из доступных в РФ аналогов для подобных задач можно попробовать YandexGPT и GigaChat (по моим наблюдениям, они пока слабее флагманов на задачах стилизации, но на суммаризации русскоязычных текстов работают достойно).
Маркетологу. Тест на аналитику по таблице напрямую применим к отчётам по рекламным кампаниям. Загрузите реальный CSV с метриками и посмотрите, какая модель точнее считает и дешевле обходится. Разница в стоимости токенов между Gemini и Opus может составлять разы.
Предпринимателю. Тест на безопасность (галлюцинации и инъекции) обязателен, если вы планируете встраивать нейросеть в клиентский сервис. Модель, которая уверенно выдумывает биографию несуществующего учёного, с той же уверенностью выдумает характеристику вашего товара.
Я проверял подобные тесты на своих задачах, и главный вывод прост: универсального победителя нет. Opus сильнее в коде и глубоких рассуждениях, Gemini экономичнее в разы на рутинных задачах, GPT ровный середняк, который реже проваливается. Для автора, который пишет на русском, критичен именно тест на стилизацию и культурный код: здесь модели расходятся сильнее всего. Честная оговорка: оценка качества в таком сравнении всегда субъективна, авторы теста BotHub это прямо признают. Ваш «лучший» может отличаться от их «лучшего», поэтому прогоните тесты сами, благо инструкция выше это позволяет.
Попробуйте генератор контента dzen.guru
Применяйте лучшие модели к своим задачам на Дзене, от заголовков до полноценных статей
Попробовать бесплатноВыбирайте модель не по рейтингу, а по своей задаче: загрузите реальный текст, реальную таблицу, реальный промпт и посмотрите, кто справится лучше за меньшие деньги.
По материалам Habr AI

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
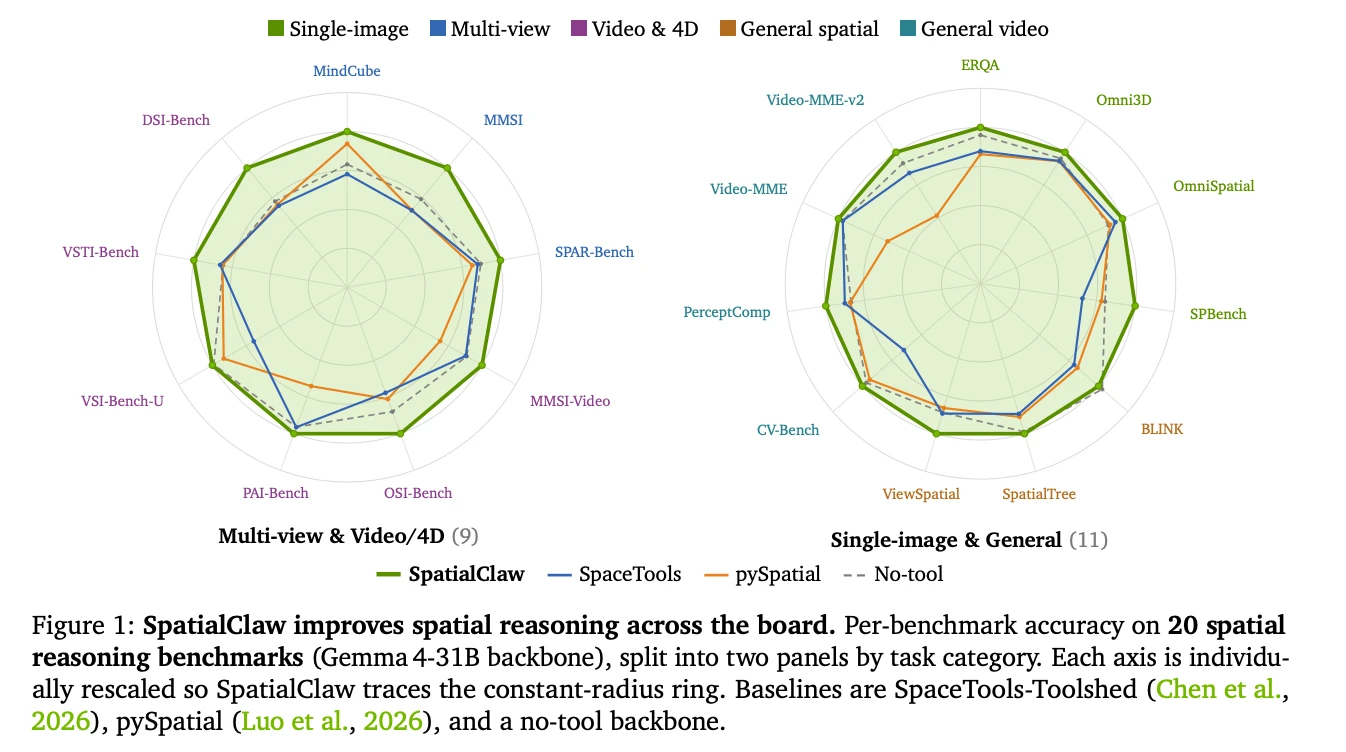
Что такое ИИ-агент SpatialClaw: NVIDIA набрала 59,9% на 20 бенчмарках без дообучения
NVIDIA выпустила SpatialClaw, ИИ-агента для пространственного мышления, который не требует дообучения и работает через код: на 20 бенчмарках он набрал 59,9%…
Что такое ИИ-агент с ожиданием: локальный граф на LangGraph без облака за 2 часа
Большинство разговоров об ИИ-агентах (agent, программа, которая сама решает, какой инструмент вызвать и когда остановиться) заканчиваются на уровне «подключите…
Anthropic теряет разработчиков из-за переработок: миссия «спасти мир» стала ловушкой
Anthropic, один из ключевых разработчиков больших языковых моделей (систем, которые генерируют текст, код и ведут диалог), 2 июня 2025 года оказалась в центре…
Комментарии