SmartDocs ускоряет распознавание текста в 30 раз: ИИ не только читает документ, но и понимает его
Компания SmartDocs представила систему распознавания документов на базе мультимодальной модели (модели, которая одновременно «видит» изображение и «понимает» текст), заточенную под реальные задачи российского бизнеса, от мятых фотографий договоров до пожелтевших архивов советской эпохи.
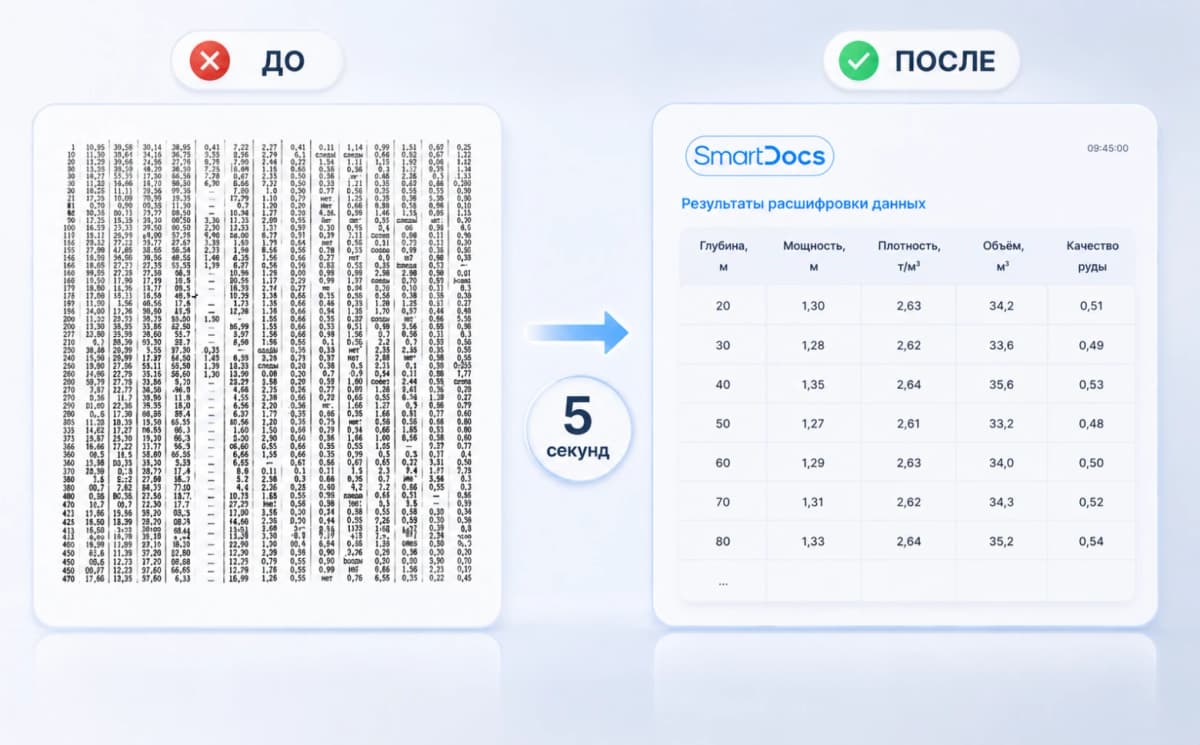
Классическое распознавание текста (OCR, optical character recognition) умеет превращать картинку в буквы, но не понимает, что эти буквы значат. SmartDocs заявляет, что решает обе задачи: и читает, и извлекает нужные данные, номер договора, сумму, контрагента, и раскладывает их по полям учётной системы.
До сих пор большинство компаний в России обрабатывают входящие документы вручную: сотрудник открывает скан или фотографию, находит нужные реквизиты, переносит их в ERP (систему управления ресурсами предприятия) или таблицу и проверяет за собой. По данным разработчиков SmartDocs, в крупных организациях на это уходят десятки тысяч часов в год. Продукт обещает сократить обработку одного документа с 30 секунд до 1 секунды, то есть примерно в 30 раз.
| Что | Когда | Кто выпустил | Цена |
|---|---|---|---|
| SmartDocs, система распознавания и атрибутирования документов на мультимодальной модели | Доступна сейчас (точную дату запуска разработчик не называет) | SmartDocs (Россия) | Не раскрыта, предлагают тест на ваших документах |
Что умеет SmartDocs и чем это отличается от обычного OCR?
Разработчики разделяют два процесса, которые часто путают.
- Распознавание (OCR): система видит скан и определяет буквы. С чистыми и ровными документами справляется и классический OCR.
- Атрибутирование: система понимает смысл текста и извлекает конкретные поля, номер, дату, сумму, контрагента, артикулы, и складывает их в нужную структуру. Для этого уже нужна мультимодальная модель, именно она лежит в основе SmartDocs.
Вот какие типы документов разработчики показывают в качестве рабочих кейсов:
- Фотографии договоров с телефона, кривые, с тенями, частично смазанные. Система вытаскивает номер договора, дату, стороны и сумму.
- Счета-фактуры в любом виде (скан, PDF, фото). Извлекаются номер, дата, контрагент, позиции, суммы, НДС. Результат готов к загрузке в учётную систему.
- Пэкинг-листы (упаковочные листы) с десятками позиций, артикулами, весами, кодами. Кейс пришёл от логистической компании, работающей с международными поставками.
- Распознавание рукописного текста: резолюции на письмах, пометки на полях, старые рукописные письма целиком. Система не просто распознаёт символы, а извлекает смысл, утверждают разработчики.
- Этикетки с круговым текстом, мелким шрифтом и сложным фоном, то, с чем классический OCR почти не справляется.
- Старые документы советской эпохи: технологические инструкции, чертежи, регламенты 30-40-летней давности. Система переводит их в цифровой формат (HTML или Word). Один из клиентов, компания, проектирующая двигатели, хранит тысячи страниц таких архивов.
Стоит отметить, что все перечисленные кейсы описаны самими разработчиками. Независимых тестов или сравнительных замеров в источнике нет.
Как попробовать?
- Перейдите на сайт SmartDocs (ссылку разработчик предоставляет по запросу, публичный URL в источнике не указан).
- Загрузите свой документ: скан, PDF или фотографию.
- Посмотрите, какие атрибуты система извлечёт и в какую структуру их разложит.
- Оцените, подходит ли результат для загрузки в вашу учётную систему или таблицу.
SmartDocs и другие инструменты: что есть в России?
Для понимания контекста: на российском рынке давно работают сервисы распознавания текста. Вот как они соотносятся по заявленным возможностям.
| Возможность | SmartDocs | ABBYY FineReader | Яндекс Vision OCR |
|---|---|---|---|
| Распознавание печатного текста | Да | Да | Да |
| Распознавание рукописного текста | Да (с пониманием контекста, по заявлению разработчиков) | Частично | Частично |
| Атрибутирование (извлечение полей: номер, дата, сумма) | Да, на мультимодальной модели | Через шаблоны | Нет из коробки |
| Советские архивы, пожелтевшие документы | Да (кейс описан) | Ограниченно | Не заявлено |
| Круговой текст на этикетках | Да (кейс описан) | Нет | Нет |
| Доступность в РФ | Да, российский продукт | Да (с ограничениями после 2022) | Да |
Оговорка: данные по SmartDocs взяты из описания разработчика. По ABBYY и Яндексу приведены общеизвестные характеристики продуктов. Прямого сравнения на одних и тех же документах в источнике нет.
Что делать с этим прямо сейчас, по ролям?
Автору на Дзене. Если вы работаете с архивами, расшифровываете старые документы для исторических или краеведческих статей, подобные инструменты экономят часы. Загрузите пробный документ и проверьте, насколько точно система читает рукописный текст, прежде чем переносить вручную.
Бухгалтеру и предпринимателю. Счета-фактуры и первичка, главный кандидат на автоматизацию. Если в вашей компании кто-то каждый день вбивает реквизиты из сканов в 1С, попросите демо на ваших документах. Разница между 30 секундами и 1 секундой на документ при потоке в сотни штук в день, это реальное высвобождение людей.
Маркетологу. Распознавание этикеток и упаковки может пригодиться для мониторинга конкурентов или каталогизации продукции. Пока это нишевая функция, но она заявлена как рабочая.
Заявленные возможности выглядят сильно, особенно распознавание рукописного текста и советских архивов. По моему опыту, именно на таких документах «ломаются» большинство OCR-сервисов. Но я хочу быть честным: все кейсы в источнике описаны самим разработчиком, без независимой проверки и без конкретных цифр точности распознавания (процент ошибок, сравнение с конкурентами на одних данных). Я бы рекомендовал загрузить 5-10 своих самых «сложных» документов и посмотреть на результат, прежде чем принимать решение о внедрении. Бесплатный тест на своих файлах, это минимум, который стоит сделать уже сегодня.
Частые вопросы
Чем SmartDocs отличается от Google NotebookLM?
NotebookLM работает с уже оцифрованными текстами: вы загружаете PDF с текстовым слоем, и система помогает анализировать содержимое. SmartDocs решает другую задачу: берёт изображение (фото, скан) и сначала распознаёт текст, а затем извлекает из него структурированные данные. Это инструмент не для анализа, а для оцифровки и атрибутирования.
Работает ли система с рукописным текстом на русском языке?
По заявлению разработчиков, да. В описанных кейсах упоминаются рукописные резолюции, пометки на полях и полностью рукописные старые письма. Система не просто распознаёт символы, а извлекает смысл из контекста, утверждают создатели. Независимых тестов точности распознавания рукописного текста в источнике не приводится.
Сколько стоит SmartDocs?
Цену разработчик публично не раскрывает. Предлагается протестировать систему на своих документах, после чего, судя по описанию, обсуждаются условия. Для оценки экономики посчитайте, сколько часов в месяц ваши сотрудники тратят на ручной ввод данных из документов, и сравните с предложением.
Если в вашей компании до сих пор кто-то каждое утро вручную перебивает реквизиты из сканов, это тот случай, когда стоит потратить полчаса на тест, а не ещё один год на ручной труд.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Локальная нейросеть на ПК с 4 ГБ видеопамяти: пошаговая настройка без облака и подписок
Локальная нейросеть на домашнем ПК с Windows 11 решает конкретную задачу: вы получаете языковую модель, которая работает без облака, без подписки и без…
37% новых треков на Яндекс Музыке сгенерированы: нейросеть для создания музыки научились детектить без GPU
Нейросеть для создания музыки бесплатно генерирует треки, которые уже составляют больше трети новых релизов на Яндекс Музыке, и теперь есть способ отличить их…
Компьютерное зрение на палубе судна: как трёхуровневая валидация убирает ложные тревоги
Компьютерное зрение (computer vision, технология, позволяющая нейросети «видеть» и анализировать изображения с камер) на открытой палубе судна сталкивается с…
Комментарии