RAG нейросети уходят от энкодеров к декодерам: как мигрировать за два дня
Русскоязычные команды, которые строили RAG (retrieval-augmented generation, когда нейросеть ищет ответ не в своей памяти, а в подключённой базе документов) на энкодерах семейства BERT, в 2026 году столкнутся с тем, что продвинутые команды уже перешли на декодерные LLM-эмбеддеры и другой инференс-стек.
Энкодеры вроде BGE и e5 упёрлись в потолок: 512 токенов контекста, нет поддержки инструкций на лету, инференс-инструменты (ONNX Runtime) отстали от декодерного стека. Кто не мигрирует, останется с устаревшей обвязкой, которую сообщество перестало развивать.
Ещё два года назад стандартный стек RAG-нейросети выглядел одинаково у всех: BERT-семейство для семантического поиска, BM25 для буквальных совпадений, cross-encoder (модель, которая берёт пару «запрос плюс документ» и оценивает релевантность) для реранкинга, сверху векторная база вроде Qdrant. Сейчас команды, ушедшие вперёд, заменили почти каждый элемент. Эмбеддинг делает дообученная LLM (большая языковая модель), реранкер тоже LLM, инференс (процесс получения ответа от модели) идёт через SGLang, а не через ONNX. Ниже разберём, как повторить этот переход у себя, особенно если вы работаете в узком домене без готовых датасетов.
Что понадобится
- Доступ к модели Qwen3-Embedding (открытые веса, скачивается с HuggingFace) или аналогичному декодерному эмбеддеру
- Инференс-сервер SGLang или vLLM (оба опенсорсные, ставятся через pip)
- Векторная база данных (Qdrant, Milvus или аналог, который у вас уже есть)
- Декодерная LLM для генерации синтетических данных: Qwen3-32B, Llama или любая модель с API
- GPU с поддержкой flash attention (от NVIDIA A100 или потребительская RTX 4090 для экспериментов)
- Время: базовый переход занимает от одного до двух рабочих дней, дообучение на своих данных ещё от двух до пяти дней
Как старый стек упёрся в потолок?
Классический энкодер берёт текст, прогоняет через bidirectional-трансформер (модель, которая читает текст одновременно слева направо и справа налево), сжимает в один вектор через специальный токен [CLS] или усреднение. Этот вектор кладётся в базу, по нему ищется ближайший сосед.
Проблемы три, и все практические:
- Узкие домены не вытягиваются. Если BGE на претрейне не видел ваш юридический или нефтяной корпус, замена
bge-baseнаbge-largeне спасёт - Контекст ограничен. Большинство энкодеров работает в пределах 512 токенов. Отсюда весь зоопарк стратегий нарезки текста (chunking) в LangChain
- Инструкцию под задачу нельзя задать на лету. Хотите retrieval (поиск), учите модель под retrieval. Хотите классификацию, учите отдельно
Декодер заменяет энкодер: как это работает?
Декодер обучен предсказывать следующий токен, и каждый токен видит только предшественников. Усреднять по ним бессмысленно: первый токен ничего не знает о предложении.
Решение: берут последний токен <eos>, который «видел» всю последовательность и собрал её смысл. На этом трюке стоит большинство современных эмбеддеров.
Базовый рецепт описан в статье LLM2Vec (McGill University, 2024). Три шага: включить bidirectional attention, дообучить через masked next-token prediction, добить unsupervised contrastive learning по схеме SimCSE. Уже на этом этапе модель обгоняет энкодеры сопоставимого размера. Модель NV-Embed добавила к рецепту latent attention pooling (отдельный обучаемый слой, собирающий информацию со всех токенов), что, по данным бенчмарка MTEB, даёт плюс от 1 до 2 пунктов стабильно.
Пошаговая инструкция миграции
-
Замените энкодер на декодерный эмбеддер. Скачайте Qwen3-Embedding с HuggingFace. Модель из коробки поддерживает Matryoshka Representation Learning: один эмбеддинг можно усечь до 256, 512 или 1024 измерений без переобучения, качество падает плавно, а не обрывом
-
Переведите инференс на SGLang. ONNX Runtime номинально поддерживается, но flash attention туда не завезли, prefix caching (кеширование повторяющихся частей запроса) отсутствует. SGLang и vLLM дают всё это из коробки для декодеров
-
Добавьте инструкцию в промпт эмбеддера. Вместо переобучения под каждую задачу вы кладёте в промпт описание: «Найди документ, отвечающий на вопрос». Та же модель переключается между retrieval, классификацией и кластеризацией без дообучения
-
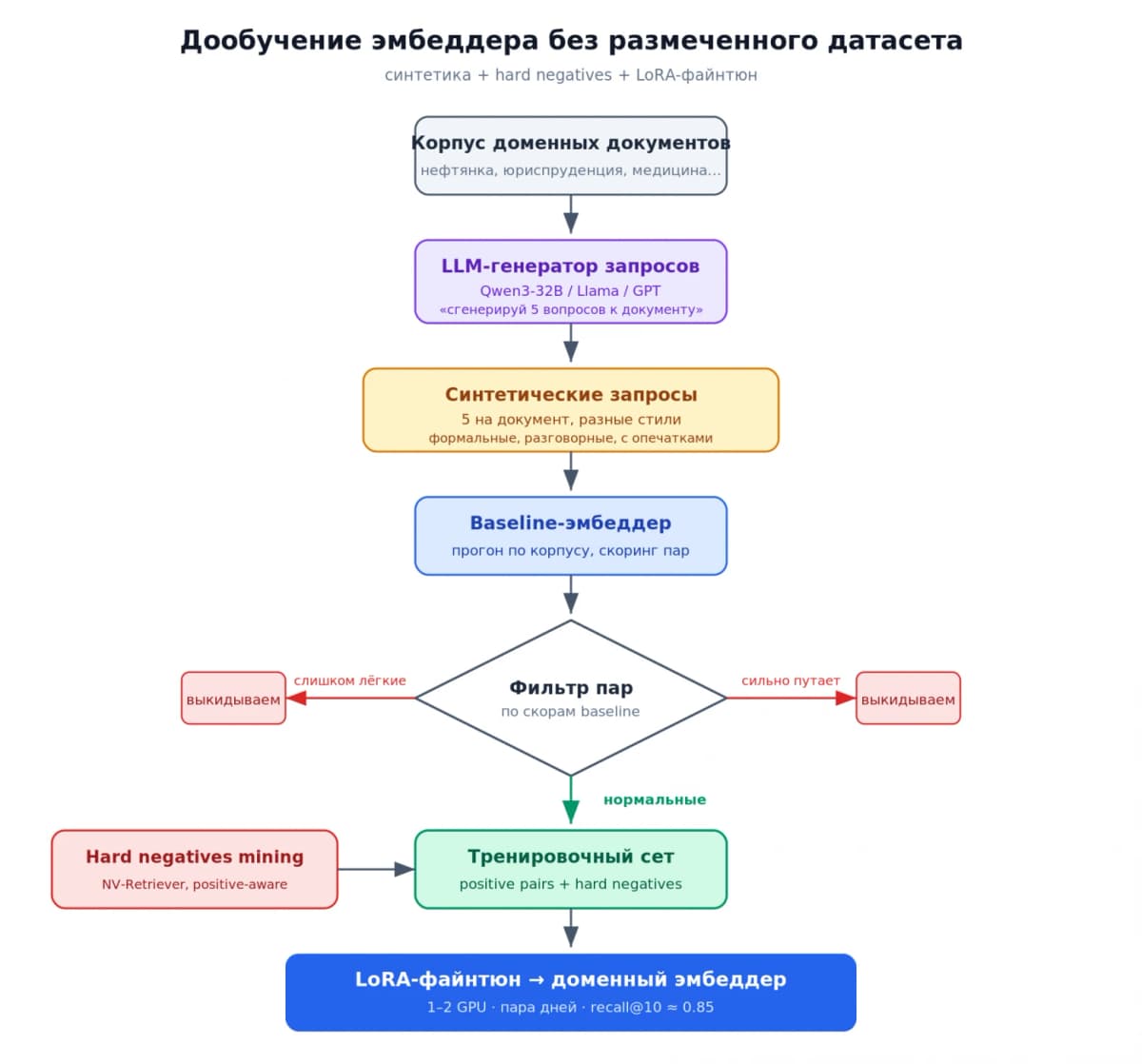
Сгенерируйте синтетические данные для своего домена. Возьмите свои документы и пропустите через LLM для генерации запросов:
Документ: {текст документа}
Сгенерируй 5 вопросов, которые мог бы задать инженер,
ищущий именно этот документ. Вопросы должны быть разной
формулировки: формальные, разговорные, с аббревиатурами,
с опечатками.
На выходе получатся десятки тысяч пар «запрос плюс документ» без ручной разметки.
-
Дообучите эмбеддер на синтетике. Файнтюните (дообучение, обучение модели на ваших примерах под узкую задачу) Qwen3-Embedding на полученных парах через supervised contrastive learning с hard negatives. Вам нужно научить модель ранжировать пары «запрос и документ» в вашей конкретной задаче. Сам язык домена она уже знает из претрейна на триллионах токенов
-
Отфильтруйте синтетику. Прогоните сгенерированные пары через модель, уберите те, где релевантность ниже порога. Качество синтетики не идеальное, но для дообучения эмбеддера его достаточно
Допустим, вы строите RAG-нейросеть для поиска по нормативным документам нефтяной отрасли. В промпт эмбеддера кладёте:
Instruct: Найди в корпусе нормативных документов раздел,
описывающий требования к промышленной безопасности
на нефтеперерабатывающих установках.
Query: {запрос пользователя}
Без дообучения, просто за счёт инструкции, recall (доля найденных релевантных документов) вырастает на 3 до 5 пунктов по сравнению с тем же эмбеддером без инструкции. А контекст в 32 000 токенов у Qwen3-Embedding позволяет положить параграф целиком, без нарезки на куски.
Усреднение токенов вместо пулинга последнего. Если взять декодер и усреднить все его токены, как делали с BERT, результат будет хуже энкодера. Пулите <eos> или используйте latent attention pooling.
Старый инференс-стек. Запуск декодерного эмбеддера через ONNX Runtime убивает выигрыш по скорости. Flash attention и prefix caching работают только на SGLang и vLLM.
Доверие синтетике без фильтрации. LLM генерирует запросы с галлюцинациями (когда модель уверенно выдумывает то, чего не было). Если не прогнать пары через проверку релевантности, дообученная модель выучит шум.
Ожидание идеального русского языка из коробки. Qwen3-Embedding покрывает русский неплохо, но для специфичного домена (юриспруденция, медицина, бухгалтерия) дообучение обязательно. Без него качество на профессиональной терминологии просядет.
Что делать с этим прямо сейчас, по ролям
Разработчику RAG-нейросети. Проверьте, на чём стоит ваш эмбеддер. Если это BGE, e5 или другой BERT-семейства, запланируйте миграцию на Qwen3-Embedding плюс SGLang. Начните с замены эмбеддера без дообучения, добавив инструкцию в промпт, и замерьте recall на своих данных.
Автору на Дзене и копирайтеру. Если вы подключаете базу знаний к ИИ-ассистенту для генерации контента, декодерный эмбеддер с длинным контекстом означает, что не нужно вручную резать тексты на куски. Положили статью целиком, модель нашла нужный фрагмент.
Предпринимателю в РФ. Qwen3-Embedding доступна как открытая модель, скачивается без ограничений. Из российских аналогов для эмбеддинга можно смотреть на решения от Сбера, но на момент публикации декодерных эмбеддеров сопоставимого уровня в открытом доступе от российских компаний нет. SGLang и vLLM разворачиваются на российских серверах без проблем.
По моим наблюдениям, основная масса русскоязычных RAG-проектов до сих пор сидит на BGE плюс ONNX. Это работает, но потолок виден: 512 токенов, отсутствие инструкций, стагнирующий инференс-стек. Переход на декодерный эмбеддер это не мода, а практическая необходимость, особенно если ваш домен узкий и датасетов нет. Синтетическая разметка через LLM снимает самый болезненный блок: месяцы ручной работы команды разметчиков. Честная оговорка: качество синтетики сильно зависит от качества ваших исходных документов. Если корпус грязный, с дублями и ошибками, модель выучит мусор. Сначала почистите данные, потом генерируйте пары.
Попробуйте RAG-ассистент dzen.guru
Протестируйте, как декодерный эмбеддер ищет по вашей базе знаний, и сравните с текущим стеком
Попробовать бесплатноМиграция со старого стека на декодерные эмбеддеры не требует переписывать весь пайплайн за один день. Начните с замены одного компонента, эмбеддера, добавьте инструкцию в промпт и замерьте разницу на своих запросах. Если recall вырос, двигайтесь дальше: SGLang, синтетические данные, дообучение. Если нет, значит, проблема не в эмбеддере, а в данных, и это тоже полезный ответ.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Бизнес-анализ с ИИ по BABOK: «AIналитик» ушёл от привязки к одной модели и работает локально
Нейросеть, работающая бизнес-аналитиком по методологии BABOK (международный свод знаний по бизнес-анализу), перестала зависеть от одной модели и одного…

SpaceX выкупает Cursor за $60 млрд: нейросеть для кода подорожала вдвое за полтора года
Компания Anysphere, создатель популярного ИИ-редактора кода Cursor, прошла путь от студенческого стартапа до сделки со SpaceX на 60 млрд долларов за три года,…

Нейросеть в медицине выдумывает диагнозы: 4 провала сервиса и как их чинили
Медсервис на нейросетях звучит просто, пока не увидишь, как модель уверенно связывает повышенные лейкоциты с препаратом, который пользователь начал принимать…
Комментарии