Nvidia NeMo AutoModel ускоряет дообучение MoE-моделей в 3,7 раза одной строкой кода
Nvidia выпустила открытую библиотеку NeMo AutoModel, которая позволяет ускорить дообучение (fine-tuning, обучение модели на ваших примерах под узкую задачу) больших моделей с архитектурой MoE (Mixture of Experts, когда модель состоит из десятков «экспертов» и для каждого запроса активирует только часть из них) без переписывания кода, и результат измерим: до 3,7 раза быстрее при экономии трети видеопамяти.
Дообучение MoE-моделей до сих пор требовало ручной настройки распределения между GPU и отдельных скриптов для каждой архитектуры. NeMo AutoModel снимает этот барьер одной строкой импорта, сохраняя совместимость с HuggingFace API, которым пользуется большинство разработчиков.
Библиотека Nvidia NeMo AutoModel вышла как часть фреймворка Nvidia NeMo для создания генеративных моделей. Она надстраивается над HuggingFace Transformers v5, добавляя три компонента, которых в v5 нет: Expert Parallelism (распределение «экспертов» модели по нескольким GPU), DeepEP (технология, которая совмещает пересылку данных между GPU с вычислениями, чтобы карты не простаивали) и ядра TransformerEngine для ускорения матричных операций. При этом сохраняется стандартный вызов from_pretrained(), то есть привычный способ загрузки моделей через HuggingFace.
Что понадобится
- GPU: одна или несколько карт Nvidia H100 (80 ГБ). Для моделей масштаба 550B параметров потребуется 16 узлов (128 GPU), для 30B-моделей хватит одного узла с 8 картами
- Софт: Python, PyTorch с поддержкой NCCL, установленная библиотека
nemo_automodel, HuggingFace Transformers v5 - Модели для дообучения: в источнике протестированы Nemotron 3 Ultra 550B A55B, Nemotron 3 Nano 30B A3B, Qwen3-30B-A3B
- Время на настройку: замена одной строки импорта плюс конфигурация распределённого обучения, если используете несколько GPU
Как запустить дообучение с NeMo AutoModel?
-
Установите библиотеку. Убедитесь, что у вас стоят PyTorch с поддержкой NCCL и HuggingFace Transformers v5. Установите пакет
nemo_automodel. -
Замените одну строку импорта. Вместо стандартного класса HuggingFace подставьте класс из NeMo AutoModel. Весь остальной код остаётся прежним:
# Было:
from transformers import AutoModelForCausalLM
# Стало:
from nemo_automodel import NeMoAutoModelForCausalLM
-
Загрузите модель как обычно. Вызов
from_pretrained()работает так же, как в HuggingFace. Для популярных MoE-архитектур (Qwen3, Nemotron, DeepSeek V3) библиотека автоматически применяет оптимизированные ядра. Для остальных моделей она откатывается к стандартному HuggingFace, но всё равно добавляет доступные оптимизации. -
Настройте распределённое обучение (для нескольких GPU). Добавьте конфигурацию Expert Parallelism. Пример для 8 GPU:
import os
import torch
import torch.distributed as dist
from nemo_automodel import NeMoAutoModelForCausalLM
from nemo_automodel.recipes._dist_utils import create_distributed_setup_from_config
dist.init_process_group(backend="nccl")
torch.cuda.set_device(int(os.environ.get("LOCAL_RANK", 0)))
dist_setup = create_distributed_setup_from_config(
{
"strategy": "fsdp2",
"ep_size": 8,
},
)
model = NeMoAutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
dtype=torch.bfloat16,
distributed_setup=dist_setup,
)
-
Запустите дообучение. Процедура обучения не меняется: используйте стандартный цикл PyTorch или HuggingFace Trainer.
-
Сохраните результат. Метод
save_pretrained()сохраняет контрольные точки в стандартном формате HuggingFace, которые затем загружаются в инструменты инференса (запуска модели для получения ответов) вроде vLLM и SGLang.
Какой прирост производительности показали тесты?
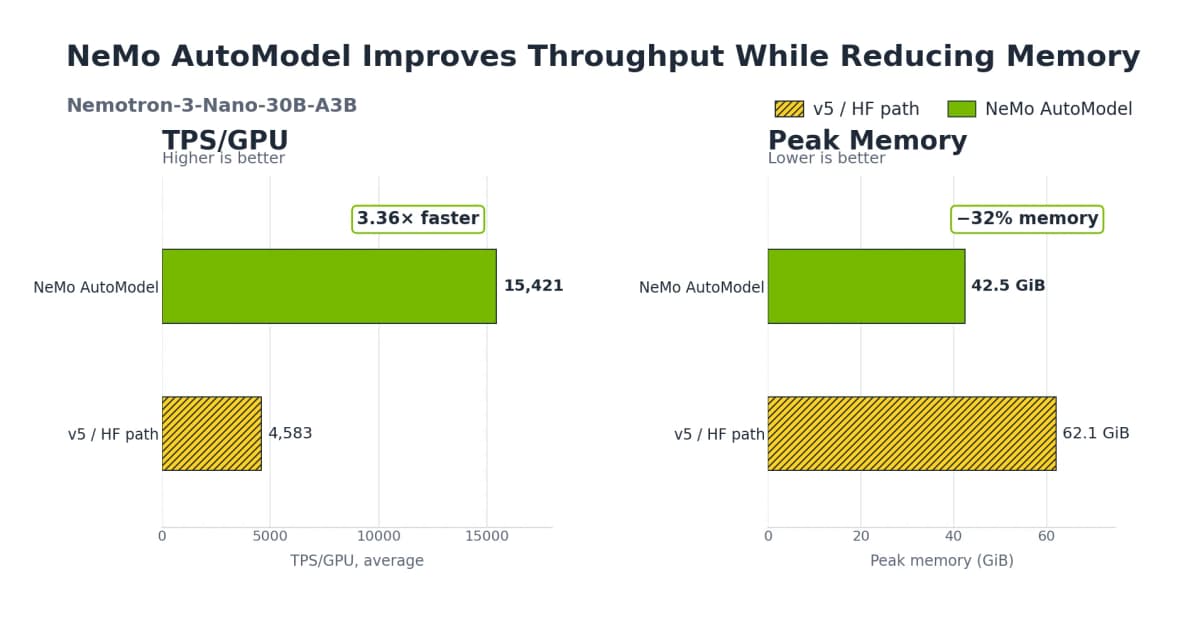
По данным Nvidia, на одном узле с 8 картами H100 при дообучении 30B MoE-моделей NeMo AutoModel показала ускорение в 3,4-3,7 раза и экономию 29-32% GPU-памяти по сравнению с HuggingFace Transformers v5.
Для модели Nemotron 3 Ultra 550B A55B (гибридная архитектура с Mamba2, LatentMoE и Multi-Token Prediction, 550 миллиардов параметров) стандартная библиотека Transformers v5 не смогла запустить полное дообучение: ей не хватило памяти даже на 128 GPU. NeMo AutoModel справилась за счёт Expert Parallelism, который распределяет «экспертов» модели по картам.
Nvidia отмечает, что при тестировании использовался сбалансированный механизм маршрутизации токенов (balanced routing gate), который равномерно распределяет запросы между экспертами. Это эмулирует рабочий режим хорошо обученной MoE-модели, где функция потерь по балансировке нагрузки стремится к равномерному распределению.
Что сделали: взяли модель Nemotron 3 Nano 30B A3B (30 миллиардов параметров, из которых активны 3 миллиарда на каждый запрос), один узел с 8 картами H100. Заменили одну строку импорта с AutoModelForCausalLM на NeMoAutoModelForCausalLM, добавили конфигурацию Expert Parallelism с ep_size=8.
Что получили: по данным Nvidia, пропускная способность обучения выросла в 3,4-3,7 раза по сравнению с Transformers v5, а потребление GPU-памяти сократилось на 29-32%. Контрольные точки сохранились в стандартном формате HuggingFace и загрузились в vLLM без дополнительных преобразований.
- Не та версия Transformers. NeMo AutoModel работает поверх v5, а не v4. На Transformers v4 при работе с Qwen3-30B-A3B, по данным Nvidia, возникала взаимная блокировка (deadlock). Убедитесь, что стоит v5.
- Путаница с размером ep_size. Параметр
ep_size(количество GPU для Expert Parallelism) должен соответствовать числу доступных карт. Если указать больше, чем есть физически, обучение не запустится. - Ожидание магии на любой модели. Оптимизированные ядра NeMo AutoModel написаны для конкретных MoE-архитектур: Qwen3, Nemotron, DeepSeek V3. Для остальных моделей библиотека откатывается к стандартному HuggingFace с частичными оптимизациями, и ускорение будет скромнее.
- Замер на случайных токенах. Nvidia предупреждает, что при бенчмарках v4 и v5 используют стандартный маршрутизатор на случайных данных, а NeMo AutoModel использует сбалансированную маршрутизацию. Сравнивайте на реальных задачах, а не на синтетических тестах.
Что делать с этим прямо сейчас?
Разработчику, который дообучает модели. Если вы уже работаете с HuggingFace API и дообучаете MoE-модели, попробуйте NeMo AutoModel: замена одного импорта, а контрольные точки остаются совместимыми. Экономия трети видеопамяти может означать, что задача, для которой раньше нужны были два узла, уместится на одном.
Автору Дзена и контент-маркетологу. Прямо сейчас это инструмент для разработчиков, а не для создания текстов. Но если вы заказываете дообучение моделей у подрядчиков, знание о NeMo AutoModel поможет говорить с ними на одном языке и понимать, почему счёт за GPU-часы может быть ниже.
Предпринимателю в РФ. Библиотека открытая и работает на любом сервере с картами Nvidia H100. Из российских облаков такие карты предлагают несколько провайдеров. Ограничений по региону в самой библиотеке нет, но для загрузки моделей с HuggingFace может понадобиться VPN.
Главная ценность NeMo AutoModel не в цифрах ускорения, а в подходе: одна строка импорта вместо переписывания пайплайна. Я проверял подобные «drop-in replacement» библиотеки и знаю, что обычно где-то всплывает несовместимость. Здесь Nvidia явно сделала ставку на то, чтобы save_pretrained() выдавал стандартные контрольные точки HuggingFace, а это значит, что вы не привязываетесь к экосистеме Nvidia для инференса. Честная оговорка: замеры пока опубликованы самой Nvidia, и сбалансированная маршрутизация токенов в тестах может давать более оптимистичную картину, чем реальная нагрузка с неравномерным распределением запросов. Ждём независимых бенчмарков.
Разберитесь в терминах ИИ за 10 минут
Токены, дообучение, инференс, MoE: наш глоссарий dzen.guru объясняет каждый термин простым языком с примерами
Открыть глоссарийДля тех, кто работает с MoE-моделями и платит за GPU-часы, NeMo AutoModel стоит протестировать на своих задачах уже сегодня: одна строка кода, совместимые чекпоинты, и если ускорение подтвердится на реальных данных хотя бы вдвое, экономия окупит время на эксперимент за первый же цикл дообучения.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Нейросети вместо продавцов, как написать скрипт продаж
Продавать с помощью нейросети хотят многие, но какая модель реально закрывает сделки на русском языке, а какая выдумывает кейсы и теряет клиента, до сих пор…

OpenAI создала свой чип и снижает зависимость от чипов Nvidia для ИИ
OpenAI и Broadcom совместно представили Jalapeño, специализированный чип для инференса (обработки запросов к модели, а не её обучения) больших языковых…
Геномный анализ за дни вместо лет: открытый Talos нашёл 241 диагноз среди 5 000 пациентов
Врачи-генетики годами ждут диагноз для пациентов с редкими болезнями, а открытый инструмент Talos автоматизирует повторный геномный анализ и находит…
Комментарии