ModelOps: что это и почему без него большинство ML-моделей не доходят до продакшена
Источник не содержит данных о раунде финансирования, сделке, инвесторах, суммах или датах привлечения средств. Архетип «funding» не подтверждается фактами оригинала: текст представляет собой образовательный отрывок из книги о практиках ModelOps. Писать новость о привлечении инвестиций на основе этого материала невозможно без выдумывания фактов, что запрещено правилом достоверности.

Ниже — новость, построенная по фактам источника, с адаптацией структуры под реальное содержание (образовательный разбор практики ModelOps с практическими примерами).
Издательство выпустило практическое руководство по ModelOps с примерами на Python и R, которое закрывает разрыв между обучением модели и её реальной работой в продакшене, где большинство ML-проектов до сих пор и застревают.
Большинство моделей машинного обучения никогда не доходят до реального использования: их обучают, тестируют и забрасывают. ModelOps (набор практик для развёртывания и поддержки моделей в рабочей среде) решает именно эту проблему, и теперь по нему появился структурированный русскоязычный материал с кодом.
Отрывок из книги «Современная бизнес-аналитика. Увеличьте ценность данных с помощью Python и R» опубликован на Хабре. Материал описывает полный жизненный цикл модели машинного обучения после того, как она обучена: оценку, мониторинг, переобучение и отчётность. Авторы приводят рабочие примеры приложений на R Shiny и Python Streamlit для пакетной и онлайн-оценки, а также дашборд мониторинга производительности в реальном времени.
Что такое ModelOps и почему модели без него бесполезны?
ModelOps (от Model Operations, эксплуатация моделей) — это набор практик, которые превращают обученную модель машинного обучения из лабораторного эксперимента в работающий инструмент внутри компании.
Ключевая мысль источника проста: если модель не развёрнута и не используется, организация не получает от неё никакой выгоды. Само по себе высокое качество предсказаний ничего не стоит, пока модель не встроена в процесс принятия решений.
Для понимания: представьте, что вы построили калькулятор, который идеально считает скидки для клиентов, но он лежит на вашем ноутбуке и никто в компании им не пользуется. ModelOps — это всё, что нужно сделать, чтобы этот калькулятор работал на сервере, обновлялся, не ломался и показывал, когда его пора переобучить.
Из каких частей состоит ModelOps?
Источник выделяет четыре процесса, связанных в цикл:
-
Оценка модели. Применение обученной модели к новым данным для получения прогнозов. Может работать в двух режимах: в реальном времени (пользователь отправляет запрос и сразу получает ответ) или пакетно (модель обрабатывает большой массив данных разом, например, ночью).
-
Мониторинг модели. Непрерывное отслеживание того, как модель ведёт себя в продакшене (рабочей среде): точность, скорость ответа, нагрузка на ресурсы. Если показатели отклоняются от нормы, система отправляет оповещение.
-
Переобучение. Обновление модели на свежих данных, чтобы она оставалась актуальной. Запускается по расписанию, по событию или когда мониторинг фиксирует дрейф данных (ситуацию, когда реальные данные начинают отличаться от тех, на которых модель училась).
-
Отчётность. Подготовка отчётов для бизнеса: как работает модель, какое влияние оказывает, где нужны улучшения.
Техническая среда: что нужно для запуска?
Книга описывает шесть компонентов производственной среды, без которых модель не заработает:
- Вычислительные ресурсы — достаточно мощности и памяти для обработки запросов.
- Программная среда — языки Python или R, библиотеки TensorFlow, PyTorch, конвейеры для очистки и подготовки данных.
- Инфраструктура развёртывания — REST API (интерфейс, через который приложения обращаются к модели), микросервисы или бессерверные платформы.
- Мониторинг и журналирование — отслеживание метрик в реальном времени и запись событий для отладки.
- Безопасность — шифрование, контроль доступа, аудит, соответствие регуляторным требованиям.
- Управление версиями — возможность откатить модель к предыдущей версии, если новая работает хуже.
R Shiny и Python Streamlit: инструменты, доступные прямо сейчас
Практическая часть материала построена на двух фреймворках для создания веб-приложений вокруг моделей.
R Shiny позволяет аналитику, который работает в R, развернуть интерфейс для оценки модели без знания веб-разработки. Python Streamlit делает то же самое для Python-разработчиков. Оба инструмента бесплатны и работают локально, что снимает вопрос доступности для команд в России и СНГ: не нужны зарубежные облачные сервисы, можно развернуть на собственном сервере.
Авторы показывают, как с помощью этих фреймворков собрать приложение для пакетной оценки (загрузил файл, получил прогнозы) и онлайн-оценки (ввёл параметры одного объекта, получил ответ), а также дашборд мониторинга, который в реальном времени показывает, не деградирует ли модель.
Что это значит для вас?
Если вы автор на Дзене или копирайтер и слышите термин ModelOps впервые, вот зачем он вам: всё больше редакций и контент-платформ внедряют модели для рекомендаций, автоклассификации и проверки текстов. Понимание цикла «оценка, мониторинг, переобучение» помогает задавать правильные вопросы технической команде и не ждать от модели вечной точности.
Если вы маркетолог или предприниматель, материал даёт конкретную рамку: прежде чем платить за разработку модели, убедитесь, что в бюджете заложены мониторинг и переобучение. Модель без этих процессов — одноразовый инструмент.
Если вы работаете с данными в России или СНГ, Shiny и Streamlit — рабочий вариант для прототипирования без зависимости от зарубежных облаков. Код из книги можно адаптировать на локальной инфраструктуре, что в условиях ограниченного доступа к AWS и GCP особенно ценно.
По моим наблюдениям, термин ModelOps пока мало знаком даже тем, кто регулярно использует ML в работе. Чаще говорят про MLOps, который шире и включает весь конвейер от данных до модели. ModelOps — это именно «последняя миля»: что происходит с моделью после обучения. Материал полезен тем, что не требует продвинутого уровня: примеры на Shiny и Streamlit понятны аналитику с базовыми навыками программирования. Единственная оговорка — это отрывок из книги, а не исчерпывающее руководство: для полноценного внедрения потребуется разбираться с CI/CD (автоматизацией сборки и доставки кода), оркестрацией контейнеров и выбором платформы мониторинга.
Полный цикл ModelOps — оценка, мониторинг, переобучение, отчётность — стоит взять как чек-лист для любого ML-проекта, который вы планируете довести до продакшена, а не оставить в Jupyter-блокноте.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
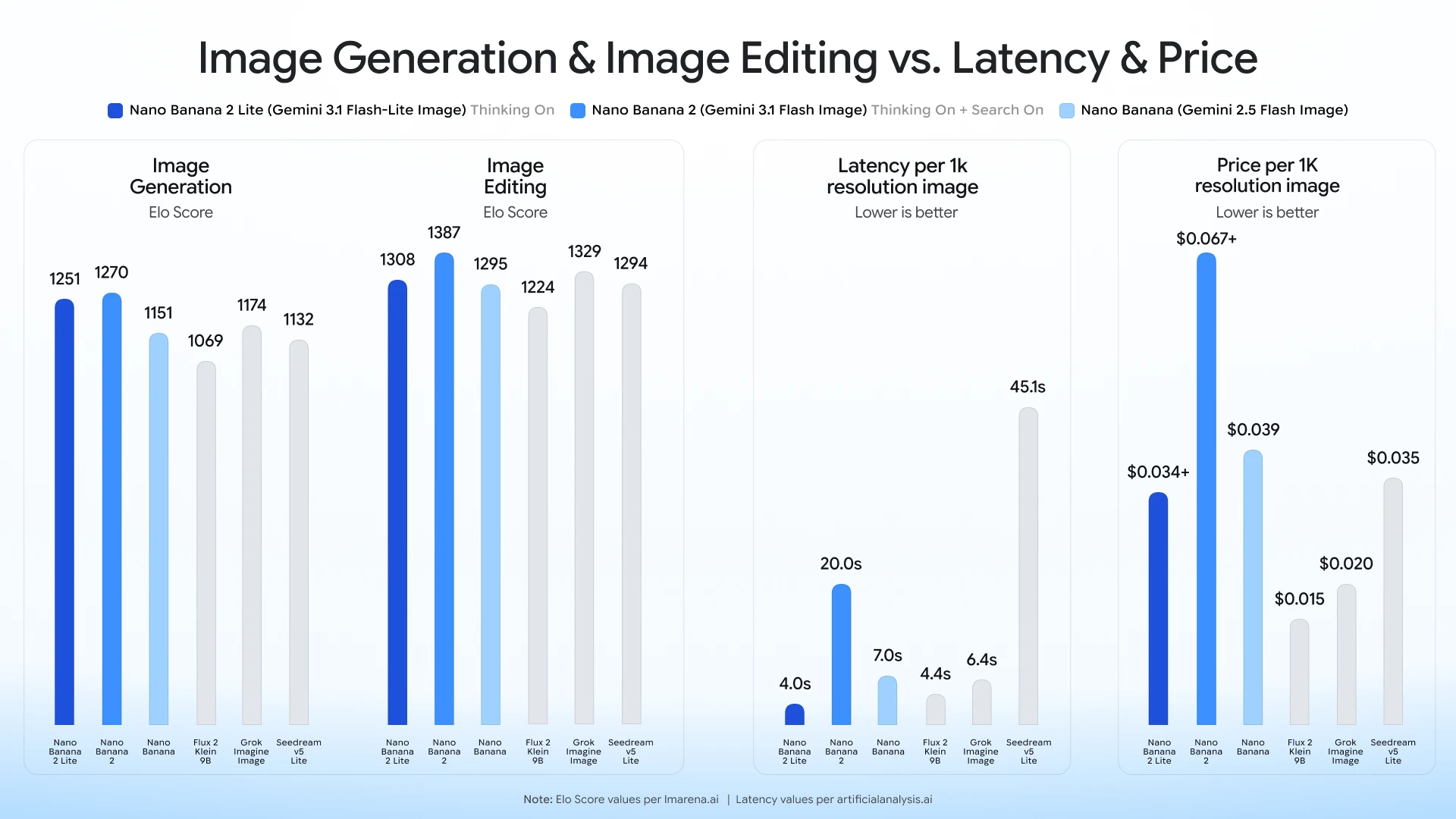
Gemini Omni Flash генерирует видео по текстовому промпту: $0,10 за секунду
Google второго июля открыла разработчикам две модели для генерации визуального контента: Nano Banana 2 Lite создаёт изображения за 4 секунды при минимальной…
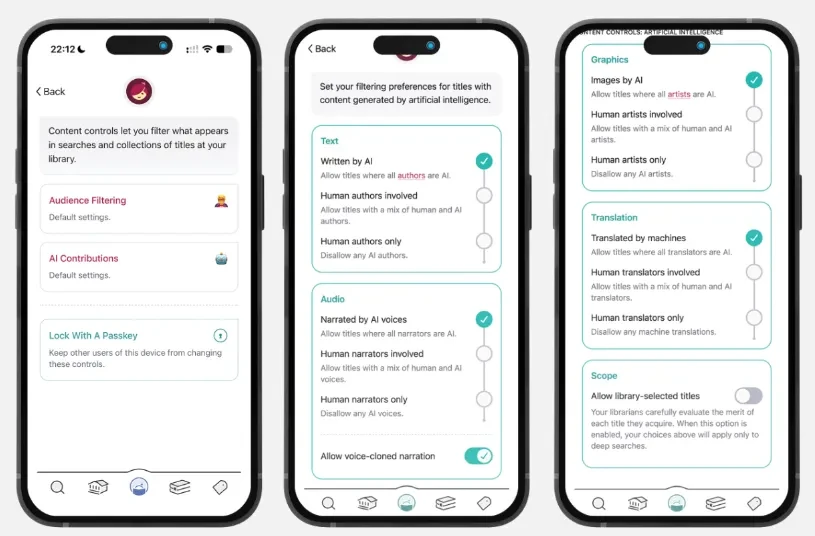
Libby вводит фильтрацию контента нейросетей для 92 000 библиотек: решать будет читатель
Библиотечное приложение Libby, через которое 92 000 библиотек в 115 странах выдают электронные книги, готовится дать читателям возможность скрывать контент,…
Что такое MCP сервер на практике: X запустил бесплатный коннектор для ИИ-ассистентов
Компания X (бывший Twitter) в понедельник запустила собственный хостируемый MCP-сервер, готовый коннектор между платформой и ИИ-ассистентами, который избавляет…
Комментарии