Локальный RAG на FastAPI и Ollama: add PDF, Word file без облака и подписок
Ниже работа с локальными документами выходит за рамки «поболтать с моделью» и превращается в инженерную систему с API, логами, источниками и диагностикой.
RAG (Retrieval-Augmented Generation, генерация с опорой на найденные документы) позволяет модели отвечать не «из головы», а по вашим файлам. Локальный вариант на FastAPI и Ollama держит данные на вашей машине, без облака и подписок.
Автор проекта описал путь от простого вызова локальной LLM до бэкенда с контрактом API, трассировкой запросов, источниками ответа и индексом документов. Не «production-ready» система, а учебный полигон с инженерными акцентами. Материал опубликован как открытый разбор архитектуры, цель которого показать, где именно заканчивается «чат с моделью» и начинается бэкенд-система по документации. Ниже воспроизвожу ключевые шаги и решения из этого разбора.
Что понадобится?
- Python 3.10+ и установленный FastAPI с сервером Uvicorn
- Ollama (опенсорс-инструмент для локального запуска LLM, работает на macOS, Linux, Windows)
- Модель для генерации: в проекте использована gpt-oss:20b (запускается через Ollama)
- Модель для эмбеддингов (векторных представлений текста): embeddinggemma (тоже через Ollama)
- Документы в формате
.mdили.txtв локальной папкеdocuments/ - Фронтенд на HTML/CSS/JS (минимальный, чтобы отправлять вопросы и видеть ответ)
- Примерное время: от 2 до 4 часов на первую работающую версию, если стек знаком
Пошаговая инструкция
1. Соберите минимальный бэкенд с эндпоинтом /ask
На старте схема проста: фронтенд отправляет POST /ask, FastAPI создаёт уникальный request_id, логирует запрос, вызывает модель через Ollama и возвращает ответ.
# Упрощённая схема (не полный код проекта)
@app.post("/ask")
async def ask(question: str):
request_id = str(uuid4())
log_request(request_id, question)
answer = call_ollama(question)
log_response(request_id, answer)
return {"request_id": request_id, "answer": answer}
На этом этапе помощник уже отвечает, но по сути остаётся обычным чатом с моделью. Документы в процессе не участвуют.
2. Осознайте, почему простой вызов LLM ещё не система
Проблемы, которые автор выделяет на этом этапе:
- Модель не знает локальные документы, если не передать их в контекст
- Ответ невозможно проверить по источникам
- Непонятно, что именно попало в промпт (prompt, запрос к модели)
- Если ответ медленный, неясно, какой этап тормозит
- Если документ изменился, неясно, обновился ли индекс
- Модель может «галлюцинировать» (уверенно выдумывать), даже когда ответа нет
3. Добавьте загрузку и нарезку документов на чанки
Положите файлы .md и .txt в папку documents/. Для тех, кому нужно добавить PDF или Word (ollama rag add pdf word file), на этом этапе потребуется предварительная конвертация в текстовый формат: библиотеки вроде pdfplumber для PDF и python-docx для Word извлекут текст, после чего файл обрабатывается так же, как .txt.
Документ целиком редко удобно передавать в промпт. Нарежьте его на чанки (небольшие фрагменты фиксированной длины с перекрытием). Отдельный эндпоинт GET /documents/chunks позволяет убедиться, что бэкенд видит и корректно режет каждый файл.
4. Постройте эмбеддинги и векторное хранилище
Эмбеддинги (embedding, числовое представление смысла текста) считаются через Ollama и модель embeddinggemma. Каждый чанк превращается в вектор, все векторы складываются в хранилище в оперативной памяти (in-memory vector store).
Эндпоинт POST /documents/index/rebuild перечитывает документы, режет, считает эмбеддинги и обновляет хранилище. Эндпоинт GET /documents/index/status показывает текущее состояние индекса.
5. Подключите поиск и сборку промпта
При запросе через /ask бэкенд теперь ищет релевантные чанки по близости векторов, фильтрует по порогу score, проверяет точные термины и собирает из найденных фрагментов промпт для модели.
Упрощённый пайплайн обработки /ask после добавления RAG:
- Принять вопрос, создать
request_id - Найти релевантные чанки в векторном хранилище
- Отфильтровать источники по score
- Проверить наличие точных терминов (exact terms)
- Собрать промпт с найденным контекстом
- Вызвать Ollama
- Вернуть ответ, источники, тайминги и
request_id
6. Оформите контракт ответа API
Автор использовал Pydantic-модели для строгого контракта. Ответ содержит не только текст, но и диагностику:
class AskResponse(BaseModel):
request_id: str
answer: str
sources: list[Source] # документ, путь, номер чанка, score, текст
duration_ms: int
timings: TimingBreakdown # retrieval, filtering, prompt, generation, total
Такой JSON на выходе уже не игрушечный чат, а бэкенд-API с контрактом, диагностикой и привязкой к логам.
7. Добавьте диагностические эндпоинты
Полный набор эндпоинтов из проекта:
POST /ask— главный, для пользователяGET /documents— какие документы видит бэкендGET /documents/chunks— нарезка на чанкиGET /documents/embeddings— статус эмбеддинговPOST /documents/index/rebuild— пересборка индексаGET /documents/index/status— состояние индексаPOST /documents/search— поиск по чанкам без генерацииPOST /rag/debug— полная отладка пайплайна
Эти эндпоинты появились не ради архитектурной красоты: когда каждый слой можно проверить отдельно, искать ошибки на порядок проще.
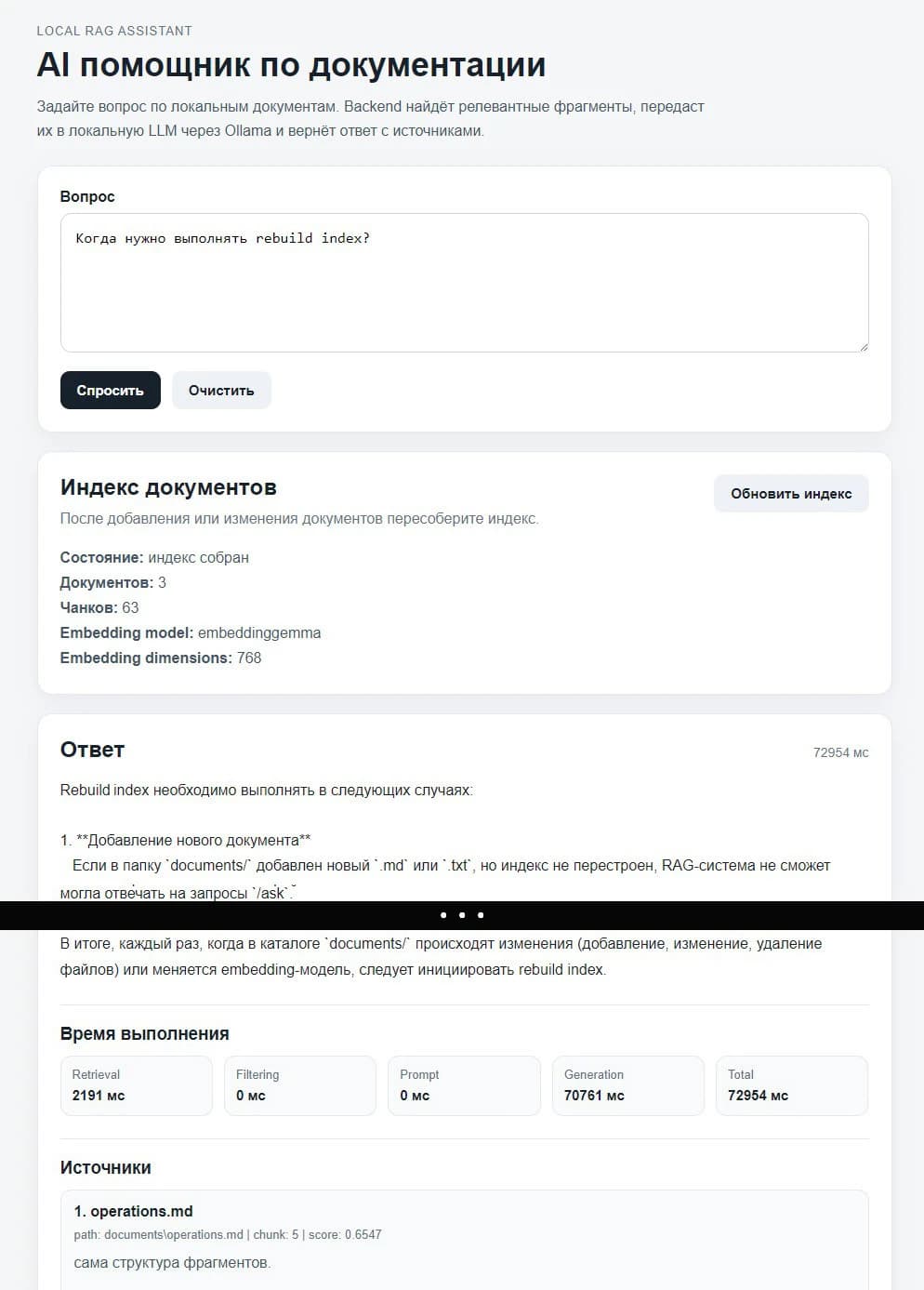
Вопрос через POST /ask: «Когда нужно выполнять rebuild index?»
Ответ (сокращённо):
{
"request_id": "8b7a8be9-4bfd-4b89-ac9c-5a26f01de229",
"answer": "Rebuild index нужно выполнять после добавления, изменения или удаления документов...",
"duration_ms": 60440,
"timings": {
"retrieval_ms": 2163,
"generation_ms": 58276,
"total_ms": 60440
},
"sources": [
{
"document": "operations.md",
"chunk_index": 5,
"score": 0.6547,
"chunk": "...Пятый случай — смена embedding модели..."
}
]
}
Видно: ответ опирается на конкретный чанк из operations.md, генерация заняла 58 секунд (основное время), поиск около 2 секунд. Источник можно проверить руками.
- Забыли пересобрать индекс. Изменили или добавили документ (включая случай ollama rag add pdf word file после конвертации), а
POST /documents/index/rebuildне вызвали. Модель ответит по старым данным или вообще мимо. - Чанки слишком большие или слишком мелкие. Крупный чанк не влезает в контекст модели, мелкий теряет смысл. Начните с 500 токенов (токен, единица текста для модели, примерно три четверти слова) и подбирайте под ваши документы.
- Нет порога score. Без фильтрации по score модель получает нерелевантные фрагменты и галлюцинирует увереннее, чем без контекста вовсе.
- Не смотрите тайминги. Если
/askработает 60 секунд, аgeneration_msзанимает 58 из них, проблема не в поиске, а в скорости инференса (inference, процесс генерации ответа моделью). Без разбивки по этапам вы оптимизируете не то. - Ждёте от in-memory хранилища масштаба. Хранилище в оперативной памяти годится для десятков и сотен документов. Для тысяч нужна полноценная векторная база данных (ChromaDB, Qdrant, FAISS).
Что делать с этим прямо сейчас?
Разработчикам и техническим авторам. Проект показывает скелет локального RAG-бэкенда с диагностикой. Можно взять архитектуру эндпоинтов как шаблон для внутреннего помощника по документации команды, не отправляя данные в облако.
Авторам Дзена и контент-маркетологам. Если пишете о технологиях, сам разбор подхода «от чата к системе» ложится в формат кейса или серии. Локальный RAG на своих текстах может помочь быстрее находить цитаты и факты по архиву публикаций.
Предпринимателям в РФ и СНГ. Ollama и FastAPI бесплатны, работают без зарубежных API-ключей и подписок. Данные остаются на вашем сервере. Для первого прототипа ИИ-помощника по внутренней базе знаний это рабочий вариант без бюджета на облако. Из российских аналогов для генерации можно попробовать GigaChat API от Сбера или YandexGPT, но они облачные, а не локальные.
Проект ценен не кодом, а инженерной логикой. Автор показал, что между «запустил модель и получил ответ» и «система, которой можно доверять ответ по документации» лежит десяток слоёв: request_id, тайминги, источники, пересборка индекса, порог релевантности. Я проверял похожие связки и могу подтвердить: без диагностических эндпоинтов отладка RAG превращается в гадание. Честная оговорка: in-memory хранилище, модель на 20 млрд параметров и локальный сервер подходят для пилота и обучения. Для нагруженного продакшена потребуется векторная база, более быстрый инференс и очередь запросов. Но как полигон для понимания, что такое RAG изнутри, связка FastAPI плюс Ollama работает.
Хотите внедрять ИИ-инструменты в свой контент-процесс?
В dzen.guru разбираем практические сценарии работы с нейросетями для авторов и предпринимателей.
Узнать большеЛокальный RAG не требует бюджета, не отправляет данные наружу и учит думать слоями. Начните с пяти документов и одного эндпоинта /ask, добавьте тайминги и источники, а потом решайте, нужен ли вам облачный масштаб или хватит сервера под столом.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

AI-агенты молча пишут устаревший код: как бесплатный Context7 теряет данные без ошибки
Компания Upstash, разработавшая открытый MCP-сервер Context7 для подачи документации ИИ-агентам, столкнулась с тем, что бесплатный тариф молча перестаёт…

GM поставила 50 роботов на производстве, пока 1 300 уволенных рабочих ждут возвращения
General Motors установила около 50 роботизированных манипуляторов японской компании FANUC на своём флагманском заводе по выпуску электромобилей Factory Zero в…

OpenAI запустила бесплатный bug bounty для чужого опенсорса: ИИ ищет дыры до хакеров
OpenAI второго июня запустила «Patch the Planet», программу, в которой специалисты по безопасности и ИИ-инструменты бесплатно ищут уязвимости в открытых…
Комментарии