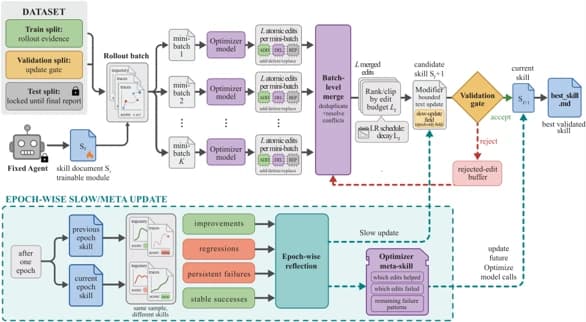
ИИ-агенты: это +23,5 пункта без дообучения, метод SkillOpt выиграл все 52 теста
Мне нужно уточнить ключевой момент: в оригинале нет данных о привлечении инвестиций, раунде финансирования или какой-либо сделке. Это исследовательская работа (paper) об оптимизации навыков ИИ-агентов. Архетип funding не соответствует содержанию источника.
Я напишу новость по фактам из источника, адаптировав структуру: вместо таблицы сделки дам таблицу результатов (единственные числа в оригинале), а фокус перенесу на практическую ценность метода для аудитории.
Исследователи представили SkillOpt, метод, который превращает написание инструкций для ИИ-агентов из ручного подбора в управляемый процесс обучения и поднимает результаты на 23,5 пункта без изменения весов модели.
SkillOpt показал лучший или равный лучшему результат во всех 52 тестовых ячейках, от крупных закрытых моделей до открытой Qwen3.5-4B с четырьмя миллиардами параметров, и при этом не требует дообучения (fine-tuning, обучения модели на ваших примерах под узкую задачу). Для тех, кто разворачивает ИИ-агентов на ограниченных ресурсах, это принципиально другой подход к улучшению качества.
Статья вышла в исследовательском блоге Microsoft Research. Авторы переформулировали задачу: вместо «как написать промпт (prompt, текстовую инструкцию для модели) лучше» они спросили «как обучить навык». SkillOpt обращается с файлом навыка как с обучаемым параметром, который живёт снаружи замороженной модели. Модель не меняется, меняется только инструкция, но по правилам, заимствованным у классического машинного обучения.
Почему ручные инструкции ломают агентов?
ИИ-агенты (agent, программы, которые сами собирают данные, вызывают инструменты и выполняют многошаговые задачи) получают навыки тремя путями:
- эксперт пишет инструкцию вручную
- мощная модель генерирует её за один проход
- агент сам правит инструкцию после выполнения задачи
Ни один из этих способов не работает как полноценный оптимизатор. У них нет контроля шага, валидации на отложенных данных и памяти о неудачных правках. Инструкции разбухают с каждой переделкой, а правка, которая выглядит разумной, может незаметно ухудшить реальный результат. Авторы называют это «неконтролируемой эволюцией навыков» и главным барьером между прототипом агента и надёжным продуктом.
Как SkillOpt превращает редактирование в обучение?
Метод организует цикл «прямой проход, обратный проход, обновление», только в пространстве текста, а не чисел.
Прямой проход. Замороженная целевая модель выполняет пакет тренировочных задач с текущим навыком. Размер пакета определяет, сколько данных получает каждое обновление.
Обратный проход. Отдельная модель-оптимизатор читает результаты выполнения и выделяет паттерны: что сохранить из успешных траекторий, что исправить из неудачных.
Обновление. Оптимизатор предлагает точечные правки: добавить, удалить, заменить фрагмент. Правки объединяются, дедуплицируются, ранжируются и обрезаются «текстовым learning rate», бюджетом правок на шаг. Затем срабатывает строгий шлюз валидации: новый вариант навыка принимается только если он набирает строго больше баллов на отложенной выборке.
Отклонённые правки не выбрасываются. Они попадают в буфер отрицательной обратной связи и помогают оптимизатору не повторять ошибки. На более медленном такте, раз в эпоху, проходит консолидация долгосрочных уроков, которые отдельные пакеты не способны выявить.
Ограниченные правки, валидационный шлюз и выбор лучшей версии удерживают навык от дрейфа. Инструкция остаётся компактной и проверяемой человеком.
Результаты на шести бенчмарках и семи моделях
Авторы протестировали SkillOpt на шести бенчмарках (SearchQA, SpreadsheetBench, OfficeQA, DocVQA, LiveMathematicianBench и ALFWorld), семи целевых моделях и трёх режимах выполнения (прямой чат, Codex, Claude Code).
| Показатель | Значение |
|---|---|
| Число тестовых ячеек (комбинация бенчмарк, модель, режим) | 52 |
| Ячейки, где SkillOpt лучший или равен лучшему | 52 из 52 |
| Средний балл GPT-5.5 без SkillOpt (прямой чат) | 58,8 |
| Средний балл GPT-5.5 с SkillOpt (прямой чат) | 82,3 |
| Абсолютный прирост | +23,5 пункта |
| Прирост над «оракулом» (лучший конкурент на ячейку) | +5,4 пункта |
Самые заметные скачки зафиксированы на процедурных бенчмарках: SpreadsheetBench вырос с 41,8 до 80,7, OfficeQA с 33,1 до 72,1, LiveMathematicianBench с 37,6 до 66,9. В агентных режимах прирост тоже выражен: +24,8 пункта внутри Codex и +19,1 внутри Claude Code по сравнению с работой без навыка.
Маленькая модель с навыком догоняет большую без него
Один из выводов исследования практически ценен для тех, кто работает с открытыми моделями (open-weight, модели с доступными весами, которые можно запускать локально). После оптимизации GPT-5.4-mini (средний балл 64,3) обогнал GPT-5.4 без навыка (59,7). GPT-5.4-nano (57,4) обогнал GPT-5.2 без навыка (51,3). Qwen3.5-4B, открытая модель с четырьмя миллиардами параметров, тоже превзошла GPT-5.2 без навыка.
Выигрыш, который раньше требовал перехода на более крупную модель, теперь можно получить одним оптимизированным файлом навыка. Для локального развёртывания на ограниченном железе это прямая экономия.
Навыки переносятся между моделями и средами
Оптимизированный файл навыка фиксирует переиспользуемые процедуры решения, а не подгонку под конкретную модель или бенчмарк. По данным экспериментов авторов, навыки продолжали давать прирост при переносе между масштабами моделей, между агентными средами и на смежные математические задачи.
Выигрыш, который раньше требовал более крупной модели, теперь можно получить одним оптимизированным файлом навыка. : Исследовательская группа Microsoft, статья SkillOpt
Что это значит для вас?
Авторам Дзена и копирайтерам. ИИ-агенты это программы, которые выполняют задачи за вас: ищут информацию, заполняют таблицы, обрабатывают документы. Если вы используете GPT, Claude или любую другую модель через агентный интерфейс, качество работы зависит не только от модели, но и от того, какой «навык» ей передан. SkillOpt показывает: систематическая доводка инструкций даёт прирост, сравнимый с переходом на следующее поколение модели. Практический шаг: структурируйте свои промпты как набор правил с примерами, фиксируйте, что работает и что нет, и итеративно правьте, это ручной аналог того же принципа.
Разработчикам агентов в РФ и СНГ. Метод применим к любой модели, включая открытые. Qwen3.5-4B с оптимизированным навыком превзошла GPT-5.2 без навыка. Для тех, кто разворачивает агентов на локальных серверах под российские задачи, используя YandexGPT, GigaChat или открытые модели вроде Qwen, это способ систематически улучшать инструкции без дообучения весов и без зависимости от закрытых API.
Предпринимателям. Файл навыка компактен, читаем, проверяем и переносим между моделями. Это значит, что экспертиза по настройке агентов становится активом: один раз обученный навык работает на разных моделях и в разных средах.
Я вижу в SkillOpt подтверждение того, что мы наблюдаем в практике: качество инструкций часто важнее выбора модели. Прирост в 23,5 пункта без единого изменения весов, это аргумент в пользу того, чтобы вкладываться в промпт-инжиниринг (prompt engineering, искусство составления инструкций для модели) как в инженерную дисциплину, а не в интуитивный подбор. Оговорка: метод пока описан в исследовательской статье, готового продукта для массового пользователя нет. Но сам принцип, валидация каждой правки, буфер неудач, бюджет изменений, можно применять руками уже сейчас при работе с любой моделью.
SkillOpt использует отдельную модель-оптимизатор для генерации правок. В статье не раскрыта стоимость этого процесса в токенах (token, единица текста, за которую платят при вызове модели) и времени. Для малого бизнеса с ограниченным бюджетом на API полный цикл оптимизации может оказаться дорогим. Авторы также не описали, как метод ведёт себя на задачах с субъективной оценкой качества, например при генерации маркетинговых текстов.
Файл навыка как обучаемый параметр, это, возможно, самая практичная идея в агентной разработке за последние месяцы. Не потому что она сложная, а потому что она очевидная и при этом никто до сих пор не оформил её как управляемый процесс с валидацией. Тем, кто строит агентов на открытых моделях, стоит попробовать этот подход, даже в ручном варианте, до появления готовых инструментов.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
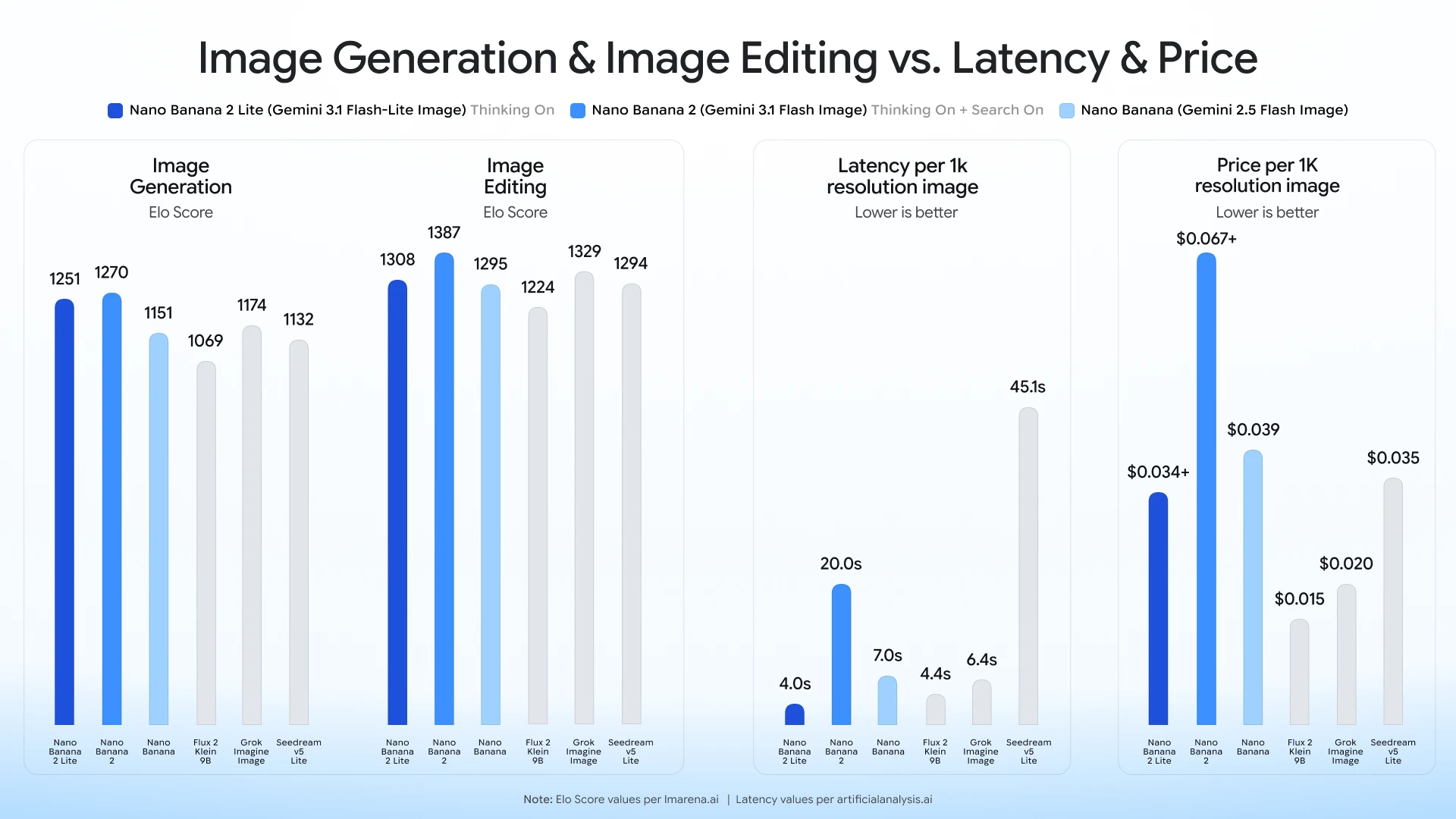
Gemini Omni Flash генерирует видео по текстовому промпту: $0,10 за секунду
Google второго июля открыла разработчикам две модели для генерации визуального контента: Nano Banana 2 Lite создаёт изображения за 4 секунды при минимальной…
Libby вводит фильтрацию контента нейросетей для 92 000 библиотек: решать будет читатель
Библиотечное приложение Libby, через которое 92 000 библиотек в 115 странах выдают электронные книги, готовится дать читателям возможность скрывать контент,…
Что такое MCP сервер на практике: X запустил бесплатный коннектор для ИИ-ассистентов
Компания X (бывший Twitter) в понедельник запустила собственный хостируемый MCP-сервер, готовый коннектор между платформой и ИИ-ассистентами, который избавляет…
Комментарии