GPU для нейросетей в облаке: как выбрать карту и не переплатить за простой
Выбор GPU для нейросетей в 2025 году остаётся болезненной точкой для российских компаний: закупка физических видеокарт требует месяцев ожидания и миллионов рублей авансом, а облачные альтернативы путают разнообразием тарифов и конфигураций.
Эта инструкция поможет разобраться, когда нужна физическая карта, когда хватит виртуальной (vGPU), и как арендовать мощности в облаке VK Cloud так, чтобы не переплатить за простаивающие ресурсы.
Аренда GPU в облаке переводит капитальные затраты в операционные: вы платите только за часы реальной работы и можете масштабировать мощность за минуты, а не за месяцы закупки и монтажа.
Физическая карта или облачный GPU для нейросетей?
Прежде чем переходить к шагам, разберёмся с базовым выбором. GPU (graphics processing unit, графический процессор) в контексте нейросетей используется не для отрисовки картинки на мониторе, а для параллельных вычислений. Там, где центральный процессор (CPU) решает задачи по очереди, GPU обрабатывает тысячи операций одновременно. Именно это свойство делает GPU для нейросетей главным рабочим инструментом: обучение модели, инференс (получение ответа от готовой модели), транскодирование видео, рендеринг 3D.
Проблема в том, что собственная GPU-инфраструктура требует крупных капитальных вложений (CapEx), регулярного обновления оборудования и квалифицированных инженеров для обслуживания. По данным Дмитрия Сергеева, менеджера продукта «виртуальные серверы» (GPU) в VK Tech, всё больше компаний переходят на аренду мощностей, потому что это даёт четыре конкретных преимущества:
- Операционные расходы вместо капитальных. Платите за часы работы, а не за железо на складе.
- Запуск за минуты. Нет ожидания поставки и монтажа.
- Гибкое масштабирование. Добавляете или убираете мощность под текущую нагрузку.
- Провайдер обслуживает оборудование. Обновления, отказоустойчивость, замена вышедших из строя карт ложатся не на вас.
Что понадобится
- Аккаунт в облаке VK Cloud (регистрация бесплатна, оплата по факту использования).
- Понимание задачи: обучение модели, инференс, рендеринг, виртуальные рабочие места (VDI, удалённые рабочие столы с GPU в облаке).
- Ориентировочный объём видеопамяти, который требует ваша модель (например, LLaMA-2 на 70 млрд параметров требует от 140 Гб).
- 15 минут на выбор конфигурации и запуск виртуальной машины.
Пошаговая инструкция
-
Определите задачу и размер модели. Запишите, что именно вы будете делать: дообучение (fine-tuning, обучение модели на ваших примерах под узкую задачу), инференс готовой модели, рендеринг видео или развёртывание удалённых рабочих мест. От задачи зависит выбор карты.
-
Выберите класс ускорителя под задачу. В VK Cloud доступны несколько линеек. Вот три основные:
-
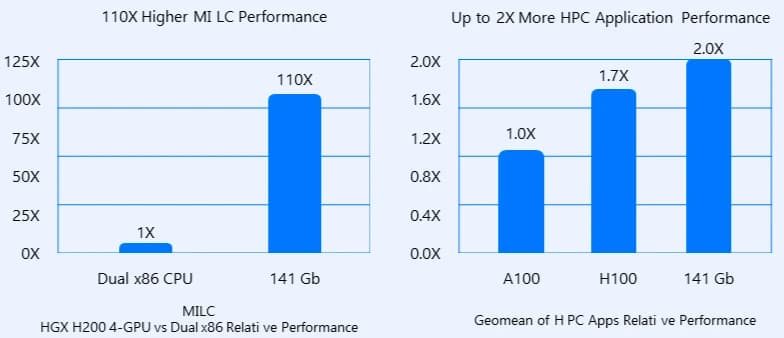
Cloud GPU 141 Гб. Ускоритель с видеопамятью HBM3e объёмом 141 Гб и пропускной способностью 4,8 ТБ/с. Позволяет запускать крупные открытые модели (опенсорс) целиком: LLaMA-2 на 70 млрд параметров, gpt-oss на 120 млрд параметров. Для ещё большей мощности несколько таких карт объединяются на серверной платформе HGX (восемь GPU в формфакторе SXM5, соединённых высокоскоростной сетью InfiniBand 400 Гбит/с).
- L40S. Универсальный ускоритель. Подходит и для обучения моделей, и для инференса, и для 3D-рендеринга. По словам VK Tech, L40S предлагает больше TFLOPS (единиц вычислительной мощности) в формате FP32 при более низкой стоимости аренды в час, чем A100. Это делает его разумной альтернативой для машинного обучения и серверной визуализации.
-
L4 24 Гб. Ускоритель для обработки видео, лёгких ИИ-задач и виртуальных рабочих мест. Позволяет сотрудникам работать с графикой, 3D-проектированием, архитектурными чертежами и анимацией из любой точки мира через облако.
-
Решите: физическая карта (passthrough) или виртуальная (vGPU). Карты в VK Cloud подключаются как PCI-устройства и пробрасываются напрямую в виртуальную машину (технология passthrough). Между виртуальной машиной и физической картой работает слой гипервизора, который позволяет при необходимости делить одну физическую карту между несколькими виртуальными машинами (vGPU). Используйте физический проброс, когда вам нужна вся мощность карты: обучение крупной модели, пиковая нагрузка. Используйте vGPU, когда задача не нагружает карту на 100%: инференс небольших моделей, VDI-рабочие места, лёгкий рендеринг.
-
Создайте виртуальную машину с выбранным GPU в панели VK Cloud. Укажите конфигурацию, объём оперативной памяти и диска. Запуск занимает несколько минут.
-
Установите драйверы и фреймворк. Для задач машинного обучения это обычно CUDA и PyTorch или аналог. Для рендеринга убедитесь, что драйвер поддерживает нужное приложение.
-
Запустите тестовую нагрузку, оцените расход ресурсов и скорректируйте конфигурацию. Если карта загружена менее чем на 50% в пиках, рассмотрите переход на vGPU или на карту классом ниже.
Допустим, вы хотите запустить LLM-ассистента (LLM, large language model, большая языковая модель) для внутренней базы знаний компании с использованием RAG (retrieval-augmented generation, генерация ответов с подтягиванием данных из вашей базы). Модель LLaMA-2 на 70 млрд параметров требует большого объёма видеопамяти. Вы выбираете Cloud GPU 141 Гб, создаёте виртуальную машину, загружаете веса модели, подключаете RAG-пайплайн к корпоративным документам. Ассистент отвечает на вопросы сотрудников, используя именно ваши данные. Когда нагрузка снижается (ночью, в выходные), вы останавливаете машину и не платите за простой.
Аренда самой мощной карты «на всякий случай». Если ваша задача не требует 141 Гб видеопамяти, вы переплачиваете каждый час. Начните с L4 или L40S, измерьте реальное потребление, и только потом масштабируйтесь вверх.
Игнорирование vGPU. Многие арендуют целую физическую карту для задач, которые загружают её на 20%. Виртуальный GPU позволяет разделить одну карту между несколькими рабочими нагрузками и платить меньше.
Забыли остановить машину. Облачная аренда тарифицируется по времени. Оставили виртуальную машину работать на выходные без нагрузки, заплатили за 48 часов впустую. Настройте автоматическое выключение или хотя бы напоминание.
Путаница между обучением и инференсом. Для дообучения модели нужна максимальная мощность на ограниченное время. Для инференса (ежедневные ответы модели) хватает карты поскромнее, но она работает постоянно. Это разные бюджетные модели, не смешивайте их в одной конфигурации.
Что делать с этим прямо сейчас?
Автору Дзена и копирайтеру. Если вы используете локальные открытые модели для генерации текстов или изображений и упираетесь в слабую видеокарту домашнего компьютера, облачный GPU для нейросетей решает проблему без покупки нового железа. Арендуете L4 на пару часов, запускаете генерацию, выключаете.
Маркетологу. RAG-ассистенты на базе LLM, обученные на ваших продуктовых документах, могут отвечать клиентам точнее, чем универсальный чат-бот. Облачный GPU позволяет протестировать такого ассистента за дни, а не за месяцы.
Предпринимателю в РФ. VK Cloud работает в российской юрисдикции, данные остаются на территории страны. Это снимает вопросы комплаенса, которые возникают при использовании зарубежных облаков. Начните с минимальной конфигурации, оцените экономику и масштабируйте по мере роста нагрузки.
По моим наблюдениям, главная ошибка при выборе GPU для нейросетей не техническая, а управленческая: компании покупают или арендуют мощность «с запасом», потому что не измерили реальную нагрузку. Прежде чем выбирать между Cloud GPU 141 Гб и L40S, проведите тестовый прогон на минимальной конфигурации и замерьте, сколько видеопамяти и вычислительных циклов потребляет ваша задача. Экономия может составить значительную долю бюджета.
Честная оговорка: облачная аренда выгоднее, когда нагрузка неравномерная или проект на ранней стадии. Если модель работает круглосуточно на полной мощности месяцами, стоимость аренды может сравняться с покупкой собственного оборудования. Считайте TCO (total cost of ownership, полную стоимость владения) до принятия решения, а не после.
Попробуйте AI-ассистент dzen.guru
Генерируйте черновики и заголовки для Дзена с помощью нашего ИИ-инструмента, который уже работает на облачных GPU
Попробовать бесплатноРешение между собственным железом и облаком сводится к одному вопросу: ваша нагрузка постоянная или пиковая. Если пиковая, арендуйте и платите только за рабочие часы. Если постоянная, считайте, на каком месяце аренда догонит покупку. Начните с теста на минимальной конфигурации в VK Cloud, реальные цифры потребления скажут больше любого калькулятора.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

ИИ-агенты это модель плюс инструменты: архитектура на 20 строках кода
Автор Дзена или маркетолог, который слышит «сделайте нам ИИ-агента» и хочет понять, что стоит за этим словом, после этого разбора увидит архитектуру агента…
6 ошибок архитектуры AI агентов, которые ломают продакшен на длинных цепочках
повторные вызовы с одними и теми же аргументами учащаются. На длинных цепочках качество решений деградирует заметно. Причина. Контекстное окно модели — это…
ИИ-агенты: это рынок на триллион, и OKX строит для них «биржу фриланса»
Почему это важно Криптобиржа с аудиторией более 150 млн пользователей открыла маркетплейс, где ИИ-агенты сами находят друг друга, платят за услуги…
Комментарии