Дата-центры для ИИ: почему 40 кВт на стойку ломают стандартную схему модульного ЦОДа
Компания, опубликовавшая оригинал, описывает свой инженерный опыт проектирования модульного ЦОДа под GPU-нагрузки. Это не классическая новость с датой и событием, а технический разбор. Адаптирую под формат how-to для аудитории dzen.guru, строго по фактам из источника.
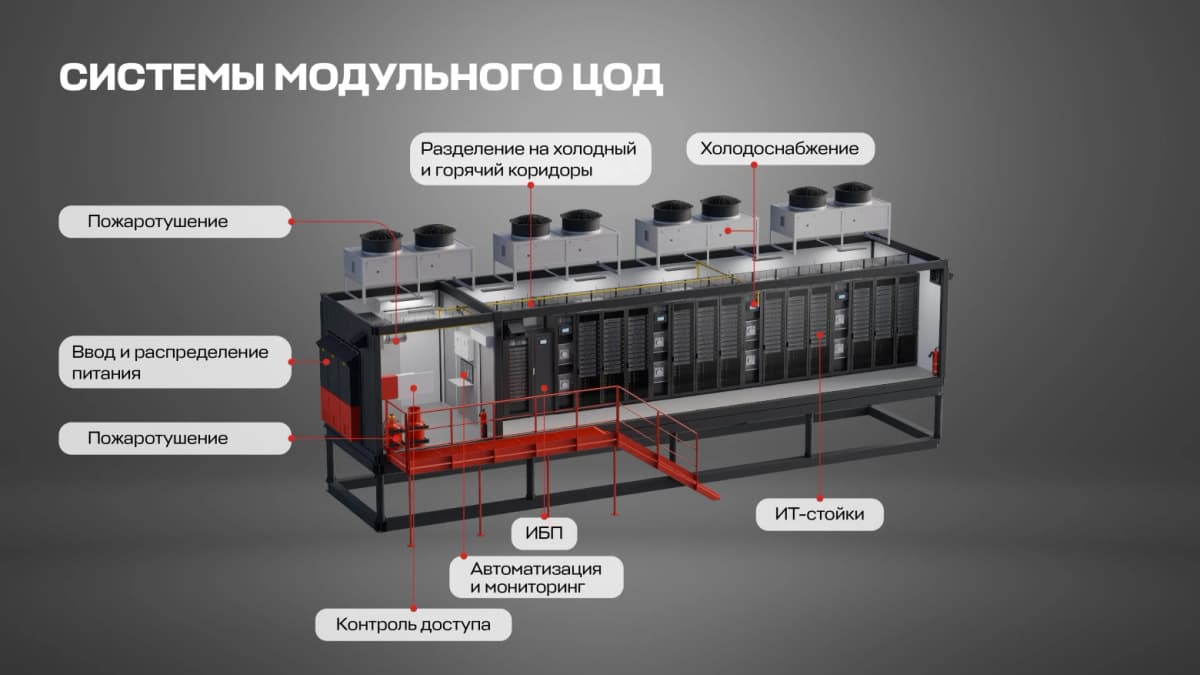
Российские инженеры взялись за пилотный проект модульного дата-центра для ИИ и обнаружили, что стандартная схема модульного ЦОДа не выдерживает нагрузку GPU-серверов класса H100 и H200, а ключевые решения по охлаждению, питанию и компоновке приходится пересобирать с нуля.
Плотность 40-42 кВт на стойку ломает привычную логику «поставим серверы в контейнер»: охлаждение начинает диктовать всю компоновку модуля, а не подстраиваться под неё.
Дата-центры для ИИ (дата центры ии) выглядят снаружи как обычные модульные ЦОДы: блок-контейнер, стойки, источники бесперебойного питания, распределительное оборудование, система охлаждения. Но как только вместо стандартных серверов в стойки встают GPU-ускорители, нагрузка вырастает в 2-3 раза. Об этом рассказывает рабочая группа инженеров, которая полгода проектирует пилотный AI-ready модуль и уже приняла базовые инженерные решения, хотя итоговую конфигурацию пока не утвердила.
Чем дата центры ии отличаются от обычных модульных ЦОДов?
Обычный модульный ЦОД (МЦОД, компактный контейнерный дата-центр, который можно развернуть без капитального строительства) проектируют «от ИТ-ёмкости к инженерным параметрам». Проще говоря, сначала считают, сколько стоек нужно, потом подбирают питание и охлаждение.
В AI-ready модуле логика обратная: сначала надо понять, как отводить тепло и как обслуживать оборудование, и только потом согласовывать это с нагрузкой.
Вот что конкретно меняет рост плотности до 40-42 кВт на стойку:
- Тепловыделение растёт кратно, охлаждение диктует компоновку всего модуля
- Требования к источникам бесперебойного питания (ИБП) усиливаются
- Токовые нагрузки и номиналы распределительного оборудования растут
- Источники питания разных систем разделяются по критичности
- Мониторинг расширяется: к температуре модуля добавляется состояние систем вокруг каждой стойки
- Сервисная доступность (возможность физически добраться до оборудования для ремонта) становится проектным ограничением
Что понадобится
- Понимание типа GPU-нагрузки. Инженеры проверяли три сценария: ускорители A100 и L40S для лёгких задач, H100 и H200 как базовую точку (40-42 кВт на стойку), B200 как перспективную тяжёлую нагрузку
- Модуль достаточного размера. В пилоте заложили 12-метровый контейнер шириной около 3-3,2 метра с несколькими ИТ-шкафами и телеком-стойкой. Глубина стоек 1200 мм
- Выбор схемы охлаждения. Именно охлаждение определяет, поместится ли всё остальное
- Инженерное подполье. Под фальшполом прокладывают силовые трассы, трубопроводы охлаждения, дренаж и систему контроля протечек
- Система мониторинга, которая покрывает не только температуру воздуха, но и состояние подполья, протечки, нагрузку на каждую стойку
Пошаговая инструкция: как спроектировать модуль дата центра ии
-
Определите тепловой баланс, а не количество стоек. Начинайте не с вопроса «сколько серверов разместить», а с вопроса «сколько тепла нужно отвести». Для GPU-серверов класса H100 и H200 расчётная плотность составляет 32-45 кВт на стойку, базовая точка проектирования 40-42 кВт.
-
Выберите схему охлаждения под габариты модуля. Инженеры пилота рассмотрели три варианта и отбросили первый:
- RDHx (двери-теплообменники на задней стенке стойки, через которые горячий воздух отдаёт тепло водяному контуру). Забраковали: дверь добавляет около 400 мм к глубине стойки, в 12-метровом модуле это съедает проходы и сервисные площадки
- In-Rack (охлаждение внутри стойки, где воздух циркулирует замкнуто через встроенный теплообменник). Стойка становится самостоятельным тепловым контуром, не зависит от коридорной планировки. Полезно для компактного модуля
-
Direct-to-Chip, D2C (жидкостное охлаждение, когда теплоноситель подводится напрямую к GPU и CPU). Тепло уходит через жидкость в CDU (распределительный узел охлаждения, который передаёт тепло во внешний контур с драйкулером, сухой градирней)
-
Не забудьте воздушное охлаждение как вспомогательное. Даже при D2C в модуле остаются тепловые потери от инженерных систем: ИБП, распределительного оборудования, низковольтных комплектных устройств (НКУ), автоматики. Для них сохраняется воздушное охлаждение.
-
Спроектируйте кабельные трассы до компоновки стоек. Команда пилота на этапе технического задания планировала использовать только боковые и верхние лотки, но в итоге задействовала инженерное подполье. Под фальшполом идут силовые трассы, трубопроводы, дренаж и датчики протечек. Доступ через съёмные панели.
-
Заложите сервисную доступность как проектное ограничение. Модуль должен быть не только компактным, но и обслуживаемым. Инженер должен добраться до труб, кабелей, датчиков и оборудования, если что-то потечёт, перегреется или выйдет из строя.
-
Расширьте мониторинг. В обычном ЦОДе достаточно следить за температурой. В AI-ready модуле мониторинг охватывает состояние систем вокруг каждой стойки и инженерного подполья, включая визуальный контроль.
Команда пилота заложила 12-метровый модуль с глубиной стоек 1200 мм и шириной контейнера около 3-3,2 метра. При попытке установить RDHx-двери (плюс 400 мм к глубине) проходы сузились до непригодных для обслуживания. Инженеры отказались от RDHx и перешли к схемам In-Rack и Direct-to-Chip. Параллельно обнаружили, что кабели не помещаются в верхние лотки, и перевели часть трасс под фальшпол, превратив его в полноценное инженерное подполье с дренажом и датчиками протечек.
«Просто поставим GPU-серверы в контейнер обычного МЦОДа». Именно эта гипотеза провалилась первой. При нагрузке 40-42 кВт на стойку стандартная компоновка не работает: охлаждение, кабели, проходы для обслуживания не помещаются.
Выбирать охлаждение без учёта габаритов модуля. RDHx-двери отлично работают в классическом машинном зале, но в компактном контейнере съедают критичные сантиметры.
Забыть про обслуживание. Красивый рендер может нарисовать кто угодно. В реальном проекте важно, как инженер физически доберётся до труб и кабелей при аварии.
Игнорировать тепловые потери инженерных систем при жидкостном охлаждении. D2C снимает тепло с GPU, но ИБП, распределительное оборудование и автоматика по-прежнему греют воздух. Без вспомогательного воздушного охлаждения модуль перегреется.
Что делать с этим прямо сейчас, по ролям
Инженерам и проектировщикам ЦОД. Если планируете AI-нагрузки, начинайте проектирование не с количества стоек, а с теплового баланса. Проверьте три сценария плотности (лёгкий, базовый, перспективный), как это сделала команда пилота.
Предпринимателям и техническим директорам. Пилот AI-ready пока на этапе разработки, итоговую конфигурацию не утвердили. Но базовые решения уже показывают: собственный ИИ-контур на площадке требует переосмысления инженерной инфраструктуры, а не просто закупки GPU.
Авторам Дзена, которые пишут про технологии. Тема дата центров ии на русскоязычном рынке пока освещена слабо. Инженерный разбор с конкретными цифрами (кВт на стойку, габариты модуля, причины отказа от конкретных схем охлаждения) даёт материал, который выделяется на фоне общих обзоров про «будущее ИИ».
Этот проект честен в одном: команда открыто говорит, что пилот ещё не завершён и итоговая конфигурация не утверждена. Для рынка, где презентации обгоняют реальность на годы, это ценно.
По моим наблюдениям, в России пока мало публичных инженерных разборов того, как именно строят инфраструктуру под GPU-нагрузки. Большинство материалов сводится к маркетинговым описаниям готовых решений. Здесь виден живой процесс: гипотеза провалилась, пересчитали, выбрали другую схему, снова упёрлись в габариты.
Оговорка: пока это пилот с расчётными параметрами, а не запущенный объект с реальными замерами. Между проектом и эксплуатацией всегда есть зазор, и до итоговых выводов о надёжности схемы далеко.
Главный урок этого пилота укладывается в одну фразу: GPU-модуль проектируют от тепла и доступа, а не от количества стоек. Кто начнёт с обратного конца, потеряет время и повторит ту же ошибку, которую команда описала честно: «первая гипотеза провалилась, как только мы начали считать нагрузку».
Нейроскрайбер
Генерируйте тексты для Дзена с помощью ИИ, который знает правила платформы
Попробовать бесплатно
Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также

Локальная нейросеть на ПК с 4 ГБ видеопамяти: пошаговая настройка без облака и подписок
Локальная нейросеть на домашнем ПК с Windows 11 решает конкретную задачу: вы получаете языковую модель, которая работает без облака, без подписки и без…
37% новых треков на Яндекс Музыке сгенерированы: нейросеть для создания музыки научились детектить без GPU
Нейросеть для создания музыки бесплатно генерирует треки, которые уже составляют больше трети новых релизов на Яндекс Музыке, и теперь есть способ отличить их…
Компьютерное зрение на палубе судна: как трёхуровневая валидация убирает ложные тревоги
Компьютерное зрение (computer vision, технология, позволяющая нейросети «видеть» и анализировать изображения с камер) на открытой палубе судна сталкивается с…
Комментарии