Что такое ИИ-агент с песочницей: собираем прототип на LangGraph и Docker
Автору или разработчику, который хочет понять, что такое ИИ-агент с песочницей и собрать рабочий прототип на LangGraph с изолированным исполнением кода в Docker, эта инструкция даёт пошаговый разбор архитектуры и готовый код из открытого репозитория.
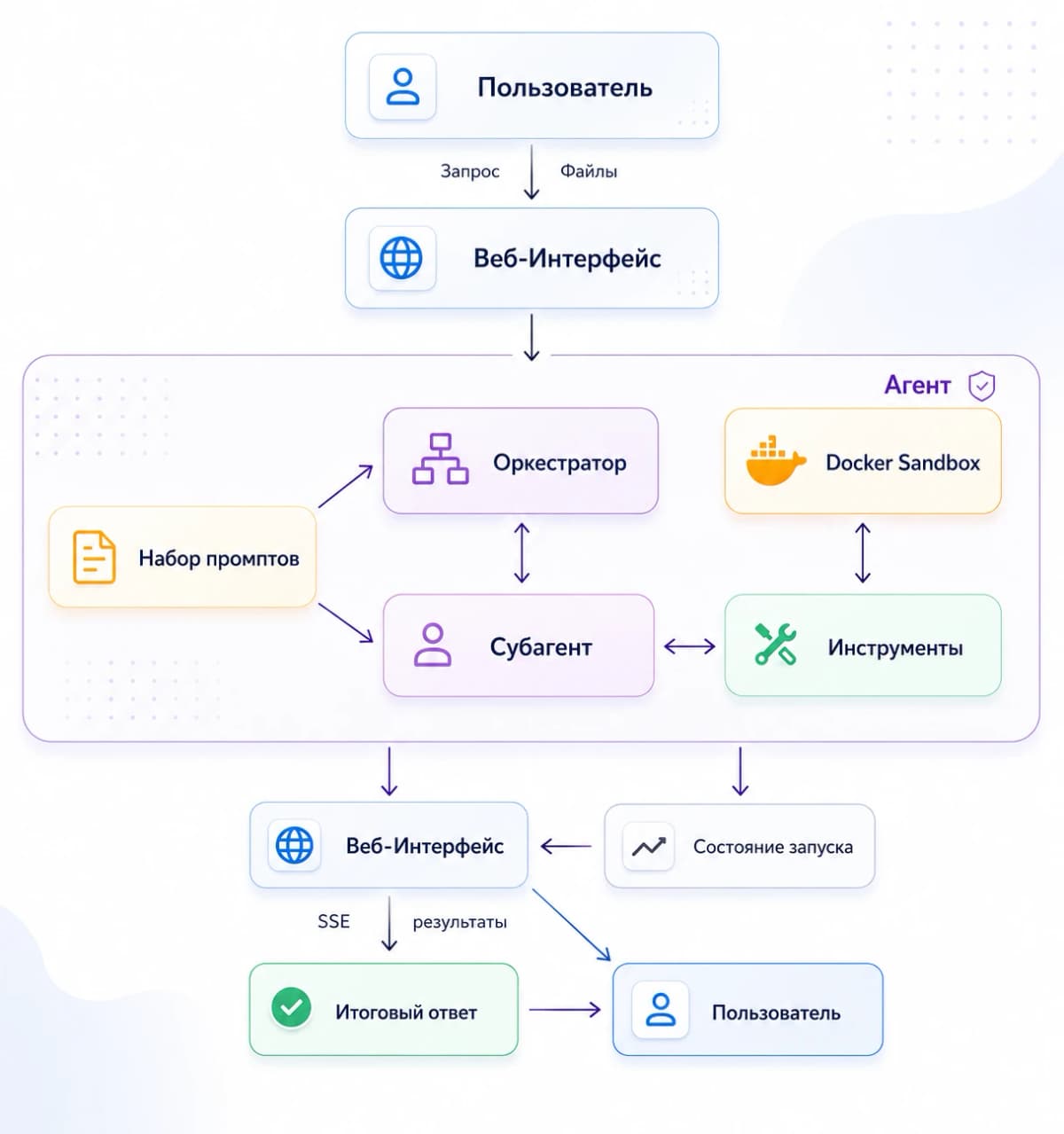
Когда ИИ-агент пишет и запускает код, он может повредить систему или данные. Песочница (изолированная среда) решает проблему: код работает в контейнере, а ваша машина остаётся нетронутой. Ниже разбираем конкретную реализацию, которую можно поднять локально.
Материал основан на практическом руководстве разработчика Евгения, лида ML-команды, который опубликовал вторую часть серии про LLM Sandbox. Первая часть покрывала теорию: риски исполнения кода от LLM (большой языковой модели), способы изоляции через Docker, Wasm, gVisor и microVM. Здесь мы переходим к практике: оркестратор, субагенты, навыки и сама песочница. Полный код, логи и артефакты лежат в открытом GitHub-репозитории автора.
Что понадобится
- Docker на локальной машине (для запуска песочницы)
- Python 3.10+ и менеджер пакетов pip
- LangGraph (фреймворк для построения агентных графов)
- Модель Qwen3.5-27B или любая OpenAI-совместимая модель (переключается через переменную
LLM_MODEL) - GitHub-репозиторий автора с полным кодом агента, навыками и примерами
- Примерно 2 часа на первый запуск с разбором архитектуры
Как устроен агент внутри?
Прежде чем собирать, стоит понять, что такое ИИ-агент в этой архитектуре. Это программа, которая получает задачу от пользователя, сама разбивает её на подзадачи, пишет код для каждой и запускает его в изолированном контейнере.
Паттерн работы: гибрид ReAct и Plan-Execute. ReAct означает цикл «рассуждение плюс действие»: агент думает, что делать, выполняет шаг, смотрит на результат и решает, что дальше. Plan-Execute добавляет предварительное планирование: сначала список задач, потом последовательное выполнение.
Агент состоит из четырёх блоков, каждый со своей ролью.
Пошаговая инструкция
- Клонируйте репозиторий и установите зависимости
git clone <URL репозитория автора>
cd llm-sandbox-agent
pip install -r requirements.txt
- Разберитесь с оркестратором. Оркестратор обрабатывает запрос пользователя, планирует решение и раздаёт подзадачи субагентам. У него свой системный промпт (системный промпт, это базовая инструкция, которая задаёт модели роль и правила поведения). Оркестратор управляет подзадачами через четыре инструмента:
create_todo_listсоздаёт набор подзадачstart_next_todoзапускает следующуюcomplete_todoзакрывает выполненную-
revise_todo_listпересобирает план, если что-то пошло не так -
Настройте субагентов. Субагент (subagent) это отдельная сессия с LLM и чистым контекстным окном. Оркестратор передаёт ему конкретную задачу и нужный контекст. Смысл: основной агент не перегружается, каждая подзадача решается независимо.
-
Подготовьте каталог навыков (skills). Skills это подробные инструкции под конкретные задачи. Например, в папке
skills/presentationполностью описан процесс создания презентаций. Оркестратор и субагенты видят название и описание каждого навыка, а полную инструкцию подгружают через инструментread_skill. -
Сконфигурируйте Docker-песочницу. Песочница создаёт отдельный контейнер на время выполнения подзадачи. Ключевые флаги безопасности при запуске:
docker run \
--network=none \
--read-only \
--cap-drop=ALL \
--security-opt=no-new-privileges \
--user <non-root> \
--memory=512m \
--cpus=1 \
--pids-limit=64 \
--tmpfs /tmp \
--mount type=bind,source=./input,target=/workspace/input,readonly \
--mount type=bind,source=./code,target=/workspace/code,readonly \
sandbox-image
Контейнер отрезан от сети, работает с правами обычного пользователя, ограничен по памяти, процессору и числу процессов. Входные файлы и код монтируются только для чтения.
- Запустите агента с тестовой задачей. Субагент использует два инструмента для работы с кодом:
write_python_fileсохраняет скрипт в/workspace/code-
run_python_fileзапускает его внутри песочницы -
Проверьте результаты. Логи доступны локально в
agent/runs/<run_id>/events.jsonlиagent/traces/<run_id>.jsonl. Выходные файлы лежат вagent/web-artifacts/<run_id>/. В интерфейсе видны текущий план, закрытые подзадачи и вызовы инструментов.
Автор демонстрирует работу на датасете соревнования «Титаник». Промпт: «Проанализируй набор данных и подготовь презентацию с ключевыми выводами EDA (разведочного анализа данных)».
Агент создал две подзадачи:
- eda-analysis: первичный анализ данных с навыками eda и python-scripts, на входе CSV-файл, на выходе сводка eda_summary.csv
- create-presentation: создание PowerPoint-презентации с навыками presentation и python-scripts, на выходе файл titanic_eda_presentation.pptx
Для каждой подзадачи заданы входные и выходные файлы, а также критерии успеха. Агент последовательно запустил подзадачи, исполнил код в песочнице, собрал артефакты и выдал готовую презентацию с графиками и выводами.
Модель: Qwen3.5-27B, которую можно развернуть на доступном железе. Автор использует её как дефолтную, но через переменную LLM_MODEL подключается любая OpenAI-совместимая модель.
Инструменты Bash не предоставляются агенту намеренно. Автор убрал доступ к Bash для прозрачной и контролируемой работы. Если добавить Bash-инструменты, агент может выполнять произвольные команды, и изоляция теряет смысл.
Docker с указанными флагами подходит для локального MVP. Для продуктивной среды может понадобиться многоуровневая изоляция (gVisor, microVM). Не выкатывайте такую конфигурацию в продакшен без дополнительных слоёв защиты.
Контекстное окно субагента чистое, но ограниченное. Если подзадача слишком объёмная, субагент может не уместить результат в контекст. Дробите задачи мельче через revise_todo_list.
Навыки нужно писать подробно. Если skill описан поверхностно, агент будет галлюцинировать (галлюцинация в контексте ИИ означает, что модель уверенно выдумывает то, чего не было). Чем детальнее инструкция в папке skills/, тем предсказуемее результат.
Что с этим делать по ролям?
Разработчику и ML-инженеру. Репозиторий даёт рабочую архитектуру агента с песочницей, которую можно форкнуть и адаптировать. Паттерн оркестратор плюс субагенты на LangGraph переносится на любые задачи, где нужно безопасное исполнение генерируемого кода.
Автору Дзена и контент-мейкеру. Понимание того, что такое ИИ-агент с песочницей, позволяет грамотно писать о технологии и тестировать подобные решения. Агент из примера создаёт презентации и аналитику из данных, это прикладная задача для любого, кто работает с контентом.
Предпринимателю в РФ. Всё работает локально: Docker, открытая модель Qwen3.5-27B, фреймворк LangGraph. Зависимости от зарубежных облаков нет. Можно развернуть на своём сервере и не переживать о блокировках API.
Архитектура «оркестратор плюс субагенты плюс песочница» выглядит избыточной для простых задач. Но для сценариев, где агент генерирует и запускает код, это минимально разумная конструкция. Без изоляции вы буквально отдаёте модели root-доступ к машине.
Я бы рекомендовал начать с простого: поднять репозиторий, прогнать пример с «Титаником», посмотреть логи в events.jsonl. Это даёт интуицию о том, как агент принимает решения и где он ошибается. Потом уже писать свои skills под реальные задачи.
Честная оговорка: для продакшена Docker-песочница с описанными флагами это стартовая точка, не финальная. Автор прямо об этом предупреждает.
Хотите создавать контент с помощью ИИ?
В dzen.guru мы разбираем практические инструменты для авторов, которые хотят использовать нейросети в работе.
Узнать большеФакт, который стоит запомнить: грамотно настроенный ИИ-агент не просто «пишет код по запросу», он планирует, дробит задачу, запускает код в безопасной среде и собирает результат. Репозиторий Евгения показывает, как это выглядит на практике, с полным кодом и логами, бери и разбирай.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
Alibaba скопировала модель Claude
Alibaba, по данным Anthropic, провела крупнейшую атаку на Claude: 28,8 млн запросов через 25 000 поддельных аккаунтов за полтора месяца, чтобы скопировать…

Amazon вложит $13 млрд в инфраструктуру Индии: инвестиции в искусственный интеллект достигли $48 млрд
Amazon в четверг объявила о дополнительных инвестициях в размере 13 млрд долларов в расширение ИИ-инфраструктуры и облачных мощностей в Индии до 2030 года,…

Notion закрывает email клиент: больше половины пользователей уже ведут почту через ИИ-агентов
Notion 22 сентября закроет Notion Mail на всех платформах, заявив, что больше половины пользователей уже управляют почтой через ИИ-агентов, ни разу не открывая…
Комментарии