Что такое галлюцинации нейросетей в науке: инструмент ловит фальшивые ссылки в PDF
Нейросеть, которая проверяет научные ссылки, теперь работает с кириллицей, OCR и кривыми PDF, и вот как ей пользоваться.

Галлюцинации нейросетей проникают в научные статьи через фальшивые ссылки, и до сих пор не было инструмента, который проверял бы библиографию с учётом русскоязычных источников и типичных ошибок распознавания текста.
Выпускница российского вуза защитила дипломный проект на отлично (работу отметили лучшей в день защиты) и продолжила развивать систему автоматической проверки подлинности источников в научных публикациях. Первая версия была учебным прототипом, теперь это инженерный инструмент с OCR (распознаванием текста из сканов), кэшированием запросов, офлайн-режимом и классификацией типов ошибок. Проект опубликован на Хабре и описывает, что такое галлюцинации нейросетей применительно к научной библиографии: когда ИИ уверенно генерирует несуществующие ссылки на статьи, а рецензент принимает их за настоящие.
Зачем это нужно автору или исследователю?
Проблема выглядит так: вы пишете статью, используете нейросеть для поиска источников, а она подставляет красивую, но выдуманную ссылку. Или наоборот: рецензируете чужую работу и не можете вручную проверить 40 записей в списке литературы.
Система берёт PDF или DOCX, извлекает список литературы, разбирает каждую запись на поля (авторы, название, год, журнал, DOI, URL) и сверяет с внешними базами: Crossref, OpenAlex, Wikidata, ORCID, PubMed, Google Scholar. На выходе не просто «найдено» или «не найдено», а развёрнутый статус с объяснением, что именно не сходится.
Что понадобится
- Научный документ в формате PDF или DOCX
- Доступ к веб-интерфейсу системы (проект описан на Хабре, код открыт)
- Подключение к интернету для проверки по внешним базам (есть и офлайн-режим для работы с кэшированными результатами)
- Около 10 минут на загрузку и анализ документа средней длины
Пошаговая инструкция
-
Загрузите документ. Система принимает PDF и DOCX через веб-интерфейс. Если в PDF нет текстового слоя (например, это скан), автоматически запускается OCR.
-
Дождитесь извлечения текста. Система удаляет повторяющиеся шапки и футеры, ищет библиографический блок не только по очевидным заголовкам вроде «Литература» или «References», но и по структуре документа.
-
Проверьте разбивку на записи. Каждая библиографическая запись разбирается на поля: авторы, название, год, журнал или издатель, том, номер, страницы, DOI, URL. На этом этапе система нормализует текст: исправляет разорванные переносом строки DOI, сломанные форматированием URL, смешение кириллицы и латиницы.
-
Запустите проверку. Система последовательно обращается к DOI-резолверу, проверяет URL, ищет данные в Crossref, OpenAlex, Wikidata, ORCID, PubMed, Google Scholar и через обычный веб-поиск. Результаты кэшируются в SQLite, чтобы повторные проверки не дёргали внешние сервисы.
-
Прочитайте результат. Каждая запись получает статус и перечень конкретных проблем. Возможные статусы:
- Источник подтверждён
- Источник, вероятно, существует, но данных недостаточно
- Источник не удалось подтвердить
- Источник найден, но в записи есть ошибки
-
Запись плохо разобрана и требует ручной проверки
-
Изучите типы ошибок. Система выделяет конкретную причину: ошибка DOI, ошибка URL, несовпадение авторов, несовпадение названия, несовпадение года, несовпадение журнала, риск OCR-искажения, риск некорректного парсинга (разбора записи).
Допустим, в вашей статье есть ссылка на русскоязычный источник без DOI. Система не находит DOI, но обнаруживает совпадение по названию и авторам в OpenAlex. Результат: статус «вероятно подтверждён», а не «не найден». Другой случай: DOI указан, но после OCR один символ исказился. Система нормализует DOI, пробует резолвить исправленный вариант и сообщает: «источник найден, но DOI в записи содержит ошибку, вот корректный».
DOI не равен истине. Отсутствие DOI не означает, что источник фальшивый. У многих русскоязычных публикаций, книг, диссертаций DOI просто нет. Система учитывает это и проверяет по набору сигналов, а не по одному идентификатору.
OCR искажает незаметно. После распознавания текста из скана DOI может выглядеть почти правильно, но быть невалидным. URL может сломаться. Кириллическая «с» может подмениться латинской «c». Если система сообщает «риск OCR», стоит сверить запись с оригиналом вручную.
Статус «не подтверждён» не равен «фейк». Внешний сервис мог не ответить, метаданные могут быть неполными, источник мог быть опубликован в сборнике, который не индексируется крупными базами. Красный статус без указания конкретной причины требует ручной проверки.
Русскоязычные источники проверяются сложнее. Англоязычные базы покрывают их хуже. Система пытается искать через Google Scholar и веб-поиск, но результат менее надёжен, чем для англоязычных статей с DOI.
Что делать с этим прямо сейчас, по ролям
Автору Дзена или копирайтеру. Если вы ссылаетесь на исследования в своих текстах (а это повышает доверие читателей), проверяйте ссылки до публикации. Нейросеть могла «нагаллюцинировать» красивую цитату с несуществующим источником. Этот инструмент покажет, реален ли источник, до того, как комментаторы уличат вас в ошибке.
Исследователю или аспиранту. Перед подачей статьи прогоните список литературы через систему. Она найдёт опечатки в DOI, расхождения в годах, неработающие URL. Для русскоязычных источников это актуальнее, чем для англоязычных: автоматические средства проверки библиографии на русском языке практически отсутствуют.
Рецензенту или редактору журнала. Проверка 30-50 ссылок вручную занимает часы. Система сокращает эту работу до минут и указывает конкретно, какие записи требуют внимания. Это не замена экспертизы, а фильтр первого уровня.
Предпринимателю в EdTech. Если вы строите продукт вокруг научных публикаций или образования, интеграция подобной проверки повышает качество контента. Проект с открытым кодом, можно изучить архитектуру.
По моим наблюдениям, что такое галлюцинации нейросетей, большинство авторов понимают абстрактно: «ИИ иногда врёт». Но конкретный механизм, когда ChatGPT генерирует ссылку на статью, которой не существует, с правдоподобным названием, реальным журналом и похожими на настоящих авторов, это уже не абстракция, а практическая угроза для любого, кто использует нейросеть как помощника при написании текстов.
Этот проект ценен не масштабом (это дипломная работа одного человека, а не корпоративный продукт), а тем, что он решает задачу, которую крупные англоязычные инструменты игнорируют: проверку кириллических источников, работу с кривыми российскими PDF и учёт OCR-артефактов, типичных для отсканированных диссертаций. Я бы рекомендовал следить за развитием проекта и при случае протестировать на своих материалах. Честная оговорка: система не даёт стопроцентной гарантии. Статус «подтверждён» означает, что источник найден во внешних базах, но не что содержание статьи соответствует тому, как на неё ссылаются.
Проверьте свои тексты на галлюцинации ИИ
Используйте инструменты dzen.guru для создания контента, которому можно доверять
ПопробоватьКто работает с научными текстами на русском языке, впервые получает инструмент, который не просто говорит «ссылка битая», а объясняет почему: OCR сломал DOI, год не совпадает с каталогом, или источника действительно нет ни в одной базе. Для авторов Дзена, которые ссылаются на исследования, это способ не оказаться в одном ряду с нейросетью, которая уверенно цитирует то, чего не существует.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
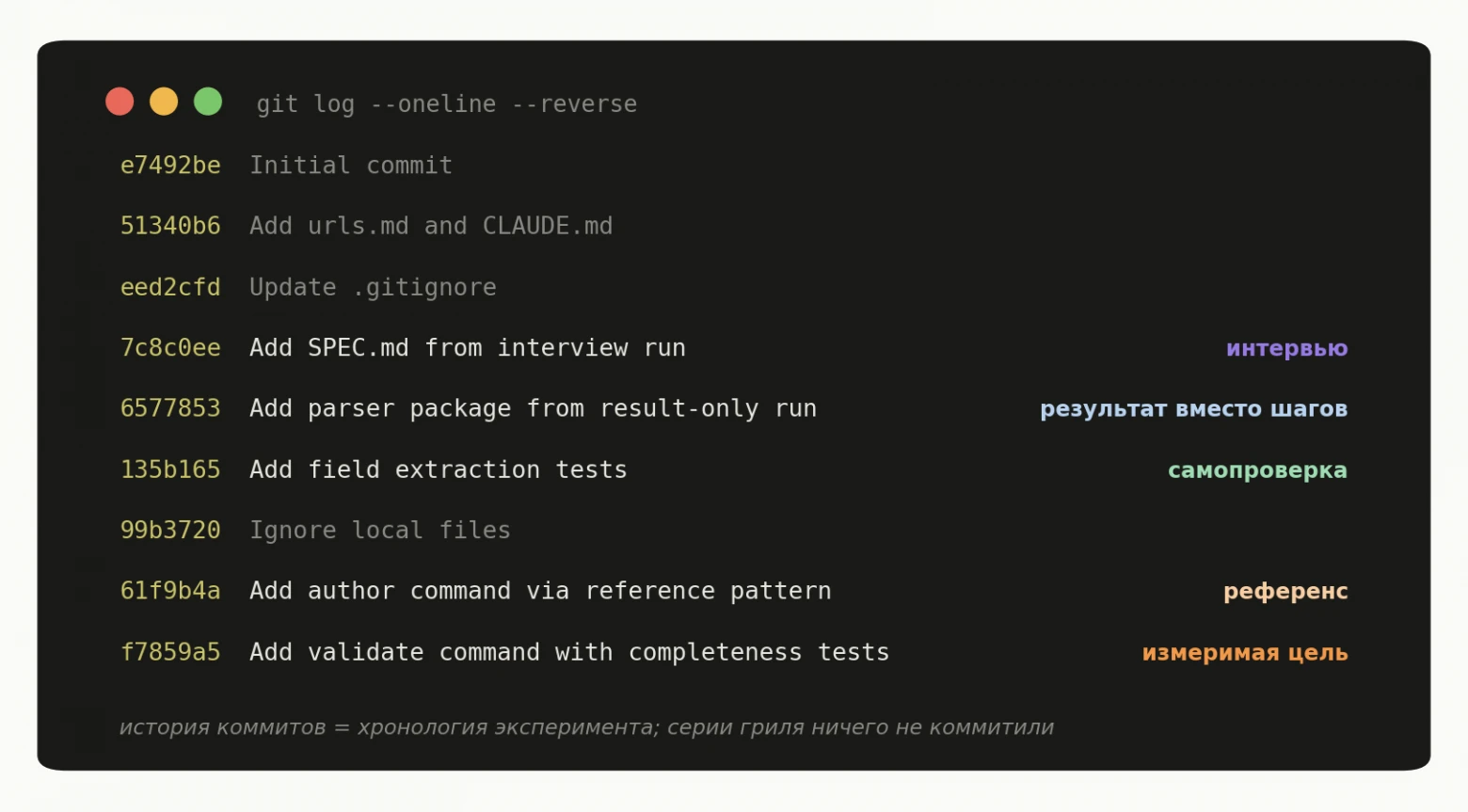
Промпты для нейросети от Anthropic: 4 паттерна, которые работают с любой моделью
Компания Anthropic открыла библиотеку промптов для Claude Code, и автор dzen.guru проверил пять паттернов из неё на живой задаче: парсинг собственных статей с…
Yttri 0.86 объединил ИИ-агента в одном окне и открыл публичный SDK для плагинов
Yttri 0.86 собрал ИИ-агента в одном окне, добавил плагин для Obsidian и локальный движок MLX для Mac, и всё это произошло в бета-версии, которая впервые…
Кибербезопасность и искусственный интеллект: урок цифры из трёх реальных сбоев с Claude
Материал представляет собой личный блог-пост (на русском языке) с тремя историями о сбоях при делегировании задач ИИ-ассистенту Claude. Автор описывает…
Комментарии