Бенчмарк inference runtime для ResNet-50: TensorRT ускоряет инференс в 5,8 раза
Когда модель уже обучена, скорость её работы на конкретном железе решает всё: укладываетесь в бюджет задержки или нет, хватит ли одной видеокарты или придётся масштабировать кластер, пишет Дмитрий Валетов в открытом бенчмарке на GitHub, опубликованном в июне 2025 года.
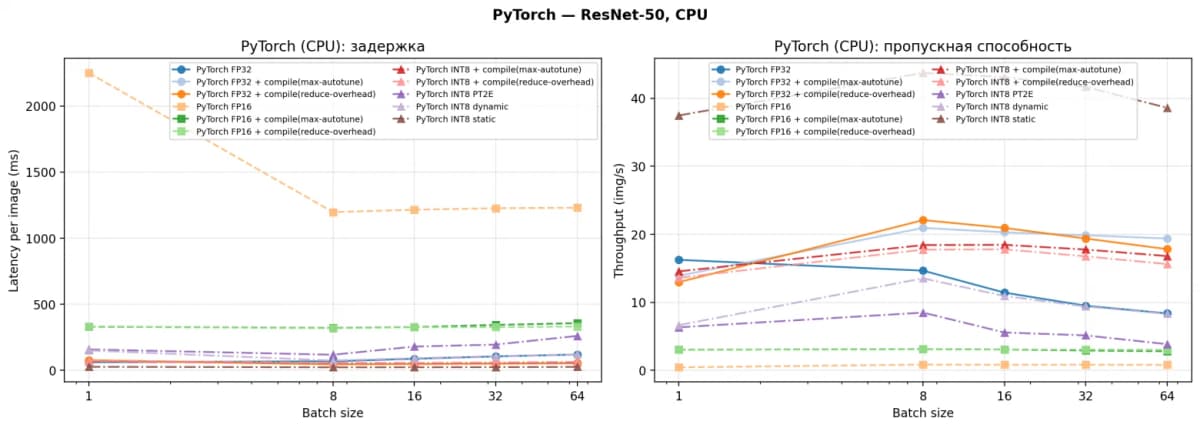
Бенчмарк проведён на доступном в России железе (Ryzen 9 6900HS, RTX 3070 Ti Laptop) и охватывает 46 конфигураций пяти движков: разница между базовым PyTorch и лучшим инференс-рантаймом (inference runtime) достигает четырёхкратного ускорения на процессоре и почти шестикратного на видеокарте.
Инференс-рантайм (inference runtime) это движок, который берёт уже обученную нейросеть и прогоняет через неё данные максимально быстро: без обучения, только предсказания. PyTorch, ONNX Runtime, OpenVINO, TensorRT, TVM отличаются тем, какие оптимизации применяют и на каком железе работают лучше. Автор бенчмарка Дмитрий Валетов прогнал классическую модель ResNet-50 через все пять движков в режимах FP32, FP16, INT8 и INT4 (это разные уровни точности вычислений: чем ниже, тем быстрее, но потенциально менее точно) и выложил код и данные в открытый доступ на GitHub.
Результат позволяет выбрать стек для деплоя моделей, не тратя дни на собственные замеры.
Что понадобится
- Ноутбук или десктоп с процессором AMD Ryzen 9 (или аналогичным по классу) и видеокартой NVIDIA RTX 3070 Ti или выше
- Установленные Python 3.10+, PyTorch, ONNX Runtime, OpenVINO, TensorRT, Apache TVM
- Клон репозитория:
github.com/DmitriyValetov/resnet50-inference-benchmark - Набор изображений для калибровки (те же картинки, что в репозитории, подмножество ImageNet)
- Около двух-трёх часов на полный прогон всех 46 конфигураций
Пошаговая инструкция
- Клонируйте репозиторий и установите зависимости.
git clone https://github.com/DmitriyValetov/resnet50-inference-benchmark.git
cd resnet50-inference-benchmark
pip install -r requirements.txt
-
Запустите базовый бейзлайн на PyTorch. Это отправная точка: обычный инференс (инференс, прогон модели без обучения) в режиме FP32 eager. Запомните задержку и пропускную способность. На CPU Ryzen 9 бейзлайн даёт примерно 61,6 мс на изображение, на GPU примерно 6,7 мс.
-
Попробуйте
torch.compileс FP16. Это самый простой способ ускориться без смены движка. По данным бенчмарка,torch.compileв связке с FP16 даёт ускорение в 2,6 раза относительно бейзлайна на GPU. Код менять почти не нужно. -
Экспортируйте модель из PyTorch в ONNX (opset 17). Этот формат понимают ONNX Runtime, OpenVINO и TensorRT.
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True).eval()
dummy = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy, "resnet50.onnx", opset_version=17)
-
Прогоните инференс через ONNX Runtime на CPU. Для статической INT8-квантизации (когда веса и активации сжимаются до 8-битных целых чисел) используйте модуль
onnxruntime.quantization. Результат по бенчмарку: 15,4 мс на изображение, 64,8 кадров в секунду, ускорение в 4,0 раза относительно PyTorch-бейзлайна при batch size 1. -
Сконвертируйте ONNX в OpenVINO IR. Используйте
openvino.convert_modelс параметромcompress_to_fp16=Trueдля FP16, а для INT8 выполните статическую калибровку (PTQ, post-training quantization, квантизация без дообучения). На CPU при batch size 1 INT8-режим OpenVINO показал 18,1 мс, ускорение в 3,4 раза. Обратите внимание: OpenVINO заточен под Intel, но и на AMD Ryzen результат достойный. -
Соберите TensorRT engine для GPU. Распарсите ONNX в TensorRT, задайте оптимизационный профиль (min=1, max=64), включите расширенные tactic sources и уровень оптимизации 5. Для INT8 используйте entropy-калибровку на тех же изображениях с FP16-fallback (откат на FP16 для слоёв, не поддерживающих INT8). Результат: 1,16 мс на изображение, 863 кадра в секунду, ускорение в 5,8 раза при batch size 1, это абсолютный рекорд бенчмарка.
-
TVM: компилируйте, но не ждите чудес. Загрузите ONNX в Relay, скомпилируйте под llvm (CPU) или cuda (GPU). Для каждого batch size нужна отдельная компиляция. По данным бенчмарка, лучшие конфигурации TVM вышли на уровень обычного eager-режима PyTorch, заметного ускорения добиться не удалось.
-
Сравните Top-1 accuracy. Квантизация ускоряет, но может ронять точность. В бенчмарке точность измерена на подмножестве ImageNet. Проверьте, что для вашей задачи падение приемлемо.
Итоговая таблица: кто быстрее?
| Движок | Режим | Устройство | Задержка (мс/изображение) | Ускорение к бейзлайну |
|---|---|---|---|---|
| PyTorch FP32 eager | FP32 | CPU | 61,6 | ×1,0 |
| ONNX Runtime static INT8 | INT8 | CPU | 15,4 | ×4,0 |
| OpenVINO INT8 | INT8 | CPU | 18,1 | ×3,4 |
| PyTorch FP32 eager | FP32 | GPU | 6,7 | ×1,0 |
| torch.compile + FP16 | FP16 | GPU | ~2,6 | ×2,6 |
| TensorRT INT8 | INT8 | GPU | 1,16 | ×5,8 |
| TensorRT INT8 bs=64 | INT8 | GPU | — | ×8,2 |
Все числа из оригинального бенчмарка Дмитрия Валетова.
На CPU Ryzen 9 6900HS: переход с PyTorch eager FP32 (61,6 мс) на ONNX Runtime static INT8 (15,4 мс) сокращает задержку вчетверо. Если у вас сервис классификации изображений и каждый запрос обрабатывается на процессоре, вместо 16 кадров в секунду вы получаете почти 65. На GPU RTX 3070 Ti: TensorRT INT8 выжимает 863 кадра в секунду при batch size 1. При batch size 64 ускорение доходит до 8,2 раза. Для потоковой обработки видео или массовой валидации датасета это разница между «одна карточка справляется» и «нужен кластер».
Забыть про калибровку при INT8. Статическая квантизация требует прогона калибровочных изображений. Без калибровки модель может выдавать мусор вместо предсказаний.
Ожидать от OpenVINO чудес на AMD. Фреймворк оптимизирован под Intel. На Ryzen он работает и даёт ускорение в 3,4 раза, но ONNX Runtime на том же процессоре быстрее (×4,0). Не стоит тратить время на тонкую настройку OpenVINO, если у вас AMD.
Верить, что TVM автоматически быстрее. TVM требует ручного тюнинга под конкретное железо. В этом бенчмарке автору не удалось выжать из TVM больше, чем даёт обычный PyTorch. FP16 на CPU и INT8 даже не удалось оценить из-за огромного времени компиляции.
Игнорировать torch.compile. Если менять инференс-рантайм пока не готовы, одна строчка torch.compile с FP16 на GPU даёт ×2,6 ускорения. Это минимальное вмешательство с ощутимым результатом.
Не проверять accuracy после квантизации. Ускорение бессмысленно, если модель начинает ошибаться. Всегда замеряйте Top-1 на вашем тестовом наборе.
Что делать с этим по ролям?
Автору Дзена и контент-мейкеру. Если вы используете нейросети для обработки изображений (классификация обложек, модерация фото), смена рантайма с PyTorch на ONNX Runtime ускорит пайплайн вчетверо даже без видеокарты. Это значит, что локальная обработка на обычном ноутбуке становится реалистичной.
Маркетологу и продакт-менеджеру. Выбор инференс-рантайма напрямую влияет на стоимость инфраструктуры. Шестикратное ускорение на GPU означает, что одна видеокарта выполняет работу шести. При аренде серверов в российских дата-центрах (Selectel, Yandex Cloud) это сотни тысяч рублей экономии в месяц.
Предпринимателю в РФ и СНГ. Бенчмарк сделан на железе, которое можно купить в России. Ryzen 9 и RTX 3070 Ti доступны на маркетплейсах. ONNX Runtime, OpenVINO и TensorRT бесплатны. Весь код открыт. Можно повторить замеры на своём оборудовании и принять решение до покупки серверов.
Этот бенчмарк ценен не рекордами, а практичностью. Железо реальное, код открытый, конфигурации можно воспроизвести за пару часов. По моим наблюдениям, большинство команд в РФ до сих пор гоняют инференс на голом PyTorch просто потому, что «работает и ладно». Между тем переход на ONNX Runtime на CPU или TensorRT на GPU не требует переписывания модели: экспортируете в ONNX и подключаете другой рантайм. Честная оговорка: ResNet-50 это классика, а не трансформер. Для моделей другой архитектуры (LLM, диффузионные модели) соотношение рантаймов может отличаться. Но как отправная точка для выбора стека этот бенчмарк экономит дни проб.
Генератор промптов dzen.guru
Подберите оптимальный промпт для работы с нейросетями, от классификации изображений до генерации текста.
Попробовать бесплатноЕсли вы до сих пор запускаете модели через model(x) в PyTorch и ждёте результата, попробуйте одну строку torch.compile с FP16 на GPU: ×2,6 ускорения за минуту работы, а дальше решите, стоит ли переходить на TensorRT и забирать все ×5,8.

Основатель dzen.guru. Эксперт по монетизации и продвижению на Дзен. Автор курса «Старт на Дзен 2026».
Читайте также
6 ошибок архитектуры AI агентов, которые ломают продакшен на длинных цепочках
повторные вызовы с одними и теми же аргументами учащаются. На длинных цепочках качество решений деградирует заметно. Причина. Контекстное окно модели — это…
ИИ-агенты: это рынок на триллион, и OKX строит для них «биржу фриланса»
Почему это важно Криптобиржа с аудиторией более 150 млн пользователей открыла маркетплейс, где ИИ-агенты сами находят друг друга, платят за услуги…

Интерфейс мозг‑компьютер: это 61% точности без имплантов в новом декодере Meta
Meta второго июня представила Brain2Qwerty v2, систему, которая читает текст прямо из активности мозга по магнитным сигналам, без имплантов, без хирургии и без…
Комментарии